Internet: come funziona
Premessa
Questa "lezione zero" contiene alcune informazioni tecniche su cos'è e come funziona Internet. Potreste pensare che non occorra conoscerle per usare la Rete, visto che, ad esempio, non occorre essere esperti di telecomunicazioni per usare il telefono. In realtà, vale la pena di fare un piccolo sforzo: Internet è ben più difficile da usare del telefono e senza queste conoscenze non andreste molto lontano.
ATTENZIONE: nel corso della lezione vi verrà talvolta consigliato di "fare clic" su un certo indirizzo, come http://www.ilweb.web (non fatelo ora, questo NON funziona). Posizionate il mouse su quell’indirizzo e premete il pulsante sinistro del mouse per dare un’occhiata.
Per tornare indietro: se usate Windows95 e Internet Explorer, fate clic sul pulsante Internet Mail alla base dello schermo. Se usate Netscape, scegli l’opzione Finestra e poi Posta Netscape sulla barra dei menu nella parte superiore dello schermo.
Le basi
Cominciamo proprio dall'inizio, con una breve descrizione dei servizi telematici (i BBS ) e delle reti di computer. Un BBS ovvero Bulletin Board System cioè, letteralmente, bacheca elettronica, è un programma speciale che risiede su un certo computer e consente che altri computer si colleghino a lui via telefono. Per usare il servizio telematico, l'utente deve installare nel suo computer un dispositivo di comunicazione, detto modem, e collegare il modem alla linea telefonica. Poi, userà un programma di comunicazione per connettersi al BBS. Potrà così sfruttare i servizi offerti dal BBS, che variano ovviamente di caso in caso.
Alcuni BBS consentono leggere i messaggi lasciati dagli altri utenti che hanno utilizzato il servizio in precedenza, di rispondere a questi messaggi o lasciare il proprio, o anche di riprodurre i file memorizzati sul disco del BBS. Altri forniscono servizi di tipo diverso; ad esempio consentono di giocare in linea con un altro utente di BBS a scacchi o ad altri giochi; conversare con un altro utente, cioè scrivere quello che si vuole dire alla tastiera e leggere sullo schermo la risposta quasi istantanea dell'altro utente. Nel caso dei servizi telematici specializzati si può cercare un dato in un archivio, (ad esempio, le Pagine Gialle Elettroniche, oppure il registro dei protesti cambiari), piazzare un ordine di vendita o di acquisto di beni o servizi, e nel caso dei BBS più evoluti persino vedere fotografie o carte meteorologiche memorizzate sul computer remoto. I servizi telematici di tipo economico-finanziario e le Reti Civiche spesso evitano accuratamente di definirsi con il termine BBS, che considerano poco serio, ma il principio è lo stesso. Si tratta sempre di computer o gruppi di computer ai quali gli utenti possono collegarsi via telefono per comunicare con altri, trovare file, giocare, fare ricerche, e così via.
Ciò che Internet NON è
Internet non è un BBS e neppure un servizio telematico. Internet è una rete di reti. Una rete di computer è costituita da un gruppo di computer collegati che possono comunicare tra loro. Questi computer interconnessi possono mandarsi messaggi e condividere le informazioni memorizzate sui loro dischi.
Internet collega più di 20.000 di queste reti, e il loro numero è sempre in aumento. Su queste reti ci sono milioni di computer, di terminali e di utenti; secondo alcune stime si tratta di circa due milioni di computer e circa 30 milioni di utenti. Non c'è niente di strano o tecnicamente avanzatissimo nelle reti di computer; sono una tecnologia ormai molto diffusa. Si può possedere una rete a livello privato, averne due o tre come certe piccole società o addirittura possederne migliaia come alcune grandi organizzazioni. Ma Internet non è una rete: è una rete di reti. Molte reti diverse sono state unite per produrre il più numeroso gruppo di computer collegati tra loro del mondo. Alcune di queste reti appartengono a governi, altre a Università, a imprese, a biblioteche e addirittura a scuole. La maggior parte sono negli Stati Uniti, ma parecchie si trovano in Europa (Italia compresa) e alcune si trovano oltreoceano, dall'Australia allo Zimbabwe.
Per saperne di più sulla storia di Internet, fate clic su:
|
|
Naturalmente Internet ha funzioni ben più importanti del fare comunicare gli utenti di Paesi diversi attraverso una specie di posta elettronica. Ciò che rende speciale Internet è che molti computer di ogni rete collegata agiscono come gestori di archivi. In altre parole, quando ci si collega ad Internet si ha l'opportunità di accedere a migliaia di sistemi differenti, che gestiscono archivi comunali, database universitari, cataloghi di biblioteche, messaggi di qualsiasi tipo e milioni di file, contenenti fotografie, documenti, video musicali e qualsiasi altra cosa possa essere messa in forma digitale.
Ad esempio, basta fare clic su:
L'analogia migliore che si può utilizzare per descrivere Internet è probabilmente quella con la normale rete telefonica. Il sistema telefonico mondiale ha molti commutatori, le centrali, possedute da diverse organizzazioni, tutte collegate tra loro. Quando un utente di Milano tenta di chiamarne uno di New York, non ha bisogno di sapere quali città o quali Stati la chiamata attraverserà; è il sistema telefonico che fa tutto per lui. Le società telefoniche hanno stabilito tra loro i meccanismi di questo processo e non è necessario che l'utente sappia cosa succede. Internet funziona nello stesso modo; così come non c'è un'unica società telefonica al mondo, non c'è una singola società Internet. Nessuno possiede Internet, così come nessuno possiede la rete telefonica mondiale. Certo, ogni singola componente è posseduta da qualcuno, ma la grande Rete non è posseduta da nessuno: è un sistema che continua a funzionare grazie all'interesse comune di tutti coloro che ne fanno parte. Nel caso del telefono, le compagnie telefoniche di tutto il mondo si incontrano periodicamente e concordano qual'è il sistema di funzionamento migliore nonché i costi e i dettagli tecnici per collegare un paese all'altro. Lo stesso accade per Internet.
Perché usare Internet
Ci sono centinaia di milioni di buone ragioni per usare Internet: tutte le persone che hanno già scelto di usare la Rete e con le quali ci si potrà collegare. Naturalmente non sono tutti utenti attivi; la maggior parte della gente potenzialmente collegata raramente usa altri computer oltre a quelli della propria organizzazione e non ha idea di quello che c'è su Internet. Le potenzialità tecniche e commerciali di questa platea sono comunque enormi. Inoltre, questo numero è puramente indicativo; in realtà nessuno sa con sicurezza quante persone possano essere realmente raggiunte dalla rete. Ma c'è una ragione anche migliore per usare Internet: l'informazione che contiene. Opere letterarie, report finanziari, ricette di cucina macrobiotica, presentazioni multimediali, per arrivare fino ai più recenti programmi per la realtà virtuale: su Internet c'è tutto quello che si può desiderare, ed è in gran parte gratis! Disporre dell'informazione adeguata in tempo utile può essere addirittura vitale per un'azienda, ma ha un valore notevole anche per l'individuo. Basta conoscere l'inglese (e avere seguito questo corso!) per poter scrivere annunci, entrare in contatto con persone che condividono i propri interessi, consultare i libri e le riviste contenuti nelle biblioteche che usano Internet, trovare i programmi adeguati alle proprie esigenze e così via.
Come collegarsi ?
Se siete già oppure pensate di entrare in Rete vuol dire che qualcuno ha provveduto o provvederà a creare tra la vostra macchina e il resto di Internet qualche tipo di collegamento. Le aziende che forniscono questo servizio si chiamano Internet service provider, nel seguito semplicemente provider o ISP. Un elenco completo degli Internet provider italiani si trova... su Internet, all’indirizzo
E’ un po’ come mettere l’elenco dei concessionari auto in un posto raggiungibile solo in macchina, ma per consultarlo si può sempre ricorrere a un amico già collegato. Ci sono due modi principali per collegarsi a Internet, ciascuno dei quali ha una serie di varianti:
* Collegamenti permanenti
* Collegamenti in linea commutata
Non sempre i tecnici e gli esperti di reti usano questi termini in modo coerente; le considerazioni che seguono hanno il compito di chiarire il loro significato ed evitare confusioni.
Collegamenti permanenti
Un collegamento permanente significa che il proprio computer (o, più spesso, la rete locale di cui fa parte) è collegato direttamente a una rete di tipoTCP/IP che è parte di Internet. Solitamente sono i computer di proprietà delle grandi organizzazioni (aziende, Enti, Università) ad essere collegati a Internet in questo modo; i privati, invece, si limitano a collegare temporaneamente via telefono il proprio personal a un computer che a sua volta è collegato permanentemente alla rete. La sigla TCP/IP significa Transmission Control Protocol/Internet Protocol, ovvero Protocollo di controllo di trasmissione/protocollo di Internet.
Un protocollo è l'insieme di regole che definisce come un computer deve parlare all'altro; i prossimi paragrafi tratteranno meglio questo argomento. Per ora basti sapere che qualunque sia il tipo di rete utilizzato all'interno della propria organizzazione, per collegarsi permanentemente a Internet bisogna che il proprio computer parli, almeno verso l'esterno, il linguaggio TCP/IP.
Come creare un collegamento permanente
Se si è il responsabile di un'azienda che dispone di una propria rete e si desidera connetterla permanentemente a Internet, la prima cosa da fare è prendere contatto con un provider che sarà anche il punto fisico di connessione alla rete globale.
Fate clic qui per dare un’occhiata ad uno dei più veloci ed affidabili provider in Italia:
|
|

Poi, bisogna collegare sulla propria rete un apparecchio detto router che farà da interprete, parlando in TCP/IP con il computer del provider e nel protocollo opportuno (lo stesso TCP/IP, o comunque quello usato dalla rete aziendale) con le macchine dell'azienda. Infine, occorre affittare da Telecom o da altri una linea telefonica dedicata che colleghi il router installato in azienda al computer del provider. I dettagli variano a seconda dei casi: il provider può procurare lui stesso il router oppure suggerire all'organizzazione cliente quale comprare. Poiché la linea telefonica è dedicata, è sempre attiva. Non c'è bisogno di telefonare ogni volta per raggiungere il computer del provider; ogni utente dell'organizzazione cliente potrà collegarsi a Internet direttamente dal proprio solito posto di lavoro. Una volta collegato, potrà trasferire i file dal proprio computer agli altri computer di tutto il mono che sono collegati a Internet e viceversa. Naturalmente, questo tipo di servizio è molto caro: al costo del servizio di connessione e del router, infatti, va aggiunto quello non indifferente del noleggio della linea Telecom.
Se siete già collegati alla Rete attraverso una rete aziendale o scolastica, il vostro personal computer farà già probabilmente parte di una rete locale (local area network, LAN). Invece di un modem, il vostro personal avrà una scheda di rete che lo collega alla rete locale; il cavo che esce dalla scheda può assomigliare al cavo telefonico o al cavo coassiale usato per l'antenna della televisione. Se usate Internet dalla rete dell'ufficio o della scuola, è sicuro che anche la vostra rete è connessa a un provider; è però probabile che il collegamento non avvenga tramite un modem, ma attraverso una linea permanente a velocità maggiore (tipicamente, da 64 kbps a 2 Mbps) affittata annualmente dalla società telefonica.
Collegamenti su linea commutata
Gli utenti che si collegano a Internet da casa arrivano a un provider usando un modem che funziona sui fili telefonici normali. Presso la sede del provider vi è un altro modem convenzionale; può essere un modello industriale, oppure, se il provider vuol risparmiare, può essere come il vostro. La velocità di connessione è quella del più lento tra i due modem (nel migliore dei casi e non considerando fattori come il rumore) e va dai 2,4 kilobit al secondo (kbps) a 33,6 kbps. Un collegamento di questo tipo, detto in linea commutata è un collegamento che usa il protocollo SLIP (Serial Line Internet Protocol, protocollo Internet su linea seriale), CSLIP (Compressed SLIP, SLIP compresso), o PPP (Point-to-Point Protocol, protocollo punto-punto) per collegarsi a un Internet provider attraverso una normale linea telefonica e un modem.
´Connessione PPP’ significa che, telefonando al computer del provider, il vostro computer riceverà un suo numero identificativo (l’indirizzo IP) che lo renderà visibile su Internet per tutta la durata della chiamata. Tramite appositi programmi, vi sarà così possibile consultare informazioni sugli altri computer di Internet. ‘Linea commutata’ vuol dire che il collegamento usa la normale rete telefonica, il che in genere limita la velocità massima (che dipende dal tipo di modem) a 28,8 kbps. Anche questi sono collegamenti di tipo TCP/IP, come il collegamento permanente, ma sono destinati ad essere usati sulle usuali linee telefoniche, anziché su una linea dedicata. Naturalmente c'è una certa differenza in fatto di prestazioni: i trasferimenti di dati tra il computer dell'utente e gli altri saranno sensibilmente più lenti. l modem è in grado di chiamare il numero telefonico che viene comunicato dal provider. La telefonata avviene sulle linee telefoniche Telecom, le stesse che portano la voce; le tariffe applicate sono quindi quelle usuali per le conversazioni telefoniche. In alternativa, ci sono i collegamenti ISDN (Integrated System Digital Network). Quasi tutti i provider italiani offrono oltre alla ´connessione PPP in linea commutata’ anche la ´connessione PPP via ISDN’. Per per usarla dovete prima chiedere a Telecom di trasformare in ISDN la vostra presa telefonica, per un costo di circa duecentomila lire. Poi le tariffe sono di poco superiori a quelle delle chiamate tradizionali anche se la velocità.. è tutta un’altra musica. Per ora, la velocità di connessione ISDN è di 64 kbps, ma può arrivare a 128 kbps, cioè circa cinque volte più veloce di un modem tradizionale. Infine, va osservato che le connessioni PPP si possono fare anche affittando da Telecom delle linee dedicate, riservate cioè alla connessione tra utente e provider. Ma anche le più economiche hanno costi di molti milioni all’anno e sono rivolte all’utenza aziendale.
Comunque, indipendentemente dal tipo di linea, una volta composto il numero ed effettuato il collegamento con il computer del fornitore non ci sarà più alcuna differenza tra il collegamento PPP e un collegamento dedicato; si potranno, cioè, trasferire dei dati dal proprio computer a qualsiasi altro connesso alla rete Internet e viceversa.
Vantaggi e svantaggi dei vari tipi di collegamento
Il collegamento permanente è caro, ma può essere considerato un buon investimento per le grosse società. Una volta collegati, infatti, si possono avere tanti utenti quanti sono i computer della società e la linea dedicata conviene, poiché non c'è alcun addebito legato al numero degli utenti individuali. Se ci sono molti utenti, il collegamento permanente di tutta l’azienda può risultare più economico rispetto alla scelta di fornire ad alcuni utenti VIP un proprio collegamento autonomo, specialmente se la maggior parte degli utenti "normali" usa Internet con bassa frequenza o per solo pochi minuti al giorno. Comunque, la connessione permanente resta una soluzione per pochi: i servizi specializzati sono molto cari. Il collegamento in linea commutata via modem, sebbene inferiore a quello permanente, è molto più economico. E' necessario però disporre di un modem ad alta velocità (almeno 28.800 bit al secondo) e a correzione di errore. Comunque, chi si collega da casa può stare tranquillo: ci sono nuove tecnologie che consentono agli utenti domestici di accedere a Internet a velocità superiore. Una possibilità è il servizio ISDN (Integrated Services Digital Network), che usa il collegamento telefonico esistente, ma sostituisce i modem con speciali adattatori digitali.
ISDN è già oggi una buona scelta: è accettato da un numero crescente di provider, è sicuro e non troppo costoso, sebbene costi un po’ più del normale servizio telefonico. Un altro servizio che permette collegamenti superveloci a Internet lungo le normali linee telefoniche è ADSL (Asymmetric Digital Subscriber Line, Linea digitale asimmetrica). Questo servizio non è ancora disponibile in Europa, ma prevede connessioni a velocità fino a 6 Mbps "a favore di corrente" (da Internet al vostro computer) e 640 kbps "contro corrente" (viceversa). Sebbene sia ancora lontana dall'essere onnipresente, ISDN è disponibile in Italia fin dagli anni '80 ed è la più diffusa tra le tecnologie di connessione digitale per l’utenza privata. Le reti cellulari e i sistemi di invio via satellite sono in fase di sperimentazione per il trasporto Internet; quest’ultima secondo molti esperti sarà la tecnologia del futuro.
Ma la rassegna delle tecnologie non è finita qui: l'accesso a Internet attraverso la connessione televisiva via cavo è uno strumento nuovissimo per cui si prevede un grande futuro, anche se non in Italia, dove la rete televisiva via cavo è praticamente inesistente. I sistemi di accesso a Internet tramite la rete della TV via cavo prevedono velocità di 500 kbps a 30 Mbps. Lo stesso cavo che porta il segnale della televisione viene usato per Internet: il servizio verrà fornito dalle stazioni televisive via cavo, che dovranno diventare provider.
Ad un singolo individuo, comunque, non conviene mai acquistare un collegamento permanente. Esso richiede router, linee dedicate e altri dispositivi molto costosi. Anche le spese iniziali e le tariffe annuali sono molto elevate. Se si vuole un servizio diretto in linea, basta invece pagare una (ragionevole) tariffa iniziale di collegamento. Poi si paga in proporzione all’utilizzo, secondo una tariffa oraria che è diversa durante il giorno e da mezzanotte alle otto del mattino. C'è molta varietà nelle tariffe e nelle modalità di pagamento, quindi conviene contattare il maggior numero possibile di provider. Questo corso descrive in dettaglio gli strumenti di consultazione: bisogna verificare che il provider li metta effettivamente a disposizione.
Le arterie di Internet
Le arterie di Internet sono le linee dorsali , che sono gestite dai fornitori di Internet "all'ingrosso", i cosiddetti National Service Provider o NSP. Gli utenti si collegano agli ISP locali attraverso i modem, gli adattatori ISDN o altri strumenti, mentre gli ISP locali si connettono a loro volta alle reti di NSP come Interbusiness di Telecom, Unisource, Sprint o (nel caso degli utenti universitari) il Gruppo Autonomo Reti Ricerca o GARR. Alcuni NSP forniscono anche il servizio agli utenti finali, sebbene il loro principale interesse sia comunque la fornitura all'ingrosso. Gli ISP si collegano agli NSP attraverso linee dedicate affittate dalla Telecom. Le connessioni migliori sono le linee dette T1 a 2 Mbps; i provider più grossi possono avere connessioni T1 multiple. Al loro interno, gli NSP usano le loro reti private, composte anch'esse di linee dedicate affittate ricorrendo a Telecom Italia per il tratto in territorio italiano e ad altre società per i tratti internazionali (in Europa, British, France e Deutsche Telecom; in America WilTel, MCI e Sprint). Queste ultime società sono proprietarie dei cavi in rame e fibra ottica e delle connessioni via satellite attraverso cui corrono insieme le normali conversazioni telefoniche e il traffico Internet. Le reti degli NSP di solito funzionano a velocità T1 localmente, ma arrivano a velocità superiori per le lunghe distanze. Le connessioni T3 e con gli Stati Uniti corrono a 44,736 Mbps. In America le cose vanno ancora meglio: la rete su fibre ottiche (OC3) di MCI funziona a155,52 Mbps (5500 volte più veloce di un modem a 28,8 kbps). ed alcune linee superveloci viaggiano a più di 600 Mbps.
Le altre reti
Accanto a Internet, ma in modo indipendente, si sono diffuse varie reti telematiche di tipo amatoriale, particolarmente interessanti per chi segue le iniziative politiche, sociali e di volontariato.
La rete amatoriale per antonomasia è FidoNet, che conta più di 30.000 nodi sparsi in tutto il mondo. Vi sono anche altre reti realizzate con gli stessi criteri (generalmente chiamate FTN, Fidonet Technology Network), anche se limitate ad una sola nazione o ad un determinato scopo: ad esempio in Italia oltre a FidoNet ci sono Peacelink (dedicata al pacifismo e alle questioni sociali), RPGNet (dedicata ai giochi di ruolo), Cybernet (creata dal movimento "cyberpunk"), e così via. Le reti FTN sono generalmente strutturate ad albero, ossia ogni nodo ha un nodo "padre" (uplink) e dei nodi "figli" (downlink), fino ad arrivare ai nodi terminali. Ogni sistema che fa parte della rete effettua ad orari predefiniti delle chiamate notturne su linea telefonica commutata (in modo da diminuire al massimo i costi di trasferimento) al proprio uplink, e subito dopo si predispone per ricevere le chiamate dei propri downlink, che giungeranno anch'esse ad orari predefiniti. E’ ovvio che la spesa principale che ogni singolo responsabile di nodo (universalmente chiamato sysop) dovrà affrontare è quella della propria bolletta telefonica. In altri termini, se voi spedite un messaggio da una nodo Fidonet di Milano ad un utente che si trova a Roma, il costo del trasferimento del vostro messaggio verrà suddiviso tra tutti i nodi che si trovano nel "percorso" tra i due sistemi. Il lettore esperto avrà già notato che ci sono alcune affinità superficiali tra Internet e le reti in tecnologia FTN, ma la differenza è sostanziale: in FidoNet le comunicazioni avvengono tutte su linea commutata ed in modalità tipicamente "batch", ossia senza una connessione diretta e continua tra i sistemi; inoltre i sistemi FidoNet non sono gestiti da provider ma da appassionati senza fini di lucro. Un'altra differenza con Internet si può notare nell'instradamento dei messaggi: in FidoNet la topologia della rete è ad albero, come già detto, e per di più è fissa in quanto non sono previsti meccanismi automatici di instradamento alternativo in caso di indisponibilità di un nodo intermedio.
FidoNet e Internet.
Questi limiti tecnologici (soprattutto se si fa un confronto con Internet) sono largamente compensati da semplicità ed economicità di gestione; questo ha reso FidoNet la tecnologia di elezione per la creazione di reti in molti paesi del Terzo Mondo; grazie ai punti di interconnessione tra FidoNet e Internet molte Università e istituzioni africane riescono a scambiare messaggi di posta elettronica con il mondo Internet anche se i Paesi in cui si trovano non sono connessi alla Rete.
Primi rudimenti di TCP/IP
In definitiva, attraverso un provider e il NSP a cui si rivolge, il nostro computer di casa o dell'ufficio può essere collegato a milioni di altri computer. Ma come fanno i messaggi a trovare la strada da un computer a un altro?.Per creare un collegamento a Internet è necessario disporre sul proprio computer del software di rete TCP/IP. Con le passate versioni di Windows e Mac, si trattava di un programma da installare; in Windows 95 e Unix è incorporato. TCP/IP si basa su uno schema detto a commutazione di pacchetti. Questo significa che ogni file inviato su Internet, dai messaggi di posta elettronica al contenuto delle pagine Web, è suddiviso in parti più piccole chiamate pacchetti, seguendo le regole (cioè, il protocollo) IP. Ogni pacchetto è etichettato, includendo anche l'indirizzo numerico di destinazione, detto indirizzo IP; l'indirizzo IP è formato dall'host number (che individua la macchina a cui va mandato il pacchetto) e un numero aggiuntivo, il port number, che identifica il programma ricevente tra quelli in esecuzione su quella macchina.
Gli host e port number IP
Non c'è alternativa : se si effettua un collegamento a Internet (che sia in linea commutata o meno), si ha bisogno di un host number. Questo numero è come il numero della carta d'identità, e serve per identificare univocamente ogni computer connesso alla rete Internet. Infatti, anche con il collegamento in linea commutata, il computer dell'utente sarà registrato come un computer Internet a tutti gli effetti . Quindi dovrà avere un numero identificativo completo e autonomo, anche se tutte le comunicazioni con la rete passeranno dalla macchina dell'utente a quella del fornitore di servizi e viceversa. Per esempio, un host number italiano valido è 145.94.50.236. I singoli programmi in esecuzione su questa macchina saranno identificati da un altro numero, il port number, in modo che il computer sappia distinguere i pacchetti diretti a ciascuno di essi. I programmi che forniscono i servizi più noti hanno numeri di port standard, i cosiddetti well-known port. Su questo argomento torneremo brevemente nel prossimo tutorial. Se il collegamento è permanente, l’host number è attribuito una volta per tutte; altrimenti, il software TCP/IP otterrà questo numero dal computer del provider ogni volta che l'utente si collega con Internet, ricordandogli la propria esistenza. I computer speciali che collegano le varie parti della Rete e instradano i pacchetti nelle diverse zone sono chiamati router . Le connessioni tra i router possono essere pubbliche (ovvero, le linee telefoniche) o private, cioè collegamenti via cavo tra i computer di una stessa società o di un campus universitario. Del loro funzionamento ci occuperemo tra poco.
I nomi di computer e di dominio
Anche se per identificarsi tra loro usano i numeri, i computer connessi a Internet vengono individuati dagli utenti umani tramite nomi. Il nome di un singolo computer viene spesso chiamato il suo nome di computer. Chi ottiene un collegamento Internet gratuito non ha molta scelta sul nome di computer: se l'utente ha accesso tramite una società o un'Università, il nome del suo computer gli verrà semplicemente comunicato dal responsabile. Ma chi acquista l'accesso da un fornitore di servizi, e sceglie il collegamento permanente, ha la facoltà di scegliere il nome del proprio computer. In certi casi, invece di usare il nome di computer del computer del provider, potrà deciderne uno proprio. Il nome di computer non è equivalente all'host number, poiché non basta a identificare univocamente una macchina; per questo il sistema assegna a ogni calcolatore anche un dominio .
Il nome di dominio serve per identificare un intero gruppo di computer collegati a Internet. I domini più grandi sono quelli corrispondenti a intere nazioni; il dominio italiano, ad esempio, si chiama it; quello tedesco de, mentre francesi e inglesi hanno rispettivamente i domini fr e uk. Ovviamente, un dominio grande può comprenderne altri più piccoli. L'insieme dei computer dell'Università di Milano, per esempio, sta nel sottodominio unimi di it . Ma questo sottodominio ha a sua volta dei sottodomini; uno di essi è chiamato crema perché comprende le macchine del Polo Didattico di Crema. Il nome completo di quest'ultimo sottodominio, in realtà, è crema.unimi.it perché occorre elencare, oltre a quello corrente, anche tutti i livelli superiori. Il computer usato per inviare questo corso ha nome weblab e dunque il suo nome completo è weblab.crema.unimi.it. E’ a questo nome completo che corrisponde univocamente un host number, cioè 159.149.70.70. Ogni volta che si digita un nome, viene interpellato un apposito programma, il Domain Name System , per eseguirne la traduzione in numero.
Per quanto riguarda i nomi di dominio, gli Stati Uniti costituiscono un caso a parte, perché non esiste un dominio .us. La rete Internet negli Stati Uniti è tanto grande e complessa che sono stati definiti vari domini separati. Il più noto è edu: il gruppo nazionale delle istituzioni educative. La maggior parte delle Università e delle scuole americane fanno parte di questo dominio. Il dominio com comprende tutte le organizzazioni commerciali, mentre mil è quello delle installazioni militari (da solo, contiene centinaia di migliaia di computer). Detto questo, bisogna osservare che l'utente finale non deve quasi mai disporre di un proprio dominio. Questo è consigliabile solo alle grandi organizzazioni che vogliono connettere a Internet tutte le macchine della propria rete di calcolatori privata. Comunque, quando il fornitore assegna all'utente un nome di dominio, deve registrarlo presso l'InterNIC (Inter Network Information Center, Centro di Informazione Reti), o meglio presso l'Ente delegato a livello nazionale (in Italia, il GARR); un'operazione che richiede almeno una decina di giorni. Ciò assicura l'unicità del nome e la sua associazione ai numeri che identificano i computer usati dal richiedente.
I router: il cuore della Rete
I router sono macchine collegate a due o più reti, che hanno il compito di far passare i pacchetti da una rete all'altra in modo da avvicinarli alla loro destinazione (i pacchetti diretti a una macchina collegata alla stessa rete del mittente arrivano a destinazione senza bisogno dei router). Un tipico router può smistare 10.000 pacchetti al secondo; un router di alta qualità può avere una capacità teorica di 200.000 pacchetti al secondo. I router di Internet hanno un compito semplice: inoltrare i pacchetti che ricevono alla loro destinazione, passandoli da router a router. Per inoltrare i pacchetti fino all'ultima fermata si crea una catena di router, ognuno dei quali sa l'indirizzo del successivo sulla Rete grazie a tabelle costantemente aggiornate.
Ogni riga di queste tabelle è una coppia (porzione di) indirizzo del destinatario - indirizzo del router di inoltro.
Ad esempio la coppia
159.- 145.94.50.236
dice al router che la detiene che tutti i pacchetti il cui indirizzo comincia per 159 vanno mandati al collega router 145.94.50.236. Si noti che il router di inoltro deve trovarsi sulla stessa rete del mittente o su una delle reti a cui è collegato il router precedente, in modo che questi sappia raggiungerlo sulla base del suo indirizzo. Il router di inoltro poi provvederà a mandare i pacchetti al destinatario o a un altro router.... e così via. L’instradamento viene fatto pacchetto per pacchetto. Ricordiamo che quando si invia un messaggio di posta elettronica o una richiesta di connessione a un server Web, il messaggio viene diviso in pacchetti e trasmesso. In alcuni casi, i diversi pacchetti possono seguire percorsi differenti , perchè il computer d'inoltro nella tabella di un router può variare, ad esempio a seguito di cambiamenti del traffico; il messaggio viene ricomosto sulla macchina di destinazione.
Sembra difficile? La normale rete telefonica funziona circa nello stesso modo, tenendo conto che le centrali telefoniche usano i numeri telefonici invece degli indirizzi di rete. Ad esempio, 0039 è il prefisso telefonico per l'Italia , 02 è quello per Milano e 824 individua la zona metropolitana di sud-ovest. C'è però una differenza: quando si digita un numero telefonico in quella zona, la rete telefonica crea all'inizio della chiamata un circuito tra gli apparecchi dei due interlocutori e la conversazione fluisce tra i due punti. Al contrario, la rete IP può inviare indipendentemente ciascun pacchetto. Quindi, almeno in linea di principio, un dato pacchetto potrebbe non seguire lo stesso percorso su Internet di quello prima o di quello dopo. In questo modo, se una linea cade o un collegamento è troppo occupato, i router cooperano per trovare un percorso alternativo per inviare i dati. Questo processo è trasparente agli utenti, a parte l'attesa che impone loro. Ogni router su Internet deve essere quindi in grado di aiutare a instradare i pacchetti a uno dei milioni di computer dotati di indirizzi IP. Anche se il router è un vero e proprio computer (e molto sofisticato!), non è possibile che le sue tabelle contengano le informazioni d'inoltro per i milioni di computer presenti su Internet. Tutto quello che fanno i router è capire se un pacchetto IP deve essere inviato all'interno di una delle reti a cui sono essi stessi collegati. Se così non è, indirizzano il pacchetto a un altro router che forse ne sa di più. Per eseguire quest'operazione, i router si scambiano regolarmente i dati via Internet; del loro funzionamento ci occuperemo in dettaglio nel prossimo tutorial.
Se qualcosa va storto
In definitiva, lo scopo dei router è capire il miglior percorso per inviare i pacchetti da un computer all’altro. Quando cambiano le condizioni, a causa di un malfunzionamento o di una congestione delle linee, i router della Rete modificano quasi istantaneamente le loro tabelle di inoltro. Questa capacità autonoma di autoapprendimento fa sì che sulla Rete in cui l'instradamento effettivo di singolo pacchetto non sia noto a priori.
Questa adattabilità è una potenziale fonte di problemi. I router, infatti, si scambiano via Internet gli aggiornamenti per le loro tabelle, e ciò può dar luogo a un fenomeno chiamato flapping in cui una rete compare e scompare continuamente facendo sì che tutti i router del circondario si diano da fare per comunicarsi l'un l'altro che è scomparsa o riapparsa. Internet si difende da questo fenomeno attraverso un processo di "punizione" delle reti instabili diffondendo gli aggiornamenti alle tabelle d'instradamento tanto più lentamente quanto più la rete è instabile. I grandi provider possono anche rifiutarsi di collegarsi alle reti che causano dei problemi.
I server
Tutte le informazioni su Internet hanno origine all'interno dei server, che sono dei computer come gli altri, collegati in permanenza alla rete; l’unica differenza è che su di essi girano particolari programmi (detti anch’essi server) che hanno il ruolo di fornire i dati a chi li richiede. Qualsiasi computer direttamente connesso a Internet può fornire informazioni, assumendo così i panni del server. Storicamente, i server erano principalmente macchine con il sistema operativo Unix (di marca DEC, Hewlett-Packard, IBM, Silicon Graphics, Sun e altri), ma ora sono sempre più usati i sistemi Macintosh e Windows NT. Esistono anche molti server Web che sfruttano il sistema operativo gratuito Linux, disponibile anche su personal computer economici. I siti Internet più grandi girano su macchine Unix per sfruttare il loro sistema operativo evoluto e i processori più potenti. Ad esempio il server Alta Vista, di cui parleremo nei prossimi capitoli, gestisce giornalmente milioni di collegamenti e gira su un computer parallelo con quattro CPU e molti gigabyte di RAM. I server eseguono del software specializzato per ogni tipo di applicazione Internet, tra quelle che vedremo in seguito, il World Wide Web, Gopher, i gruppi di discussione delle news di Usenet e la posta elettronica. Ogni organizzazione presente su Internet deve poi ospitare il DNS (Domain Name System) per la traduzione dei nomi simbolici in indirizzi di rete di cui abbiamo parlato in precedenza. Il DNS consente agli utenti di specificare i nomi, invece di usare gli indirizzi IP numerici.
ESERCIZIO (5 PUNTI)
Inviate un messaggio di posta elettronica ai Tutors (tutor@corso.energy.it) per farci sapere che ci siete, indicando le vostre prime impressioni sul corso!!!
Tutorial 2
Dopo aver parlato di Internet in generale, in questa lezione approfondiamo il funzionamento delle reti.
I protocolli
I protocolli sono la parte più astratta di Internet. Essi sono gli standard che definiscono il modo in cui i computer comunicano l'un l'altro. Sebbene i protocolli esistano solo sulla carta, e quindi possano sembrare piuttosto astratti (a differenza di un router o di un server, non si può toccare un protocollo), sono essenziali per Internet, poiché consentono a milioni di macchine nel mondo di comunicare e scambiare dati. Infatti, prodotti diversi di differenti venditori sono in grado di comunicare perché si conformano agli stessi standard. Uno degli aspetti più interessanti di Internet, infatti, è che la comunicazione tra i componenti è garantita dal protocollo e non dalla marca del computer o del sistema operativo che si sta usando. Come si è detto, il protocollo TCP/IP è lo standard di comunicazione che tutti i computer collegati a Internet devono usare. Oltre a TCP/IP, vi sono i protocolli applicativi come
HTTP (Hypertext
Transport Protocol) per il World Wide Web,
NNTP (Network
News Transport Protocol) per Usenet,
SMTP (Simple Mail Transport Protocol) per la posta elettronica
di cui parleremo nel seguito del corso. Questi protocolli sono posti "sopra" TCP nel senso che definiscono come dev'essere fatto il contenuto dei pacchetti TCP a seconda della specifica applicazione. Tutti questi protocolli sono incorporati nel software del vostro computer, o meglio rispettati da chi lo scrive. Che si tratti di Netscape Navigator, di Microsoft Explorer o di Windows 95, chi ha scritto i programmi ha dovuto seguire le regole del protocollo in questione.
Come funzionano le reti
In questo paragrafo diamo qualche dettaglio su come colloquiano a distanza i calcolatori elettronici. A differenza del resto della lezione, queste informazioni non sono indispensabili per usare Internet a livello personale; ma chi si occupa della rete per conto di un’organizzazione, Ente o azienda che sia, farà bene a dare almeno una lettura ai paragrafi che seguono. Anche se l’analogia con il telefono fatta nel tutorial precedente ha chiarito un po’ le idee, infatti, non bisogna portare troppo avanti il paragone: la trasmissione dei dati su una rete di calcolatori presenta alcune importanti differenze rispetto a un’usuale comunicazione telefonica. Quando si inizia una conversazione telefonica, le apparecchiature di gestione della rete si incaricano di realizzare un collegamento elettrico "ad hoc" tra trasmittente e ricevente tramite un'opportuna commutazione elettromeccanica degli interruttori delle centrali di smistamento. Una volta, come si vede nei vecchi film di Hollywood, questa funzione era svolta da operatori umani che realizzavano manualmente la commutazione inserendo uno spinotto nella sede opportuna.
In seguito, per questo scopo vennero realizzati commutatori elettromeccanici e, più recentemente, commutatori elettronici. Comunque, il colloquio telefonico è basato sull'esistenza di un cammino che collega elettricamente trasmittente e ricevente. Tale cammino elettrico viene realizzato per ogni singola chiamata telefonica e cessa di esistere al termine della conversazione. Questo metodo di collegamento, chiamato commutazione di circuito (circuit switching), è caratterizzato dall'elevato tempo di attesa che risulta necessario per la realizzazione della connessione, una caratteristica che lo rende poco adatto alle reti di calcolatori. D'altro canto, una volta che la connessione è stabilita, la comunicazione può aver luogo alla massima velocità di trasmissione consentita dalla linea, senza problemi di traffico.
La tecnica più largamente usata nelle reti di trasmissione dati come Internet è invece è quella detta a commutazione di pacchetto (packet switching) . In questo caso, come si è detto, il messaggio viene diviso in blocchi (i pacchetti) di dimensioni prefissate che costituiscono l'unità di trasmissione.
Con questo metodo, nessun messaggio può monopolizzare la linea di comunicazione poiché è possibile intervallare pacchetti appartenenti a messaggi diversi, ottimizzando così l'utilizzo della linea. Inoltre i pacchetti possono venire facilmente elaborati nelle stazioni intermedie per consentire le conversioni di codice che si rendono talvolta necessarie nelle reti di calcolatori. E' per questo motivo che si parla di cammino virtuale tra trasmittente e ricevente, anche se i singoli pacchetti possono seguire percorsi fisicamente diversi. Nel caso si debba realizzare una normale conversazione telefonica utilizzando la commutazione a pacchetto, come accade nel "telefono via Internet" o Internet Phone, ci si trova di fronte al problema di realizzare la trasmissione dei pacchetti rispettando l'ordine di invio e di garantire il loro recapito entro un tempo prefissato ai fini di consentire l'interattività trasmittente-ricevente necessaria per questo tipo di comunicazione. Purtroppo, come abbiamo visto nella lezione precedente, il tempo di recapito dei pacchetti è in genere influenzato dalle condizioni di carico della rete, e quindi le reti a pacchetto sono cattivi vettori per il traffico telefonico.
La seconda tecnica in uso nelle connessioni tra calcolatori, è la commutazione di messaggio (message switching). Questa tecnica, chiamata anche store and forward , non prevede che il trasmittente sia connesso direttamente al ricevente, ma piuttosto che si limiti ad affidare il messaggio al più vicino centro di smistamento. Questo lo affiderà ad un altro e così via fino a che l'ultimo non lo consegnerà al destinatario. Si noti che la necessità di molteplici memorizzazioni intermedie dell'intero messaggio pone dei seri problemi alla realizzazione pratica di questo tipo di rete. In pratica questa tecnica è oggi d'attualità soprattutto per la realizzazione dei sistemi di posta elettronica su scala internazionale ed intercontinentale.
Queste rapide considerazioni dovrebbero già aver reso l’idea che i protocolli di tramissione sono molti e di tipi diversi. Infatti esistono protocolli che stabiliscono caratteristiche fisiche della trasmissione a livello di segnali elettrici, altri che riguardano la struttura dei pacchetti, altri ancora che definiscono proprietà di "alto livello" del messaggio come il modo di specificare il destinatario ed il mittente. Per fortuna, nella pratica è possibile definire il protocollo di un dato livello in modo pressocché indipendente da come sono realizzati i livelli sottostanti. Grazie a questa indipendenza, lo stesso protocollo che definisce la struttura dei pacchetti può appoggiarsi su protocolli fisici diversi orientati ai diversi mezzi di trasmissione esistenti come il cavo coassiale, il doppino telefonico o i cavi in fibra ottica. La struttura a livelli dei protocolli di trasmissione è descritta in dettaglio nell’approfondimento seguente.
**Approfondimento tecnico**
Il modello ISO-OSI
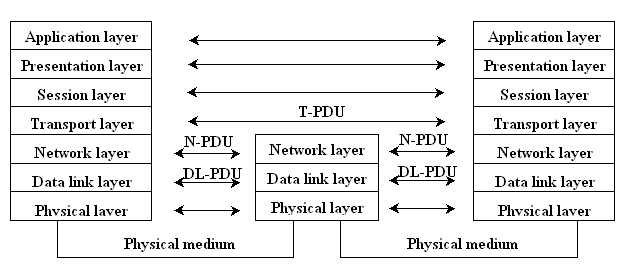
L'ISO, l'organismo internazionale (International Standards Organization) incaricato della standardizzazione in campo informatico, ha messo a punto un modello standard largamente accettato che viene chiamato OSI (Open System Interconnection) e definisce sette strati di protocolli.
Per meglio capire la natura di un protocollo multistrato, facciamo l'esempio dell'usuale servizio postale. Supponiamo che un uomo d'affari italiano voglia inviare una missiva ad un collega cinese. Dopo aver scritto il messaggio in italiano, lo passerà all'ufficio esteri della sua azienda. Dopo un certo tempo il nostro uomo d'affari troverà sulla sua scrivania un foglio con la risposta in italiano.
E' chiaro che per la realizzazione di questa comunicazione apparentemente diretta sono stati necessari diversi interventi. In primo luogo la lettera è stata tradotta in inglese; poi il traduttore ha passato la lettera tradotta a una segretaria che provvede alla spedizione. Tramite gli enti postali interessati, la lettera raggiunge poi l'azienda cinese, dove percorre una analoga trafila a ritroso, passando inizialmente per le mani di una segretaria, poi in quelle di un traduttore dall'inglese al cinese per giungere infine al destinatario. La risposta dell'uomo d'affari cinese seguirà poi lo stesso percorso per raggiungere l'azienda italiana. E' però importante sottolineare alcune caratteristiche che rendono il nostro esempio effettivamente analogo a un protocollo multilivello. Innanzitutto, si noti che i due corrispondenti possono tranquillamente ignorare quale lingua verrà utilizzata dai traduttori. Questi a loro volta non sono interessati a sapere se la missiva verrà inviata per posta o tramite un corriere. La stessa segretaria che provvede all'invio non è poi tenuta a sapere se il trasporto del plico dall'Italia al Giappone avverrà lungo la rotta polare o lungo quella diretta. In altre parole, le caratteristiche di un livello del protocollo possono cambiare, almeno in linea di principio, all'insaputa degli altri livelli. Inoltre, mentre allo strato più basso viene realizzata una comunicazione fisica (il viaggio della lettera) ad ognuno dei livelli superiori esiste una comunicazione apparentemente diretta, ma in realtà basata sui livelli sottostanti. Questo tipo di comunicazione è chiamata connessione logica.
La specifica ISO per la connessione tra sistemi aperti definisce ben sette di questi strati, di cui il primo è fisico e gli altri realizzano sei connessioni logiche. Si osservi che l'ISO non ha affatto definito i contenuti dei protocolli per ogni livello (la cui standardizzazione è compito di altri enti), ma ha stabilito quali sono le grandezze che, per ogni strato, uno standard di comunicazione deve fissare. Vediamone una rassegna cominciando dal livello più alto.
I sette livelli ISO/OSI.
Lo strato di applicazione (application layer) è completamente definito dall'utente finale, poichè è composto dai programmi che hanno l'esigenza di accedere alla rete, ad esempio per trasferire un file o un messaggio di posta elettronica da una macchina all’altra. Di questi programmi parleremo in dettaglio nei prossimi paragrafi; osservate però che anche a questo livello si può parlare di standard. Ad esempio, una specifica categoria di programmi utente può stabilire le regole da rispettare per effettuare la comunicazione; si pensi alle applicazioni usate in ambiente finanziario, che accedono alla rete per sapere quotazioni e dati delle Borse mondiali; questi programmi avranno una fase iniziale standard per farsi riconoscere e accreditare dai computer del centro finanziario a cui si rivolgono.
Abbiamo poi lo strato di presentazione (presentation layer) che (come i traduttori del nostro esempio) si occupa della conversione tra i diversi codici per la rappresentazione dei caratteri, ma specialmente di tutte le funzioni di formattazione dei testi e di gestione dei terminali.
Lo strato di sessione (session layer) si occupa di identificare l'utente del programma che desidera accedere alla rete, per essere sicuri che ne abbia l’autorità.
Lo strato di trasporto (transport layer) è quello divide il messaggio che proviene dallo strato superiore (il file, o il messaggio di posta elettronica) in porzioni più piccole da trasmettere separatamente (i pacchetti di cui abbiamo parlato in precedenza). A differenza di quanto avviene negli strati superiori, il software dello strato di trasporto può gestire contemporaneamente più messaggi provenienti da sessioni diverse in corso sullo stesso computer. Sarà quindi sua cura trasferire nei singoli pacchetti le informazioni relative alla sessione cui i pacchetti appartengono e il loro numero d'ordine all'interno della propria sessione. Questo numero consentirà allo strato di trasporto del computer destinatario di ricostruire correttamente i messaggi a prescindere dall'ordine d'arrivo dei pacchetti.
L'insieme dei tre restanti strati viene spesso chiamato subnet ed è realizzato in parte sotto forma di software, in parte di hardware. Vediamo gli strati OSI da cui sono costituite le subnet. Lo strato di rete (network layer) gestisce l'instradamento dei pacchetti creati da quello di trasporto e assicura la correttezza della comunicazione richiedendo la ritrasmissione dei pacchetti eventualmente danneggiati.
Lo strato di data link include i pacchetti in strutture più lunghi dette frame. I frame comprendono numerosi campi per le informazioni di controllo. Inoltre, il messaggio viene completato con nuovi frame (frame di acknowledgment) che contengono solo informazioni di servizio, ad esempio per la conferma della avvenuta ricezione degli altri frame.
Infine lo strato fisico (physical layer) definisce un insieme di regole relative all'hardware di comunicazione come ad esempio le tensioni e le correnti usate, le regole per stabilire il primo contatto (handshaking) e la direzionalità della comunicazione. E' anche importante dare un'idea di come, nella maggior parte dei casi, le funzioni hardware e software sono ripartite tra i livelli ISO/OSI. In modo del tutto informale, possiamo dire che i due livelli più bassi sono decisamente legati all'aspetto circuitale. Le funzioni di livello superiore (rete e trasporto) sono solitamente realizzate via software come parte del sistema operativo installato su ciascun computer, mentre i livelli superiori (sessione e presentazione) sono realizzati da programmi applicativi anch’essi forniti con il sistema operativo. Infine il livello di applicazione è costituito dal singolo programma utente che deve comunicare facendo uso della rete.
**Fine Approfondimento**
Le reti locali
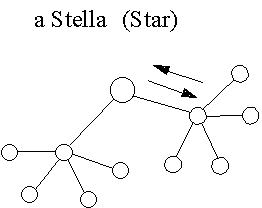
Nei decenni passati i computer sono entrati in tutte le aziende, non solo come risorse di calcolo, ma come strumento per la gestione dell'informazione. In un primo tempo il modello di gran lunga prevalente fu l’architettura a stella, ovvero un grande calcolatore (mainframe) al quale accedevano numerosi utenti con esigenze diverse, con la modalità operativa a partizione di tempo. La caratteristica di questa tecnica è che gli utenti si alternano nel possesso della macchina così rapidamente che ciascuno di essi ha l'illusione di esserne l'unico proprietario.
Nella figura sottostante è rappresentata l’architettura a stella.
Negli ultimi anni, la tendenza al ribasso dei costi delle risorse di calcolo e delle memorie, contrapposta ad una sostanziale stabilità dei costi dei canali di comunicazione, ha fatto diventare conveniente distribuire le risorse di calcolo presso i singoli utenti dando a ciascuno di essi un personal computer in sostituzione del terminale. La necessità sempre presente di consentire la comunicazione tra applicazioni in esecuzione su macchine diverse ha fatto nascere il problema di collegare questi personal tra di loro, formando delle reti locali di calcolatori. E’ proprio l’interconnessione di tutte queste reti locali a livello mondiale a costituire il "fenomeno" Internet.
Architetture di rete.
Le reti locali si presentano con una gran varietà di forme, ciascuna delle quali può essere realizzata con diversi tipi di linea. La caratteristica comune di tutte queste reti è che al loro interno non c’è bisogno di instradamento: tutti i messaggi generati da ciascuna macchina arrivano a tutte le macchine della rete locale. Ognuna di esse decide poi se il messaggio la riguarda, e lo legge oppure lo scarta. La topologia che inizialmente ebbe il sopravvento fu quella a stella, direttamente derivata da quella adottata per i mainframe.
In una LAN a stella tutti i messaggi devono passare per un computer centrale che controlla il flusso dei dati. Per ovvi motivi, in una rete a stella è facile l'aggiunta e la rimozione di computer periferici. D'altra parte è altrettanto ovvio che in una rete a stella se il computer centrale smette di funzionare la intera rete (come tale) diviene inutilizzabile.
Un'architettura oggi assai più diffusa è quella a bus.
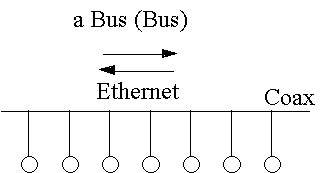
Con questa topologia i computer sono tutti connessi a un tronco di linea principale, detta appunto bus, che può essere realizzata con un cavo coassiale o su fibre ottiche. Questo tipo di rete è caratterizzato dal fatto che i computer sono paritetici e quindi anche se uno o più di essi si guastano, la rete continua a funzionare. Oggi le reti a bus, soprattutto in ambiente d’ufficio, sono spesso realizzate collegando ciascun computer mediante un filo in doppino di rame a un apposito scatolotto, detto hub di interconnessione o semplicemente hub. La struttura che ne risulta sembra una stella, ma lo hub svolge la funzione del bus condiviso.
Una terza topologia di rete, diffusa soprattutto in ambiente industriale, è quella ad anello.
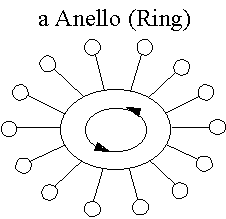
in cui i computer sono connessi ad un bus richiuso su se stesso. In questo tipo di rete i messaggi passano da un computer all'altro seguendo la stessa direzione rotatoria. Il problema fondamentale di una rete ad anello è quello di assicurare la stessa possibilità di accesso al bus a tutti i computer. Per tale motivo le reti ad anello vengono utilizzate soltanto con un particolare tipo di protocollo a token di cui ci occuperemo tra breve. Anche la rete ad anello presenta una elevata resistenza ai guasti, ed inoltre diverse reti di questo tipo possono facilmente collegarsi tra loro.
I livelli di rete e di trasporto.
Supponiamo che abbiate appena acquistato un hub per il vostro ufficio. Se all' hub colleghiamo più computer che desiderano colloquiare tra di loro sarà necessario che il dispositivo sappia evitare la sovrapposizione delle comunicazioni (collisione).
Vi sono due schemi fondamentali di
"regolamentazione del traffico" che consentono di evitare le
collisioni: il token passing, e il CSMA/CD (Carrier Sense
Multiple Access/Collision Detection ), caratteristico delle diffusissime
reti Ethernet.
Il primo schema si propone di evitare rigidamente il verificarsi di collisioni
e viene pertanto detto schema CA (collision avoidance). Il secondo
invece si accontenta di rilevare il verificarsi di una collisione ed utilizza
questa informazione per ritentare la trasmissione minimizzando la probabilità
che se ne verifichi un'altra. Lo schema token passing prevede l'utilizzo di un
messaggio convenzionale, detto token, che segnala lo stato di linea
libera. Nel caso più semplice il token viene posto sulla linea da una stazione
che assume il ruolo di sorgente. Le stazioni restano in ascolto sulla linea
finché non rilevano il token. Quando una stazione che desidera trasmettere
riconosce il token, lo toglie dalla linea sostituendolo con i pacchetti di dati
che costituiscono il messaggio. Durante questo periodo il token è assente e
pertanto nessuna altra stazione può iniziare a trasmettere. Al termine della
trasmissione la stazione deve provvedere al rilascio del token per consentire
un altro accesso alla linea. La seconda tecnica è il cosiddetto CSMA/CD, usato
in associazione con le topologie a bus per realizzare le reti Ethernet. Nella
sua forma base si tratta di un'idea molto semplice.
Quando una stazione desidera trasmettere dà liberamente inizio alla trasmissione, dopo di che si pone in ascolto sulla linea. Se rileva che il pacchetto in circolazione è stato danneggiato da una collisione, attende un intervallo di tempo casuale e poi riprova. In questa forma l'algoritmo, purché perfettamente funzionante, ha bassa efficienza poiché una stazione può iniziare a trasmettere quando un'altra ha quasi finito di scrivere il suo pacchetto di dati sulla linea. Ma il problema è facilmente risolvibile: le prestazioni possono venire migliorate semplicemente facendo sì che la trasmissione possa avere inizio soltanto se la linea risulta libera ed introducendo l'ascolto (per rilevare le collisioni) già durante la trasmissione.
Circuiti virtuali e datagram
Il complesso dei tre livelli di subnet costituisce, nella grande maggioranza dei casi, il prodotto effettivamente offerto dai costruttori di reti locali. In genere vi sono due tipi fondamentali di comunicazione consentiti dalle subnet: il circuito virtuale, ed il datagram. Nel primo caso, quello del TCP/IP propriamente detto, il programma che accede alla rete può utilizzare un canale di comunicazione "tipo linea telefonica", che gli sembrerà esente da errori. Anche se i dati viaggeranno in realtà suddivisi in pacchetti, per l'applicazione si tratterà di un flusso continuo di dati in viaggio sul canale. Sarà compito dell'applicazione eseguire le operazioni iniziali necessarie ad aprire il canale stesso. Questo schema riproduce l’operazione di "fare il numero" delle normali chiamate telefoniche. Vediamo come funziona.
Due programmi, per poter comunicare tra di loro inviandosi reciprocamente dei dati devono prima sincronizzarsi, cioè "mettersi d’accordo". TCP/IP prevede la seguente sincronizzazione, detta anche three way handshake: Chi prende l’iniziativa della connessione, ovvero il client, invia un pacchetto convenzionale, il SYN packet, che dice al suo interlocutore, il server: "Voglio comunicare con te". Il server risponde al client: "Ok! Aspetto conferma" e il client risponde al server: "Confermo!". A questo punto inizia la comunicazione vera e propria. Questa sincronizzazione viene fatta automaticamente dai programmi e in maniera trasparente agli utenti. Nel caso del datagram invece, il messaggio è ripartito su più blocchi ciascuno dei quali è consegnato separatamente al destinatario, senza che sia stat stabilita alcuna connessione. E’ nel caso di questo tipo di comunicazioni, anch’esse possibili in ambito TCP/IP con il nome UDP (User Datagram Protocol) che l’instradamento viene fatto dai router pacchetto per pacchetto. Si noti che, mentre il circuito virtuale simula un canale esente da errori, poichè la consegna di ogni pacchetto è confermata dal destinatario, la consegna del datagram non è affatto garantita. Questo particolare rende ancora più credibile l'analogia tra questo tipo di servizio e l'usuale servizio postale.
Le inter-reti e l’instradamento
Supponiamo ora di avere tante reti locali sparse per il mondo, ognuna con la sua subnet, e di volerle collegare tra loro tramite router. In questo paragrafo ci occuperemo dei meccanismi che consentono ai router di risolvere il fondamentale problema che riguarda l'inoltro di un messaggio generato su una certa rete al destinatario posto su un’altra. Sulla singola rete locale il problema non si pone, visto che la comunicazione è di tipo broadcast, cioè ogni pacchetto viene inviato a tutti i computer della rete, ciascuno dei quali individuà le comunicazioni a lui dirette grazie all'indirizzo contenuto nel messaggio e scarta le altre.
Per le inter-reti ottenute collegando varie reti locali, così come la stessa Internet, questo meccanismo non è utilizzabile, visto che richiederebbe di inviare ogni pacchetto su tutte le reti componenti, con uno spreco inaccettabile di tempo. Dato l’indirizzo di un computer destinatario, bisogna quindi saper definire un cammino sulla rete tra il computer che ha originato la comunicazione e il destinatario.
Si potrebbe pensare di scegliere questo cammino (definito dalla sequenza di router che i dati dovranno attraversare nel loro percorso) una volta per tutte all'inizio della comunicazione. Ciascun router intermedio deve inoltrare il pacchetto al router che lo segue lungo il cammino. Ma come fa a sapere qual è il router giusto? Per questo, come abbiamo visto, si usano le tabelle di instradamento, che sono memorizzate in file residenti sui dischi di ciascun router e vengono ovviamente aggiornate ad intervalli regolari. La tabella di ciascun router contiene in genere tante righe quante sono le reti raggiungibili da quel router, insieme con l’indicazione, per ciascuna di esse, del router di inoltro. Ma non sempre questo basta, poichè non è detto che per raggiungere una certa rete si debba percorrere sempre lo stesso cammino, e quindi non è detto che il router di inoltro verso un destinatario resti sempre lo stesso. Il traffico su una grande rete di calcolatori come Internet è, per sua natura, ad ondate. Quindi è normale che una porzione della rete sia pesantemente utilizzata per un po’, magari per la trasmissione di un grosso archivio e poi resti inutilizzata per ore. Ciò rende necessario variare i percorsi dei dati a seconda delle condizioni di traffico della rete. A questo proposito va ribadita un'importante differenza tra datagram e circuito virtuale. Nel primo schema di comunicazione la decisione relativa al computer di inoltro può essere presa pacchetto per pacchetto, mentre nel caso dei circuiti virtuali questa decisione vale per l'intera durata della comunicazione. Per quanto riguarda l'affidabilità dei router, in caso di guasto è importante poter utilizzare percorsi alternativi. In termini generali si può quindi fare una distinzione tra algoritmi di inoltro adattativi e non. I primi avranno la capacità di variare il computer di inoltro in modo dinamico sulla base delle condizioni della rete. All’inizio del paragrafo, descrivendo le tabelle di inoltro, abbiamo implicitamente specificato un metodo non adattivo, che viene spesso chiamato static inoltro. Si potrebbe pensare anche a tecniche di instradamento non adattative che non richiedano la specificazione delle tabelle di inoltro. A titolo di esempio consideriamo l'algoritmo detto random walk. Secondo questo algoritmo un computer delle rete, ricevendo un pacchetto non diretto a lui, si limita a scegliere a caso una linea (esclusa ovviamente quella di arrivo) su cui inoltrarlo. Benché questi algoritmi abbiano lo spiacevole effetto di affollare indebitamente le linee, sono tuttavia notevolmente "robusti" nel senso che garantiscono un'elevata probabilità di recapito del messaggio anche nel caso di interruzione di alcuni cammini. Un altro esempio tipico è lo schema di hot potato (patata bollente!) secondo il quale ciascun computer, ricevendo un pacchetto, si limita ad inoltrarlo sulla linea per cui è minimo il numero di pacchetti in coda per essere trasmessi. Si osservi che, analogamente a quanto accade con l'algoritmo di random walk, usando la patata bollente non c’è nessun tipo di controllo su "dove" porti la linea prescelta; anche in questo caso, quindi, si suppone un elevato grado di interconnessione della rete. Su Internet, si usano protocolli di inoltro adattativi: i principali provider Internet usano un protocollo chiamato ISIS (Intermediate System-Intermediate System) all'interno delle loro reti. Altri ISP e aziende usano un diverso schema chiamato OSPF (Open Shortest Path First). Quando i dati vengono scambiati da un ISP a un altro, viene usato il BGP (Border Gateway Protocol). La descrizione di questi protocolli non è difficile, ma richiede un certo spazio e non verrà pertanto affrontata in questo corso.
I livelli superiori di ISO/OSI.
A differenza di quanto accade per gli strati inferiori del modello ISO/OSI, gli strati superiori presentano un basso grado di standardizzazione. Ciò avviene perché questi livelli riguardano i programmi che usano la rete e programmi scritti per applicazioni diverse hanno ovviamente esigenze diverse per quanto riguarda la comunicazione. Infatti, mentre i livelli inferiori si occupano genericamente di dati in viaggio da un computer ad un altro senza rendersi conto della pluralità (e della diversa natura) dei programmi esistenti sui vari computer, i livelli superiori dello standard ISO/OSI fanno riferimento al singolo programma come terminale della comunicazione. Vi saranno quindi tanti servizi di sessione e presentazione quante sono i programmi applicativi che devono comunicare. Tutte le presentazioni "consegneranno" poi i loro dati all'unico servizio di trasporto del computer, che non fa distinzione tra pacchetti provenienti da applicazioni diverse. Il compito principale del livello di trasporto è quindi la gestione dell’invio sulla stessa linea dei pacchetti provenienti da processi diversi, ed eventualmente il riordino dei pacchetti sulla base di un numero di sequenza (sequence number). Ciò può comportare l'introduzione di opportuni ritardi di consegna per i pacchetti pervenuti fuori sequenza in modo da rimetterli nell’ordine giusto. L'esempio dello scambio di lettere tra gli uomini d’affari italiano e cinese può aiutare a capire come gli strati più elevati siano meno standardizzabili, senza che ciò costituisca un difetto delle specifiche ISO. Infatti non è facile, a questo livello, imporre uno standard senza interferire con i contenuti della comunicazione. Sarebbe assurdo pensare di imporre tramite regolamento postale la presenza di specifiche frasi di convenevoli all'inizio e alla fine di una lettera d'affari come quella dell'esempio. Nonostante questo minor grado di formalizzazione dei livelli superiori ci sono alcuni servizi applicativi così diffusi da essere divenuti a loro volta oggetto di standard, come il trasferimento di archivi e la posta elettronica.
Il livello di applicazione
Il livello di applicazione è costituito dai programmi utente che richiedono la trasmissione di dati sulla rete Oggi tutti i computer connessi a Internet sono dotati di un programma polivalente di questo tipo, il browser. Ce ne occuperemo prossimamente.
Il livello di presentazione
Lo scopo del livello di presentazione è convertire i dati provenienti dalle applicazioni e destinati ad essere trasferiti sulla rete in un opportuno formato comune. In generale vi sono più formati a disposizione, tra cui i processi interlocutori devono scegliere. A questo livello possono venire offerti servizi quali la compressione dei dati e le tecniche crittografiche.
Il livello di sessione
Il livello di sessione ha il compito di includere nel messaggio quelle informazioni necessarie per la corretta ripartizione dei costi di comunicazione (ricordiamo che il sottostante livello di trasporto non distingue tra i vari processi committenti delle comunicazioni). Inoltre, questo livello deve farsi carico delle conversioni necessarie tra le codifiche dei dati utilizzate dai vari computer della rete, un problema particolarmente importante nel caso di reti che comprendono macchine di modelli e costruttori diversi.
TCP/IP e ISO/OSI
Nei paragrafi iniziali della lezione abbiamo accennato al fatto che Internet si basa su TCP/IP. Si tratta di un protocollo sviluppato indipendentemente dagli standard ISO/OSI, che pure ha assunto la rilevanza di uno standard industriale. TCP/IP è importante perchè permette i collegamenti tra le reti diverse che compongono Internet, e può essere usato anche all’interno di una rete locale. La corrispondenza tra TCP/IP e la pila di protocolli ISO/OSI può essere schematizzata nella figura sottostante.
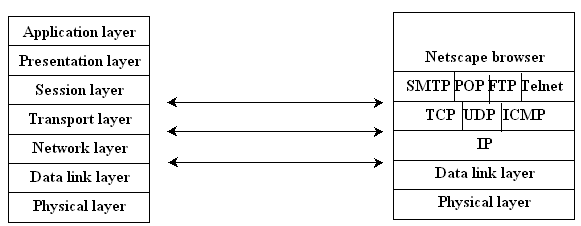
Come si vede TCP/IP realizza globalmente il terzo e il quarto strato dello schema OSI, ma può a sua volta essere diviso in livelli. Al primo livello di TCP/IP si situano alcuni servizi base che una rete deve mettere a disposizione delle applicazioni che girano sulle macchine collegate ai suoi computer come la possibilità di trasferire dei file (FTP: File Transfer Protocol) e le funzionalità di base della posta elettronica (SMTP: Simple Mail Transport Protocol). Il secondo livello fornisce i due modelli di comunicazione tra applicazioni remote di cui abbiamo parlato. Il primo, detto Reliable Stream, costituisce l'analogo software di un circuito virtuale poiché richiede che i terminali tra cui avviene la comunicazione siano in linea nello stesso momento. Il secondo, detto User Datagram, simula invece la commutazione di pacchetto, spezzando un messaggio in sottounità che contengono informazione di indirizzamento e informazioni rivolte alla ricostruzione della loro sequenza.
La struttura degli indirizzi TCP/IP
Torniamo ora alla struttura degli indirizzi TCP/IP; infatti ce ne siamo già occupati, perchè l’indirizzo TCP/IP non è altro che l’host number che abbiamo descritto nei paragrafi che precedono. Per quanto riguarda la struttura degli indirizzi TCP/IP, la filosofia di base è quella di fornire ad ogni computer di Internet un unico indirizzo di lunghezza fissa, pari a quattro byte ossia 32 bit. Va notato che questa scelta comporta che gli indirizzi disponibili su Internet costituiscano una risorsa finita, anche se abbondante. Si tratta di ben 232 computer indirizzabili: una quantità però che per le odierne necessità sembra appena adeguata. Si possono avere quattro classi di indirizzi di cui però l'ultima non è attualmente usata. Ciascun tipo di indirizzamento viene attribuito ad una rete locale sulla base del numero dei computer che la compongono.
Il numero IP non è un tutto unico: è ancora suddivisibile in un campo network id che serve ad identificare la rete locale all'interno di Internet su cui si trova la macchina da raggiungere e un campo host id che identifica la specifica macchina. Le host id costituite da tutti zeri e tutti uni corrispondono rispettivamente alla comunicazione sullo stesso computer, senza accesso alla rete ed alla comunicazione broadcast verso tutti i computer della rete. Come si è detto, per indicare uno dei processi in esecuzione su un dato calcolatore si usa il port number. Un port corrisponde al terminale di un canale di comunicazione virtuale che TCP/IP mette a disposizione del processo.
Vediamo più da vicino la struttura di un messaggio TCP/IP. Val la pena di osservare che la complessità di questo protocollo è di gran lunga superiore agli altri visti finora: ciò è dovuto alla sua capacità di gestire anche reti di bassa qualità caratterizzate da elevato tasso di rumore e da frequente perdita di dati. TCP/IP decompone i messaggi delle applicazioni utente in parti di lunghezza non superiore a 65 Kbyte da inviare separatamente. L'invio del messaggio è preceduto da una procedura di negoziazione a tre stadi dopo di che vengono inviati i pacchetti di dati.
L'header (intestazione) dei pacchetti occupa ben 40 byte. Questo header in realtà è diviso in due parti. La prima, ovvero l’intestazione IP propriamente detta, riguarda la trasmissione del singolo pacchetto. La seconda, detta intestazione TCP serve per gestire una connessione, cioè un flusso di pacchetti tra un mittente e un destinatario. Infatti, la parte TCP si incarica della corretta sequenzializzazione dei pacchetti e delle eventuali ritrasmissioni necessarie per compensare eventuali errori di trasmissione. Vediamo una breve descrizione dei campi che compongono l'header TCP. I campi relativi ai port mittente e destinatario permettono di identificare i due programmi remoti tra cui ha luogo la comunicazione. Seguono il numero d'ordine del pacchetto e la lunghezza dello header che è variabile perché può comprendere un numero arbitrario di opzioni. Poi c’è una serie di indicatori o flag, che vengono utilizzati per la procedura di creazione e terminazione della connessione. Vi è poi una somma di controllo per la correzione automatica degli errori ed un campo di opzioni utilizzato per vari scopi tra cui la determinazione della dimensione dei buffer di memoria che devono essere mantenuti localmente dagli interlocutori. Per quanto riguarda lo header IP basterà dire che attraverso il campo tipo di servizio è possibile selezionare una modalità di trasmissione tra quelle offerte dai livelli inferiori consentendo così una notevole flessibilità del protocollo a seconda della natura dei dati da inviare. Ad esempio per trasmettere voce digitalizzata la velocità è da privilegiare rispetto alla correzione d'errore; mentre per un trasferimento di file è vero il contrario. Un altro elemento di adattabilità è il campo versione, che consente di specificare a quale versione del protocollo fa riferimento il pacchetto. Ciò consente di utilizzare nuove versioni del protocollo mantenendo la compatibilità a cavallo di versioni successive. Per concludere è bene far osservare ai lettori esperti di comunicazioni le ragioni che stanno alla base della grande differenza tra TCP/IP e i protocolli per le telecomunicazioni pubbliche, come il noto X.25. Nell'ottica di chi ha progettato TCP/IP il traffico di rete è prevalentemente locale con sporadici accessi ai router per le comunicazioni di lunga distanza. In questo schema la flessibilità che si ottiene prevedendo header lunghi e dettagliati fa premio sul tempo sprecato per trasmetterli. D'altro canto gli Enti postali che hanno a che fare con la rete telefonica considerano il tempo di trasmissione una risorsa preziosa e tendono a usare header molto corti. Questa tendenza si è espressa pienamente nel progetto della rete ATM..
ATM e i router del futuro
Ad ogni tappa (hop) del percorso compiuto da un pacchetto, un router deve selezionare il suo prossimo passo verso la sua destinazione. Come si è visto, la maggior parte dei percorsi a lunga distanza viaggia su linee affittate dalle società telefoniche, alcune delle quali sfruttano tecnologie a commutazione di pacchetto. Ciò significa che i dati possono essere impaccati e instradati su molti livelli contemporaneamente. Ad esempio, la rete ATM traferisce i dati ad alta velocità in minipacchetti chiamati "celle" Invece dei router, ATM usa degli "switch" per differenziare i tipi di traffico e controllare il flusso di celle. Già oggi è normale inviare il traffico TCP/IP sulle linee ATM, ma non è chiaro se i router IP continueranno a gestire il traffico sempre crescente di Internet o se gli switch ATM li sostituiranno. A differenza dell'instradamento IP, ATM è più simile al sistema telefonico; si tratta di un sistema in cui viene stabilito un "circuito virtuale" tra interlocutori che viene tenuto in servizio fin quando dura la comunicazione. ATM è adatto specialmente per le applicazioni multimediali in tempo reale perchè una volta che il circuito è stabilito, le celle ATM seguono tutte lo stesso percorso percorso e impiegano, più o meno, lo stesso tempo.
I sostenitori dei router IP insistono sul fatto che i router sono più flessibili grazie alla capacità di inoltrare i pacchetti lungo diversi percorsi, mentre ATM è un sistema rigido con connessioni fisse. I fautori di ATM ribattono che gli switch ATM sono più veloci e che vi sono delle tecniche per rendere flessibili le reti ATM di essere attraverso la segmentazione. Oggi, ATM viene usato principalmente dai grandi provider per le loro dorsali e solo il tempo dirà se la commutazione ATM sarà utilizzata esclusivamente per i collegamenti a lunga distanza o se la tecnologia verrà impiegata a livello locale. In Italia, linee ATM a lunga distanza per il traffico Internet sono già usate ad esempio da Interbusiness; una delle prime installazioni di ATM per rete locale è stata fatta presso l’Università di Milano, Polo di Crema (http://weblab.crema.unimi.it/tppmsgs/msgs0.htm#2)
I protocolli applicativi TCP/IP
Veniamo ora a una descrizione generale dei protocolli di alto livello che si basano su TCP-IP. Questi protocolli (che realizzano i livelli più alti della pila ISO-OSI di cui abbiamo parlato in precedenza) definiscono il contenuto (e la corretta sequenza) dei pacchetti TCP/IP a seconda del servizio applicativo a cui si riferiscono. Ecco un elenco:
* telnet Consente a un utente a un terminale su una macchina di comunicare interattivamente con un programma, ad esempio un word-processor che gira su un computer remoto, come se il terminale dell'utente fosse collegato direttamente.
* FTP (File transfer protocol, Protocollo per il trasferimento di file) Consente a un utente a un terminale di accedere e interagire con un disco remoto.
* SMTP (Simple mail transfer protocol, Protocollo semplice per il trasporto di posta) Fornisce un servizio di trasferimento della posta esteso a tutta la rete.
SNMP (Simple network management protocol, Protocollo semplice per la gestione di rete) Consente al gestore di rete di controllare il funzionamento di un elemento di rete (ad esempio un router) attraverso la rete stessa.
Un'esigenza comune a tutte le interazioni tra server e client è quella di stabilire una connessione TCP tra i due processi o protocolli applicativi coinvolti. Quindi, prima di esaminare i diversi protocolli, ricordiamo brevemente come è stabilito il collegamento.
Come sappiamo, tutti i server hanno un nome che si traduce in un corrispondente indirizzo IP valido su tutta la rete. L'indirizzo completo di un processo server è formato da due parti: l'indirizzo IP del calcolatore su cui il processo è attivo e il numero di port locale. L'indirizzo IP viene usato dai router dell'inter-rete per instradare i pacchetti all'elaboratore di destinazione richiesto. Il numero di port è utilizzato dal software all'interno del calcolatore destinatario per identificare il programma a cui va inoltrato un messaggio ricevuto.
Come vedremo nelle prossime lezioni, sul vostro personal computer si trovano i programmi client e server per diversi tipi di servizi (FTP, SMTP e così via). Ricordate che a tutti i server dello stesso tipo, su tutti i calcolatori del mondo, è assegnato lo stesso numero di port. I numeri di port dei diversi tipi di server sono noti come port "well-known". Eccone alcuni esempi:
21 - FTP
22 - telnet
25 - SMTP
Quindi, quando un processo client inizia una chiamata a un processo server corrispondente, crea una connessione TCP che utilizza come indirizzo di destinazione l'indirizzo IP del calcolatore su cui il server gira insieme al numero di port "well-known" di quel server. Come proprio indirizzo, il client usa l'indirizzo IP dell'elaboratore su cui si trova insieme al successivo numero di porta libero su quel calcolatore.
Telnet
Come vedremo nelle prossime lezioni, quasi tutti i sistemi operativi più diffusi (Unix, Windows, MacOS ed altri) forniscono un programma telnet per consentire all’utente di connettersi al sistema operativo di una macchina remota, di iniziare l'esecuzione di un programma su quella macchina e poi di interagire con esso come se si trovasse sulla macchina locale. Tutti i comandi e i dati inseriti dall'utente sono passati dal sistema operativo locale al processo client telnet che poi li trasmette, usando il collegamento TCP, al telnet server del calcolatore remoto. Quest'ultimo inoltra i comandi dell'utente, attraverso il sistema operativo locale, al processo destinatario. Una qualsiasi emissione di dati dal processo destinatario viene restituita nello stesso modo per essere visualizzata sullo schemo del client. I due telnet, client e server, comunicano l'uno con l'altro in modo trasparente all’utente inviamdosi pacchetti TCP che contengono singoli caratteri o stringhe di caratteri, codificati in un formato standard noto come NVT (Network virtual terminal, Terminale virtuale di rete). Tutti i dati in ingresso e in uscita da telnet sono trasferiti come stringhe ASCII.
FTP
L'accesso al disco di un computer remoto è una funzionalità di base delle reti di calcolatori. Il protocollo FTP consente l’accesso a dischi remoti per prelevare file da trasferire sul computer locale (download) o viceversa (upload).
Il client FTP fornisce una serie di servizi simili a quelli disponibili sui dischi locali. Usandolo per collegarsi a un computer dove è presente un server FTP, l’utente può elencarne le directory, creare nuovi file, leggere i contenuti dei file esistenti e così via. Alla ricezione di ogni richiesta il server FTP interagisce con il suo disco locale per soddisfare la richiesta come se fosse stata generata localmente.
Il client FTP permette all’utente di specificare la struttura del file interessata e il tipo di dati. Sono supportate tre strutture di file (non strutturata, strutturata e accesso casuale) e quattro tipi di dati (binario a 8 bit, testo (ASCII ed EBCDIC) e binario a lunghezza variabile). Nel trasferire i file al client, il server FTP tiene conto della sua struttura.
Il formato dei messaggi associati ai contenuti dei file è determinato dalla struttura definita del file. Il formato dei messaggi scambiati tra i due processi di controllo di FTP deve avere una sintassi concordata per assicurare che abbiano lo stesso significato (e siano interpretati nello stesso modo) in entrambi i calcolatori. Per ottenere ciò si utilizza il formato NVT citato nel paragrafo precedente.
SMTP
La posta elettronica è probabilmente il servizio più usato su Internet e in generale sulle reti di calcolatori. I sistemi di posta locali sono disponibili da molti anni sulla maggior parte dei sistemi di elaborazione multiutente; fu quindi un'evoluzione naturale estendere il servizio attraverso la Rete quando questi calcolatori furono collegati in rete tra di loro.
SMTP (Simple mail transfer protocol, Protocollo semplice per il trasporto di posta) gestisce il trasferimento della posta dal sistema di posta di un calcolatore a quello di un altro. Non è suo compito accettare la posta diretta ad altri utenti della stessa macchina; queste sono operazioni che spettano al sistema di posta locale. Il fatto che molti computer collegati alla Rete siano personal usati da una persona sola ha portato molti utenti ad identificare integralmente il servizio di posta con SMTP. In realtà SMTP si occupa solo della posta diretta a utenti di computer remoti. Il sistema di posta locale tiene per ciascun utente una indirizzo di e-mail in cui depositare o ricevere la posta. Ogni indirizzo di e-mail ha un nome univoco che è costituito da due parti: una parte locale e una parte globale. La prima è il nome dell'utente ed è unica solo all'interno del sistema di posta locale, mentre la seconda è un nome di calcolatore che come sappiamo è unico su tutta Internet. Vi sono due punti da prendere in considerazione nel trasferimento della posta: il formato dei messaggi, per essere certi che sia interpretato nello stesso modo in ogni sistema, e il protocollo usato per trasferirli da una macchina a un'altra. Il formato della posta è costituito da un'intestazione e da un testo che a loro volta sono costituiti da più righe di testo ASCII con una riga vuota che separa l'intestazione dal testo. Ogni riga nell'intestazione comprende una parola chiave seguita da una stringa di testo con due punti che separano i due elementi. Alcune parole chiave sono obbligatorie mentre altre sono facoltative. L'intestazione minima è la seguente:
TO: nome del ricevente
FROM: nome del mittente
Ecco i campi facoltativi
TO: nome del ricevente
REPLY TO: nome a cui inviare la risposta
TO: nome del ricevente
FROM: nome del mittente
CC: ricevente di una copia carbone
SUBJECT: argomento
DATE: data
ENCRYPTED: puntatore alla tecnica crittografica
La parola chiave ENCRYPTED indica che la parte del testo, cioè i contenuti, sono stati cifrati usando una chiave che il ricevente può dedurre dal puntatore di cifratura. L'intestazione, tra cui SUBJECT (cioè l'argomento) e i nomi del destinatario, è sempre in testo normale. Per inviare la posta, il protocollo SMTP del client prima accerta l'indirizzo IP del calcolatore di destinazione dal servizio DNS poi lo utilizza, insieme all'indirizzo di port "well-known" di SMTP (25), per iniziare l'impostazione di una connessione di trasporto con il server SMTP nel calcolatore di destinazione. Una volta che è stata stabilita una connessione, il client inizia il trasferimento della posta in attesa al server.
L'inoltro della posta implica lo scambio di stringhe di testo chiamate comandi. Tutti i comandi sono codificati come stringhe di caratteri ASCII e comprendono un numero di 3 cifre oppure un comando in formato testo o entrambi.
Una connessione SMTP
Per capire bene il concetto di protocollo ad alto livello non ci sono alternative: bisogna seguire una connessione passo passo. Da questo punto di vista il protocollo SMTP è particolarmente istruttivo, quindi vediamo in dettaglio le varie fasi di una connessione.
Appena stabilita la connessione TCP, il server SMTP invia il comando 220 al client per indicare che è pronto a ricevere la posta. Il client risponde ritornando un comando HELO insieme all'indirizzo IP della macchina su cui si trova. Alla ricezione di questo, il server risponde con l'identità della propria macchina. Il client inizia poi a inviare l'intestazione della posta fornendo un comando MAIL seguito dalla riga FROM: presa dall'intestazione del messaggio da trasmettere. Il server replica con il comando generale 250, la conferma di ricezione. Il client continua inviando un comando RCPT seguito dalla riga TO: presa dall'intestazione della posta. Questo viene confermato ancora da un comando 250; qualunque ulteriore riga d'intestazione è inviata nello stesso modo.
L'inizio dei contenuti del messaggio di posta elettronica è segnalato quando il client invia un comando DATA. Il server risponde con un comando 354 e il client poi spedisce i contenuti della posta come una sequenza di righe terminate da un punto. Il server conferma la ricezione restituendo un comando 250. La fase di trasferimento della posta è terminata quando il client invia un comando QUIT e il server ritorna un comando 221, a cui segue l'interruzione della connessione TCP di trasporto.
Questo scambio dovrebbe aver chiarito le funzioni base del protocollo SMTP, ma nella pratica sono disponibili molte altre funzioni, a seconda delle implementazioni. Di questo ci occuperemo nelle prossime lezioni.
SNMP
I tre protocolli di applicazione finora trattati, telnet, FTP e SMTP, riguardano tutti gli utenti della rete. Al contrario, SNMP (Simple network management protocol, Protocollo semplice per la gestione di rete) non interessa gli utenti finali, ma i gestori dell'ambiente di rete.
Ricordate che la Rete comprende un gran numero di diversi dispositivi, tra cui i server e i router per l'interconnessione di LAN diverse. Internet, da questo punto di vista, è come la rete autostradale: se si verifica un guasto e il servizio è interrotto, gli utenti si aspettano che riprenda con un ritardo minimo. Se poi le prestazioni peggiorano per l’aumento del traffico su parte della Rete, gli utenti si immaginano che le porzioni congestionate vengano subito identificate e che sia aumentata la capacità di trasmissione in modo risolvere il problema. Il protocollo SNMP, anche se non è la bacchetta magica che gli utenti finali vorrebbero, è stato definito per aiutare i gestore della Rete a eseguire le funzioni di gestione dei guasti e di controllo delle prestazioni.
Il concetto i base di SNMP è considerare tutti gli elementi della rete che bisogna controllare (router, server e così via) come oggetti gestiti. Associata a ciascun oggetto vi è una serie di informazioni di gestione. Alcune di queste, definite anche attributi, possono essere o lette o scritte dal gestore della rete attraverso la rete stessa per regolare il funzionamento dell’oggetto. Vi sono anche i messaggi di rilevazione dei guasti che vengono inviati da un oggetto gestito quando si verifica un malfunzionamento. Se un router cessa di rispondere ai messaggi di saluto, il suo vicino, oltre a modificare la sua tabella di instradamento per riflettere la perdita del collegamento, può creare e inviare un messaggio di rilevazione dei guasti attraverso la Rete, per segnalare il problema al gestore.
Il ruolo di SNMP è permettere al processo di gestione, un programma che si trova sul computer del gestore di rete, di scambiare dei messaggi relativi all'amministrazione con appositi programmi attivi nei vari oggetti gestiti: calcolatori, router e così via. Le informazioni così ottenute sono memorizzate nella stazione del gestore di rete in una MIB (Management information base, Base informativa di gestione). Il gestore di rete è fornito di una serie di programmi per consultare le informazioni nella MIB, per dare inizio alla raccolta di ulteriori dati e per eseguire i cambiamenti di configurazione della rete.
Altri protocolli
I protocolli di applicazione basati su TCP/IP non si fermano certamente qui. Di due di essi, il protocollo del Web HTTP e IIOP, il protocollo che sta alla base delle applicazioni a oggetti distribuiti, avremo modo di parlare diffusamente nel seguito delle lezioni.
Comunque, qualsiasi protocollo ad alto livello che deve funzionare su Internet deve basarsi su TCP o UDP come quelli che abbiamo qui delineato.
ESERCIZIO (5 PUNTI)
Stabilite il tipo di collegamento di cui disponete e se possibile l'indirizzo ip assegnato. (Suggerimento: per utenti Windows fare clic sull'icona di connessione…) inviare via mail il risultato ai Tutors.
Tutorial 3
I servizi base di Internet
La prima cosa necessaria per accedere a Internet è disporre di un computer collegato alla Rete. La lettura delle lezioni precedenti dovrebbe aver fornito le indicazioni necessarie in proposito. Comunque, per chi lavora in un'organizzazione che ha una connessione permanente ad Internet (ad esempio, un’Università), non ci sono problemi: sarà il responsabile del Centro di Calcolo a fornire tutte le informazioni necessarie. Altrimenti, bisogna collegarsi via telefono a un provider e valgono le considerazioni del tutorial precedente. Se si usa il collegamento Internet permanente di una società o università, non bisogna occuparsi del programma di comunicazione, perché il proprio computer è già collegato direttamente a un computer che, a sua volta, è collegato a Internet. La configurazione del sistema di connessione da usare, quindi, è a carico del responsabile del collegamento Internet dell'organizzazione (di solito, l’amministratore di rete).
Se dovete creare un collegamento in commutata, invece è necessario disporre di un personal computer con un modem (o un adattatore ISDN) e un programma di comunicazione, affinché il proprio computer chiami il computer del fornitore e "si colleghi" via PPP. Oggi questi programmi di comunicazione sono integrati nella maggior parte dei sistemi operativi per personal computer, da Windows 95 o NT a Mac0S, OS/2 e chi più ne ha più ne metta; ogni buon provider è in grado di spiegarvi come configurarli. Inoltre, per iniziare a esplorare Internet dovete avere un browser, cioè un programma applicativo per l’accesso ai vari servizi di rete.
I più diffusi browser sul mercato oggi sono Netscape Navigator e Microsoft Explorer. Nel seguito, supporremo che il lettore disponga di un computer correttamente configurato per l’accesso alla Rete e di uno di questi due programmi. Infatti, nel corso di questo e dei prossimi capitoli, vi verrà spesso chiesto di "andare" a un indirizzo di Rete.
Per farlo sia con Netscape che con Explorer, basta digitare l'URL nella finestrella posta nella parte superiore del video e premere Invio.
Gli strumenti per l'accesso a Internet
Lavorare sul proprio personal computer e navigare in Rete sono due cose ben diverse. Sul proprio computer si ha un'interazione istantanea con i programmi e gli effetti delle proprie scelte sono immediatamente visibili. Nel caso di Internet, milioni di computer sono collegati a distanze di migliaia di chilometri; ovviamente, questo provoca tempi di attesa che possono diventare assai lunghi. Per motivi di efficienza, il software per interagire con la Rete è composto di una comunità di moduli, alcuni specializzati nel presentare richieste di elaborazioni (i client, di cui un esempio è proprio il browser), altri nell'eseguirle (i server). Una volta che i server sono stati installati, possono soddisfare le richieste di un gran numero di client diversi. Per questo motivo, si può parlare genericamente di Netscape o di Internet Explorer, dando per scontato che ne esista una versione per Mac, una per DOS/Windows, una per OS/2 e così via.
Considerando le dimensioni della Rete, il gran numero di computer che vi sono connessi stabilmente e l’enorme quantità di informazioni disponibili, si può ben capire come sia difficile non perdersi vagando su Internet. Per fortuna, esistono molti strumenti software per facilitare il compito degli utenti. Ognuno di questi programmi ha per così dire la sua specialità e può essere utile in determinate circostanze. Alcuni di essi, detti strumenti di base, sono disponibili sulla Rete fin dai primi tempi. In questa lezione ne diamo una breve presentazione, rimandando il lettore alla prossima per notizie più dettagliate sul loro uso con Netscape Navigator o Microsoft Explorer.
Dal punto di vista concettuale, comunque, è importante rendersi conto subito che ciascuno degli strumenti che utilizzeremo si trova ai livelli alti della pila OSI, ovvero "realizza" un protocollo ad alto livello, a sua volta "basato" su TCP/IP.
Ma cosa significa in realtà questa frase ? Ricorderete dal tutorial precedente che TCP/IP (il protocollo di Internet) è uno standard che definisce anzitutto come suddividere l'informazione che deve viaggiare sulla Rete, ad esempio un messaggio, in piccoli pezzi (i pacchetti) contrassegnati dall'indirizzo numerico IP del destinatario e inoltrati indipendentemente. TCP/IP definisce la struttura di questi pacchetti, ad esempio prescrivendo che l'indirizzo del destinatario vada messo all'inizio del pacchetto. Inoltre, spiega come recapitare i pacchetti a destinazione, anche se questo tema è più complicato e non ci interessa approfondirlo... almeno per ora.
Cosa vuol dire allora che un server Internet "realizza un protocollo ad alto livello basato su TCP/IP"? Significa che ogni servizio di Internet definisce un tipo di pacchetti TCP/IP prescrivendone la struttura INTERNA. Tutti i pacchetti TCP/IP hanno l'indirizzo IP del destinatario all'inizio; ma i pacchetti che contengono pezzi di un messaggio di posta avranno, ad una posizione prefissata al loro interno, una sigla che li identifica come tali e chiarisce la loro funzione. Questa sigla sarà diversa da quella presente nei pacchetti inviati da altri servizi, come quello di trasferimento dei file.
La Posta Elettronica
Il più popolare servizio di Internet è il suo sistema di posta elettronica . La posta elettronica consiste semplicemente nel mandare messaggi attraverso la Rete: il destinatario di un messaggio lo troverà pronto da leggere sul suo computer non appena si collega. La semplicità di questo concetto fà si che quasi tutti gli utenti Internet usino la Rete come strumento economico e comodo per mandare messaggi ad amici e colleghi nel mondo. Invece di scrivere un messaggio, metterlo in una busta e spedirlo, lo si può mandare attraverso Internet a un qualsiasi utente, ovunque si trovi. Come si è visto nel tutorial precedente, la posta elettronica definisce un protocollo ad alto livello, SMTP, che detta la struttura dei messaggi, imponendo ad esempio che tutti i messaggi portino all'inizio una serie di informazioni di servizio che il mittente deve fornire.
Ecco l'intestazione "reale" di un messaggio di posta:
Date: Tue, 18
Dic 1997 17:25:42 GMT
From:
MIFAV@roma2.infn.it <br>
To:
polo@ips.it, petronio@axrma.uniroma1.it, dim2319@iperbole.bologna.it,
pecci@comune.prato.it, aft@comune.prato.it, ministro@murst.it,
galcivmo@comune.modena.it, amodio@zeus.idis.unina.it.
Subject: Annuncio
Per chi è interessato alle possibili applicazioni di Internet in ambito aziendale, i vantaggi di un sistema di posta elettronica sono ovvi. Anzitutto ha la posta elettronica ha molte più funzionalità della posta tradizionale: si può usare per trasmettere file, per aderire a gruppi di discussione via rete, a riviste in forma elettronica; per avere copie omaggio di programmi e file multimediali. Inoltre si tratta di uno strumento veloce e poco costoso, a volte più economico che mandare un messaggio per posta ordinaria. Ci sono molti programmi per la gestione della posta elettronica; alcuni di essi, tra cui quelli incorporati in Netscape Navigator e Microsoft Explorer, oltre all'invio e alla ricezione di messaggi consentono anche l'invio di file e la risposta automatica. Comunque, bisogna guardarsi dai pericoli di incomprensioni ed equivoci causati da questo nuovo mezzo di comunicazione.
La funzione Reply
La risposta automatica è una funzionalità offerta da quasi tutti i programmi di e-mail. Quando si osserva la lista dei messaggi ricevuti, in realtà si guardano, in forma compatta, le intestazioni dei messaggi. Come visto, si tratta di brevi descrizioni che comprendono la dimensione del messaggio, la data, il destinatario, il mittente e così via. Dopo aver fatto clic una volta su una di queste intestazioni, in modo da selezionarla, basta fare clic sul pulsante di risposta e comparirà una finestra dove nel posto dell'indirizzo del destinatario compare quello del mittente del messaggio precedente. Forse l'unico vero lato negativo della posta elettronica è che il sistema non è sicuro; ciò significa che altri possono leggere il testo che si riceve o che si spedisce. Nel seguito del corso vedremo come difendere la privatezza dei nostri messaggi.
SMTP (Simple Mail Transfer Protocol) e POP (Post Office Protocol)
Come sappiamo, il protocollo definito dal servizio di posta elettronica si chiama SMTP (Simple Mail Transfer Protocol); quasi tutta la posta su Internet viene trasportata da un punto all'altro usando questo protocollo.
SMTP definisce il formato del contenuto della posta, compresa l'intestazione e la formattazione del corpo testo. Inoltre, definisce come come inoltrare i messaggi partendo dal computer del mittente fino ad arrivare alla macchina (detta mailer) di raccolta posta della rete di destinazione.
Una volta giunti è compito di un altro protocollo, il POP o Post Office Protocol (vedi seguito) portare il messaggio sul personal del destinatario (ammesso che questo personal NON sia un mailer). E' interessante notare che SMTP è un protocollo a 7 bit. In altre parole, tutti i caratteri inviati utilizzando SMTP devono avere un codice ASCII minore di 127. Per il testo solitamente non esistono problemi; diventa difficile riuscire a inviare dei grafici, dei programmi o altri file binari. Ecco perché spesso vengono usati dei metodi di codifica come ad esempio uuencode e BinHex. Questi metodi "impacchettano" i dati a 8 bit in partenza in un flusso di dati a 7 bit e li estraggono di nuovo dall'altro lato. Per ovviare a questo limite di SMTP è stato definita l'estensione MIME: Multipurpose Internet Mail Extensions che consente di trasmettere file binari come messaggi di posta.
Non tutti i programmi di posta riconoscono i file MIME; ecco perchè per leggere la posta è consigliabile l'uso di Netscape ed Explorer.
POP è diventato necessario perchè ben pochi computer di oggi agiscono come mailer; anzi spesso ce n'è uno solo per edificio. Il motivo è semplice: spesso i personal computer non sono accesi e quindi non possono ricevere la posta. Per usare la metafora dell'ufficio postale, il mailer (computer sempre accesi) è l'ufficio postale e il personal computer è il destinatario. Quando la posta arriva, viene inserita nella memoria dell'ufficio postale e quando la si vuole controllare bisogna collegarsi con l'ufficio postale, scaricare la propria posta e poi sconnettersi. Dopo averci dato i nostri messaggi, l'ufficio postale può cancellare la sua copia.
Posta verso altre reti
Nonostante le differenze che abbiamo delineato nel tutorial precedente, Internet e FidoNet hanno qualcosa in comune: esiste già da parecchi anni un gateway funzionante, realizzato ed installato negli USA, il quale consente il passaggio di e-mail tra le due reti (mentre per le news, di cui ci occuperemo tra breve, attualmente non esiste alcun gateway ufficiale). Per spedire un messaggio personale da Internet verso FidoNet bisogna ovviamente conoscere nome ed indirizzo del destinatario (ad esempio: Mario Rossi, 2:332/317.1). Per determinare l'indirizzo Internet "fittizio" dell'utente FidoNet per prima cosa si sostituiscono nel nome gli spazi con dei punti (Mario.Rossi); quindi si prendono in ordine inverso i quattro numeri che compongono l'indirizzo FidoNet, inserendo tra un numero e l'altro i caratteri p, f, n, z. Così, 2:332/317.1 diventa p1.f317.n332.z2. Infine si aggiunge il suffisso .fidonet.org. L’indirizzo "fittizio" risulta quindi Mario.Rossi@p1.f317.n332.z2.fidonet.org. Vi assicuro che è più difficile a dirsi che a farsi... Per inviare invece un messaggio da FidoNet ad un utente Internet il metodo è molto più semplice: il messaggio va indirizzato a UUCP sul nodo 1:105/42.
Nella prima linea si scrive To: seguito dall'indirizzo Internet del destinatario.
Questo punto di collegamento realizza quindi una interconnessione permanente tra Internet e la galassia FidoNet, anche se ovviamente l'efficienza è notevolmente inferiore rispetto ad una mail su Internet (capita molto spesso che un messaggio impieghi più di due o tre giorni per giungere al destinatario).
La connessione remota: Telnet
L'utility Telnet è stato uno dei primi strumenti disponibili su Internet. Telnet, che si basa sull’omonimo protocollo descritto nelle lezioni precedenti, permette agli utenti autorizzati di collegarsi ad altri computer appartenenti a Internet ed eseguire i programmi presenti su di essi. Grazie a pochi comandi, l'utente autorizzato può collegarsi a un computer remoto, chiedere e ottenere l'accesso e poi comportarsi come se fosse seduto davanti al computer stesso, mandando in esecuzione i programmi che vuole.
Una volta che l'indirizzo numerico Internet del computer da raggiungere è noto, se Netscape e/o Explorer sono ben installati e corredati dei programmi aggiuntivi necessari, effettuare il collegamento è facilissimo; anzi, spesso è sufficiente conoscere il nome.
Basta infatti digitare telnet:// seguito dal nome del computer a cui ci si vuole connettere per lanciare (dall'interno di Netscape o Explorer) un programma client che si collegherà al computer remoto. Anche se per l'utente occasionale non è molto utile, Telnet è un servizio che si è rivelato prezioso per l'uso di Internet da parte di ricercatori e scienziati, consentendo loro di lavorare insieme e condividere risorse.
Accesso come ospiti
La gran parte dei computer presenti su Internet è protetta da parole d'ordine (password) contro gli accessi non autorizzati via Telnet. Alcuni di essi consentono però connessioni temporanee anche a utenti ospiti; solitamente permettendo loro di usare un numero ristretto di funzioni. In questi casi, viene richiesto di fornire il proprio indirizzo di posta elettronica come password; altre volte invece bisogna fornire un nome utente convenzionale come anonymous o guest. Spesso sono necessari parecchi tentativi; comunque osservando le informazioni che vengono visualizzate sullo schermo si può imparare qualcosa sulle procedure adottate sul computer remoto. Se siete collegati a Internet e disponete di Netscape o Microsoft Explorer potete provare l'ebrezza di avere sotto le vostre dita la tastiera di un computer in America, e vedere la qualità della configurazione del vostro browser aprendo l’indirizzo (digitando l’indirizzo direttamente nella finestrella nella parte superiore della finestra)
Nome utente e password sono entrambi "e-math": Poi, cercate di orizzontarvi tra i menu dedicati ai matematici membri della American Mathematical Society.
Il trasferimento di archivi: FTP
Il servizio FTP (File Transfer Protocol ovvero Protocollo di Trasferimento Archivi) serve principalmente per scaricare archivi da computer remoti.
I file possono essere di testo, software, giochi, archivi scientifici e tutto ciò che si può immagazzinare in un computer. Come abbiamo visto nella lezione precedente, per usare FTP bisogna conoscere il nome o l'indirizzo IP del computer a cui si vuole accedere.
Alcuni servizi FTP richiedono parole d'ordine, ma non tutti. Molti contengono dati e programmi appositamente scritti per essere di pubblico dominio e pertanto sono ad accesso libero. Corrispondentemente, ci sono due modi di utilizzo per FTP: l'Anonymous FTP (o FTP pubblico) e il Full Service FTP (o FTP privato). Quest'ultimo entra in gioco quando si è utenti registrati su due diversi computer di Internet e si vogliono trasferire dei file dall'uno all'altro. Ad esempio, è possibile trasferire un file da una directory di un altro computer associata al vostro a cui avete accesso. Dovete semplicemente includere il vostro nome utente e la vostra password, come nell'esempio che segue. Supponiamo che il vostro nome utente su un'altra macchina sia joe@idaho.com e che la password sia XK!3s.
Allora l'URL appropriato per trasferire via ftp un file chiamato story.txt da una directory del vostro account è ftp://joe:XK!3s@idaho.com/story.txt.
Usando Netscape o Explorer, per accedere a un server FTP ci si collega automaticamente con il nome utente anonymous; e si utilizza il servizio FTP pubblico. Collegandosi a un server FTP, si può consultare l'elenco delle directory contenenti il materiale pubblico; molti server hanno organizzato questi dati per categorie, ma FTP non fornisce nessun aiuto nella ricerca: il suo compito si limita alla trasmissione dei dati. Per questo motivo si può specificare se si tratta di dati binari (binary, come ad esempio un programma eseguibile) oppure di un file di testo (ascii). Usando Netscape o Explorer, comunque, FTP è in grado di capire da solo la natura dei dati.
L'uso di FTP richiede che l'utente sappia le risorse disponibili sui vari siti della rete. Questo può apparire problematico, ma per fortuna esiste un altro strumento in grado di indicizzare i file presenti sui diversi server FTP sulla base dei loro nomi. Si tratta del server Archie.
Archie
Il servizio Archie ha una funzione specifica su Internet: interrogare tutti i server Anonymous FTP sui loro contenuti per costruire un catalogo alfabetico. Questo repertorio servirà poi agli utenti per localizzare l'informazione in ambiente Internet. Visto che ci sono migliaia di FTP server, non è certo possibile cercare un certo file dappertutto; ma grazie a Archie, si può consultare un elenco completo. Per provare andate a:
http://services.bunyip.com:8000/products/archie
ZIP, TAR e altri file compressi
Molti file che si trovano su un sito FTP sono compressi in qualche modo, così occupano meno spazio su disco e viaggiano più velocemente sulle connessioni Internet. I file dei personal computer di solito sono compressi in un formato .ZIP che richiede di decomprimerli con WinZip o PKZip. I file Macintosh generalmente sono compressi nel formato .SIT o HQX che comportano l'utilizzo di StuffIt Expander per decomprimerli. Ecco un elenco di altri formati compressi che si possono incontrare:
.Z Compresso con un programma di compressione UNIX
.z Compresso con un programma del pacchetto di UNIX
.shar Archiviato con l'archivio shell di UNIX
.tar Compresso con tar di UNIX
.pit Compresso con PachIP di Macintosh
.zoo Compresso con Zoo210
.arc Compattato con PKARC per DOS
.exe File .ZIP ad auto estrazione per personal computer
.hqx Mac BinHex
.sea File .SIT ad auto estrazione per il Macintosh
Quando si scaricano dei file, ci si assicuri che possano girare sulla propria macchina. In altre parole, se si ha un personal computer Windows, si eviti di scaricare inutilmente un file .SEA o .SIT Macintosh. La maggior parte dei siti FTP contiene anche le utility necessarie per decomprimere i file; cercatele nella directory /UTIL. Se non riuscite a trovare le utility di decompressione che servono, controllate la lista di Stroud al sito
oppure Tucows all'indirizzo
Il caricamento di file
Oltre a prendere dei file dai siti FTP è possibile anche copiare i propri su alcuni siti. Questo consente di spedire lo shareware preferito o consegnare ai responsabili del sito un lavoro o delle informazioni recenti; ovviamente, per caricare i file su un sito occorre avere l'autorizzazione e quindi si tratta di sessioni FTP private.
E' possibile caricare i file con uno dei due metodi seguenti. Il modo più semplice è spostarsi sul sito FTP nella directory in cui si vuole porre il file e poi trascinare l'icona del file, da Windows Explorer o File Manager, nell'area di visualizzazione del browser.
Se questa procedura non soddisfa, in Netscape 3.0 e successive si può usare il comando File/Upload File e usare la finestra di dialogo che compare per copiare il file sul server di FTP.
I gruppi di discussione: Usenet
I lettori di news sono programmi che consentono una facile consultazione dei messaggi inviati ai vari gruppi di discussione Usenet.
Usenet è una sorta di rete a connettività intermittente, che trasferisce da un computer all'altro della Rete le discussioni sui più vari argomenti, composte dagli interventi degli utenti inviate via posta elettronica. Per ogni argomento c'è un gruppo. I programmi lettori di news, oggi incorporati in Netscape e Explorer, divennero indispensabili quando il numero dei gruppi crebbe a dismisura. Questi programmi raccolgono i messaggi solo dai gruppi di interesse del singolo utente, e li organizzano in modo da agevolare la consultazione.
C'è anche modo di contribuire alla discussione via posta elettronica. I vari gruppi di Usenet forniscono direttamente le informazioni su come contribuire al dialogo e i più comuni interrogativi (FAQ: frequently asked questions) sull'argomento in discussione. Sono disponibili anche elenchi aggiornati dei gruppi presenti sulla rete. Usenet è una parte molto dinamica di Internet e tra i gruppi c'è una natalità e una mortalità particolarmente elevata. Usenet non è organizzata in modo centralizzato e non c'è controllo su chi invia o riceve gli articoli, ma qualunque interesse si abbia, si può stare certi che su Usenet c'è un gruppo che se ne occupa.
I gruppi
Le news sono suddivise in sette grandi categorie che corrispondono ad altrettanti argomenti. Alcuni gruppi hanno migliaia di utenti mentre altri ne hanno una dozzina o anche meno.
News Gruppi che si occupano delle novità della rete e dell'amministrazione di sistema.
Soc Gruppi che si occupano di problemi sociali.
Talk Gruppi di discussione finalizzati al dibattito su temi vari.
Misc Gruppi che si occupano di argomenti di varia natura, non facilmente classificabili.
Sci Gruppi riguardanti la discussione sulle applicazioni della scienza.
Comp Gruppi che discutono teoria e applicazioni dell'informatica
Rec Gruppi che discutono di arte, di tempo libero e di attività ricreative.
Oltre a questi, c'è un insieme di gruppi in rapida espansione il cui argomento è meno formale e tradizionale. Eccone un elenco:
Alt Gruppi che discutono temi scabrosi, controversi o semplicemente frivoli.
Biz Gruppi che discutono temi inerenti le imprese e gli affari in generale.
Iee Gruppi che discutono di temi relativi all'ingegneria elettronica ed elettrotecnica.
K12 Gruppi che discutono su temi pedagogici dell'insegnamento elementare e medio.
Usenet è un sistema gerarchico: ognuno dei grandi gruppi ha decine di sottogruppi, che a loro volta sono ulteriormente suddivisi. Ad esempio: soc.culture.italian individua il gruppo che si occupa di cultura e società italiane. E' in lingua inglese e frequentato da italiani e stranieri.
Esercizio (15 punti)
Scoprite come collegarvi a Usenet usando il vostro programma Netscape o Explorer (suggerimento per chi usa Netscape: guardate sotto l'opzione “Window”) e mandate al tutor via posta elettronica il contenuto dell'articolo più recente del gruppo soc.culture.italian. Se non riuscite aspettate la prossima lezione...
Dai nomi "semplici" agli URL
Tutti i server di Rete elencati in questo corso sono individuati da un indirizzo nel formato esteso detto Uniform Resourse Locator (URL). Questo tipo di indirizzo NON è la stessa cosa del nome di un computer della Rete, perchè individua un server (ovvero, un servizio remoto) e NON un generico computer. L'aspetto dell'indirizzo di una risorsa Internet (URL) può sembrare a prima vista ostico, come in questo caso:
telnet://archive.cis.ohio-state.edu:8888
Invece di separare le varie parti di un indirizzo mettendole su linee diverse, come su una busta, in Internet si dividono gli elementi tipograficamente usando punti (.), due punti (:) e barre (/).
Ma che relazione c’è tra i nomi "normali" e gli URL?
Ricordate che, così come il mondo è composto da continenti, nazioni e regioni, Internet è divisa in domini e sottodomini. Le nazioni corrispondono ai domini di livello più alto; per esempio, il dominio Italia è contrassegnato da .it e il Giappone da .jp.
I domini principali negli Stati Uniti sono, oltre a .edu,
.gov per le istituzioni accademiche e governative
.com per le ditte commerciali
.mil per i militari e così via.
L'indirizzo è costruito da sinistra a destra, partendo dall'informazione più specifica per arrivare alla più generale. Le URL aggiungono un'informazione importante: il tipo della risorsa, ovvero lo strumento di ricerca con cui la risorsa va consultata. La parte iniziale di un indirizzo URL identifica infatti lo strumento da usare. Ecco un elenco:
telnet:// Usare un client (esterno) Telnet per accedere alla risorsa.
gopher:// Usare un client (esterno) Gopher.
ftp:// Usare il client (incorporato) FTP.
Attenzione: Tutti i programmi client esterni dovrebbero essere già stati installati insieme alla vostra copia di Netscape Navigator o Microsoft Explorer. Ma non è detto...
Struttura di un Uniform Resource Locator (URL)
Vediamo ora un esempio di indirizzo URL completo e una spiegazione degli elementi che lo compongono:
ftp://archive.cis.ohio-state.edu:8080
La coppia di barre // che seguono l'identificativo del programma client da usare sono il modo standard di separare il nome del programma di accesso da quello della risorsa. Come sappiamo, archive.cis.ohio-state.edu è il nome che identifica uno specifico computer su Internet. Anche se su Internet i computer hanno numeri identificativi, gli indirizzi IP (ad esempio, 194.20.36.1), questi indirizzi si usano raramente perché sono difficili da ricordare; in alternativa si impiegano i nomi che vengoono poi tradotti nei numeri corrispondenti da parte dei computer detti name server .
Nel nostro caso, il computer archive è collegato alla rete cis. Da lato suo, cis è una sottorete dalla rete di ateneo della Ohio State University, che si trova nello Stato dell'Ohio.
Il suffisso .edu (educational) ci rivela che si tratta di un'Università.
Infine, :8080 è il numero di port, che identifica uno specifico programma server in esecuzione a quell'indirizzo di rete. Non è necessario specificare questo numero per usare gli strumenti standard di accesso, poichè il well-known port del servizio è sempre sottinteso; ad esempio, Gopher usa il well-known port 70. Se l’utente non indica un tipo di server, il prefisso dell’URL che indica il tipo viene convertito in un numero di porta standard che si invia automaticamente quando l'utente manda la richiesta al server. Anche se questo schema di indirizzamento può sembrare complicato, con l'esercizio diventa facile da usare e anzi è una guida preziosa per stabilire la natura e la posizione delle organizzazioni con cui si entra in contatto. Ecco un altro URL interessante da provare :
http://www-mitpress.mit.edu/City_of_Bits/contents.html
Quest'URL è l'indice di un libro interattivo di William J. Mitchell chiamato "City of Bits: Space, Place, and the Infobahn", con cui è divertente giocare. L'URL principale di questa pubblicazione è : http://www-mitpress.mit.edu/City_of_Bits/
Alla scoperta di Gopher
Gopher è il nome di un simpatico animaletto simile alla marmotta, il citello, che è il simbolo dell'Università del Minnesota. Su Internet, si tratta di un tipo di server molto importante che è contemporaneo al World Wide Web, ma si è diffuso molto prima. Molti database utili oggi presenti Web sono nati come server gopher. Gli URL Gopher sono un po' più complessi degli URL normali. Ogni risorsa Gopher, o oggetto ha un tipo di codice Gopher. Ecco una lista dei tipi Gopher:
0 file
1 directory
2 CSO server rubrica telefonica
4 BinHex file Macintosh
5 file binario DOS
6 file UNIX codificato uuencode
7 indice
8 sessione telnet
9 file binario.
T sessione terminale TN3270
s file sonoro.
g immagine GIF
M formato MIME.
h file html (pagina Web)
I immagine generica
Un URL Gopher, quindi, è simile ad un URL normale, con la differenza che ha un tipo che compare subito dopo i doppi slash che separano il tipo di risorsa dal nome del computer su cui si trova. Ecco l’URL gopher per un file di testo chiamato road :
gopher://gopher.csi.unimi.it:70/00/road
Potete aprirlo con Netscape o Explorer e visitare così il server Gopher dell'Università di Milano E' da notare che il tipo di oggetto 0 che indica un file è ripetuto due volte immediatamente dopo il nome del computer gopher.unimi.it. Il bello di Gopher è che, una volta entrati in un server, si possono consultare i dati senza dover necessariamente sapere il computer su cui si trovano, cioè senza conoscere il nome o l’URL. Infatti, facendo clic su un oggetto si accede ad esso indipendentemente dal computer su cui si trova, che può essere lo stesso da cui si è partiti oppure un altro, posto all’altra estremità del globo. Poichè non richiede una conoscenza dell'indirizzamento sulla Rete, Gopher è lo strumento ideale per i nuovi utenti. I collegamenti tra i vari server Gopher sono invisibili all'utente, il che lo rende uno strumento estremamente facile da usare. Per provare a fare un viaggio nel "gopherspazio" andate a
Veronica
Esaminare Internet con Gopher può essere divertente, ma non è consigliabile quando servono urgentemente delle informazioni specifiche. E' necessario un metodo per trovare solo quei siti Gopher che hanno i dati che interessano. Con Veronica si digitano le stringhe di ricerca che le comunicano cosa cercare e quanti elementi trovare. Veronica esamina il suo lunghissimo indice di risorse Internet e poi riunisce un menu di server che corrispondono alla stringa di ricerca. Ad esempio si può inserire una stringa di ricerca per far sì che Veronica trovi tutti i siti che contengono delle informazioni su IBM e Apple.
La prima fase di ricerca, e anche quella che occupa più tempo, consiste nell'accedere a un server Veronica. Ciò che rende quest'operazione così difficile è che i server di Veronica sono molto richiesti e può capitare di non riuscire a ottenere l'accesso proprio quando serve. Il metodo più semplice comunque trovare un server di Gopher che ha un collegamento a Veronica e fare clic su di esso. A volte l'elenco dei siti di Veronica è diviso in due gruppi: uno permette di cercare tutto il gopherspazio e l'altro solo le directory. Per una ricerca rapida che dà pochi risultati, si selezioni una delle opzioni Directory Only; per una ricerca più completa si selezioni l'opzione Gopherspace. Indipendentemente da quale scelta si faccia, Veronica visualizza un modulo che permette di immettere la stringa di ricerca. Si faccia clic all'interno della casella di testo, si digitino le parole che si vogliono cercare e si prema Invio. Se ad esempio si digita "letteratura spagnola" Veronica cerca tutte le voci che hanno "spagnola" e "letteratura" nel titolo, ma non necessariamente nell'ordine in cui le parole sono state digitate; scopre anche ogni occorrenza di "letteratura" e "spagnola". Si faccia quindi in modo che la stringa di ricerca sia più specifica possibile.
Le mailing list
Le mailing list non sono native di Internet; sono un servizio nato parecchio tempo fa sulla rete BITNET, che collegava (e collega!) le istituzioni accademiche e governative europee che dispongono di grandi computer IBM.
Una mailing list è semplicemente un programma che distribuisce messaggi via e-mail a un elenco di abbonati. In alcuni casi si tratta di vere e proprie riviste elettroniche. Il programma di distribuzione ha un indirizzo di posta elettronica (nel formato nomelista@dominio) e i messaggi inviati a quell'indirizzo vengono smistati a tutti gli abbonati. Questi programmi servono da punto d'incontro tra le persone interessate a un argomento (ad esempio i database o la cristallografia) consentendo a ciascun membro della comunità di inviare avvisi o comunicazioni a tutti gli altri.
Ci sono due tipi di mailing list: quelle gestite manualmente e quelle automatiche.
Quelle manuali sono gestite da una persona, detta list administrator. Per abbonarsi a una lista di questo tipo bisogna chiederlo via mail all'administrator, che di solito ha un suo indirizzo di posta del tipo
nomelista-request@dominio
Le liste automatiche sono gestite da un processo server (detto mailserver, da non confondere con il mailer visto in precedenza). Per abbonarsi bisogna mandare un messaggio di posta elettronica all'apposito indirizzo del mailserver (che non è lo stesso della lista). Di solito il messaggio per abbonarsi è SUB nomelista Proprionome Propriocognome
per cessare l'abbonamento, basta inviare allo stesso indirizzo il messaggio SIGNOFF nomelista.
Il mailserver legge il messaggio, riconosce che contiene istruzioni per lui e le esegue. Ovviamente, si può fare ben di più che semplicemente abbonarsi o cessare l'abbonamento; per sapere la lista di istruzioni accettate da un mailserver basta inviargli un messaggio con l'istruzione HELP (In alcuni rari casi bisogna invece mandare un messaggio vuoto con HELP come subject).
LISTSERV è il tipo più diffuso di mailserver presente su Internet. Per conoscere le istruzioni accettate dai LISTSERV bisogna procurarsi un manuale, per esempio mandando il comando INFO GEN a uno di essi. Come abbiamo visto, il comando HELP fa sì che listserver vi invii una lista abbreviata di comandi, INFO GEN chiede le informazioni generali mentre INFO REFCARD ottiene la lista di comandi completa.
E' molto importante avere capito bene la differenza tra indirizzo della lista e indirizzo del gestore della medesima. NON MANDATE MAI messaggi contenenti comandi all'indirizzo della lista: non verrebbero affatto eseguiti ma inoltrati a tutti gli abbonati! Ovviamlente, vi sono parecchi altri comandi oltre a quelli visti finora. Ad esempio, l'elenco completo delle riviste scientifiche accessibili via Internet è contenuto nel documento "Directory of Electronic Journals and Newsletters" che è ottenibile dalla mailing list LISTSERV@UOTTAWA.BITNET con i comandi get Ejournl1 Directory (prima parte) e get Ejournl2 Directory (seconda parte).
Come rintracciare la lista desiderata
Ci sono varie liste di liste che si possono consultare per trovare la lista che tratta di un argomento di proprio interesse. Eccone l’elenco:
1 - la cosiddetta "madre di tutte le liste" che elenca tutti i programmi LISTSERV su BITNET
2 - la lista degli interest-group
3 - servizi analoghi ai LISTSERV ma posti su Internet
4 - le liste dei newsgroup di USENET
5 - la lista Publicly Accessible Mailing Lists disponibile via USENET
6 - l'elenco Directory of Scholarly Electronic Conferences (ACADLIST), un riepilogo di mailing lists, newsgroup, bollettini, riviste scientifiche di grandissimo interesse per chi opera nell'ambiente universitario.
Vediamo in dettaglio come procurarsi questi elenchi.
La "madre di tutte le liste"
La madre di tutte le liste LISTSERV contiene le descrizioni (lunghe una linea) di tutte le liste gestite da LISTSERV e presenti su BITNET. Quasi tutti i LISTSERV possono fornirne una copia inviando loro il comando LIST GLOBAL
E' anche possibile precisare il comando inviando LIST GLOBAL /stringa (e.g. LIST GLOBAL/filosofia) per ottenere l'elenco delle liste che hanno ma stringa specificata (nell'esempio"filosofia") nella loro descrizione.
All’indirizzo ftp://sri.com/netinfo si può avere la lista degli interest-group ossia delle mailing list di Internet (attenzione: la lista è più di 1.2 MByte !)
Per quanto riguarda Usenet, ci sono due liste dei gruppi di discussione. La prima si chiama List of Active Newsgroups ed elenca i gruppi di discussione regolari
I gruppi alternativi (bionet, .alt, bit.listserv e simili.) sono invece elencati in Alternative Newsgroup Hierarchies. Entrambi gli elenchi contengono descrizioni di una riga. Un altro elenco interessante è Publicly Accessible Mailing Lists che contiene brevi descrizioni degli scopi delle liste che elenca.
Oltre a essere distribuiti via USENET nei gruppi news.lists e news.answers (nomi dei file: active-newsgroups, alt-hierarchies e mailing-lists), questi file si possono anche scaricare via anonymous FTP all'indirizzo che segue:
ftp://rtfm.mit.edu/pub/usenet/news.answers
La
Directory of Scholarly Electronic Conferences (ACADLIST)
L' elenco ACADLIST (gestito dalla Kent State University) contiene descrizioni delle conferenze elettroniche che esistono su tutti gli argomenti accademici. "Conferenze elettroniche" è un termine vago che indica liste di discussione, gruppi di interesse, riviste scientifiche in forma elettronica e così via.
ACADLIST consiste di ben 8 distinti file di testo. I primi quattro contengono un elenco di aree d'interesse in ordine alfabetico. Ad esempio, FILE1 si intitola : Anthropology- Education, il che significa che comprende tutti gli argomenti le cui iniziali stanno tra A e E. La lista è disponibile anche in formato MS WORD. Per ottenere ACADLIST si può andare all’indirizzo ftp://ksuvxa.kent.edu
Come si cerca una lista in una lista di liste
Ci sono due modi di cercare informazioni (per esempio, una lista su un argomento di proprio interesse) in una di queste liste di liste: o si lavora on-line (cioè via Rete) oppure off-line, cioè dopo aver scaricato il file sul proprio computer. Spesso, viste le dimensioni dei file, si preferisce il primo metodo; per saperne di più inviate un messaggio con testo INFO DATABASE a un LISTSERV qualsiasi. Va notato che la biblioteca della Lund University (Svezia) mette a disposizione una versione di ACADLIST in cui si possono fare ricerche on-line. Provate a fare Telnet a uno dei seguenti indirizzi: quake.think.com (login: wais) nnsc.nsf.net (login: wais) swais.cwis.uci.edu (login: swais) sunsite.unc.edu (login: swais) info.funet.fi (login: info)
Tutorial 4
I file system di rete e lo schema client-server
In una rete aziendale o comunque locale, il protocollo TCP/IP di Internet può essere usato per fornire a ogni utente collegato alla rete la visione complessiva degli archivi sui vari dischi rigidi delle macchine collegate alla rete stessa. Ciascuna delle macchine connesse alla rete può avere una visione diversa del file system globale, costruita con il proprio file system locale ed un arbitrario sottoinsieme dei file resi visibili sui dischi degli altri computer collegati alla rete. Un fattore critico per questo tipo di realizzazioni è rappresentato dai permessi di accesso ai file remoti un utente che gode di tutti i privilegi d'accesso sul proprio sistema non dovrebbe in generale poter avere gli stessi privilegi per quanto riguarda i file remoti, soprattutto se la macchina in questione potrebbe essere oggetto di un uso non autorizzato. In molti casi si attribuiscono d'ufficio agli accessi remoti i privilegi (più o meno estesi) di un utente fittizio locale.
La struttura di NFS
Un esempio particolarmente significativo di sistema di rete per la gestione dei file è costituito dal Network File System della SUN, che ha avuto un notevolissimo successo commerciale. L'idea che sta alla base di questo sistema è che ciascun utente della rete deve potere aver accesso ai file remoti cui è interessato senza doverli trasferire esplicitamente sul proprio disco rigido locale. Usando NFS l’utente accede indifferentemente a un file remoto e a uno locale usando i soliti comandi del suo sistema operativo locale, Windows, Unix o MacOS che sia.
Il file system globale definito sulla rete ad opera di NFS non comprende tutti i file elencati nei vari file system locali. L'immagine del file system globale è invece stabilita dinamicamente ad opera degli utenti che possono specificare in ogni momento quelle porzioni del loro file system che devono essere visibili dagli altri utenti. La selezione di queste porzioni avviene tramite comandi come mountd che serve a configurare un nodo come server, ed exportfs che consente di specificare le parti del disco di un server che devono essere rese accessibili ai client. Da parte loro i client hanno a disposizione il comando mount per inserire nella loro visione del disco alcune delle porzioni di disco rese disponiibili dai vari server.
Un 'operazione di mount remota in NFS avviene quando per esempio la macchina SERVER rende visibile il sottoalbero PUBLIC del proprio disco con il comando
exportfs -a /PUBLIC
l'opzione -a indica che il sottoalbero potrà essere innestato nel disco di tutti gli utenti.
Nel nostro caso la macchina CLIENT ha innestato parzialmente questo sottoalbero collegandolo alla radice del proprio disco attraverso il comando
mount -t nfs SERVER/PUBLIC/data1
Si noti che in questo caso la macchina CLIENT avrà accesso alla sola directory data1. Ciò significa che i client, oltre a scegliere tra i sottoalberi messi a disposizione dai vari server possono installare selettivamente solo alcuni percorsi del sottoalbero prescelto. L'opzione -t nfs serve a distinguere l'operazione remota da quella locale. A questo livello infatti non è prevista la trasparenza di questa operazione agli occhi dell'utente. La sintassi utilizzata in questo esempio è quella disponibile quando NFS viene installato ad un nodo provvisto di sistema operativo Unix e ricalca quella prevista per le analoghe operazioni locali di questo sistema operativo. Va però chiarito che la stesse operazioni vengono realizzate in modo diverso (ad esempio tramite menù a tendina ed icone) su nodi su cui siano installati altri sistemi operativi come Windows e MacOS, senza che il meccanismo sottostante differisca in alcun modo da quello che abbiamo visto.
Il ruolo dei server
Una delle caratteristiche fondamentali di NFS è che i server non mantengono alcuna informazione di stato (questa proprietà si indica spesso con l'esotico nome di statelessness ) . Ciò significa che il server non conserva alcuna informazione sui file aperti ad opera dei client . L' assenza di un elenco di file aperti sul server fa sì che la funzionalità del sistema non venga compromessa da eventuali reinizializzazioni dei server, che come è intuibile sono molto frequenti nelle reti locali, dove i server sono spesso macchine non dedicate. Una rete NFS può comprendere un numero arbitrariamente alto di server e non vi è limite al numero di comandi mount che un singolo client può effettuare. Va però notato che un client che abbia eseguito il mount di un sottoalbero remoto non può renderlo visibile ad altri assumendo i panni del server questa scelta scongiura la possibilità che un client acceda ad un proprio file attraverso un circuito di mount remoti.
Capire la Rete l’uso di Ping
Molti di coloro che usano Internet hanno osservato differenze nelle prestazioni della Rete, a seconda dell'orario ma anche del luogo da cui ci si collega. In questo paragrafo cerchiamo di far luce su questi interrogativi fornendo gli strumenti per capire se la colpa dei rallentamenti è dell'intasamento di Internet o se invece è il vostro provider che "ci marcia".un po'. Come è già stato spiegato nel tutorial precedente quando i computer comunicano su una rete i dati (ad esempio i file da trasmettere via FTP) vengono inviati in piccole porzioni dette pacchetti. Su Internet i pacchetti possono essere composti da 500/1500 byte, anche se altre reti usano pacchetti più lunghi, fino a 8000 byte (si ricordi che 1 byte= 8 bit, ovvero otto cifre binarie). Durante la trasmissione c'è sempre il rischio che uno o più pacchetti vengano danneggiati a causa di difetti delle linee di trasmissione oppure di disturbi elettromagnetici causati da motori, luci e persino dalle trasmissioni radio e televisive.
Inoltre, bisogna considerare che per arrivare a destinazione i pacchetti devono attraversare le apparecchiature di smistamento di Internet, i router. Spesso all'ingresso del router si forma una vera e propria coda di pacchetti in attesa; quando questo dispositivo è intasato può semplicemente scartare (un'operazione che in gergo si chiama drop) i pacchetti in arrivo che non riesce a gestire.
Per essere sicuro che i pacchetti dei dati arrivino correttamente a destinazione, spesso il mittente si aspetta un pacchetto di conferma (ack) dal destinatario; se l'ack non arriva in un tempo ragionevole il mittente deduce che il pacchetto è andato perso e lo ritrasmette. Questa tecnica fa parte del protocollo TCP, che come sappiamo è alla base delle comunicazioni su Internet. Il tempo che passa tra l'invio di un pacchetto e la ricezione dell'ack viene chiamato dagli esperti round trip, ovvero "viaggio di andata e ritorno". Questo tempo di viaggio è la somma di due contributi.
- Il primo contributo è il tempo che il nostro computer ci mette a scrivere il pacchetto sulla rete; se il pacchetto è composto da un numero prefissato di bit questo tempo dà conto della velocità in bit al secondo della linea a cui il computer è collegato, ovvero la velocità con cui la linea può assorbire i bit che il nostro computer le invia.
- Il secondo contributo è il tempo effettivo di viaggio da mittente a destinatario (e ritorno) del pacchetto di bit una volta che lo si è scritto; questo tempo dipende dalla velocità di propagazione del segnale lungo le linee e dai ritardi introdotti ai punti di smistamento. Poi ci sono i ritardi di ritrasmissione se la percentuale dei pacchetti persi è inferiore al 2%, l'utente non se ne accorge nemmeno; percentuali superiori vengono percepite come un sostanziale rallentamento nel funzionamento di Internet, dovuto alle trasmissioni multiple che si rendono necessarie.
La gran parte degli utenti italiani di Internet sono collegati tramite modem (14.400 o 28.800 bps) sulla normale linea telefonica fino al proprio provider; dalla macchina del provider in poi le connessioni si estendono su linee di comunicazione digitali. Anche il primo tratto "ospitato" dalla rete telefonica, comunque, è conforme al protocollo TCP/IP impiegato dal resto di Internet (o meglio, a alla versione speciale detta PPP, Point-to-Point Protocol) e costituisce il percorso iniziale che sarà comune a tutti viaggi che i pacchetti provenienti dal nostro personal fanno su Internet, che siano diretti al sito della NASA o (perchè no?) a quello di Playboy. Possiamo paragonarlo al percorso in automobile che bisogna fare per arrivare a un aereoporto, da cui poi si decolla a bordo di un jet. Quando un collegamento si rivela troppo lento, viene naturale dare la colpa a questo primo tratto. Ma è sempre così ?
Alla ricerca dei pacchetti perduti
La prima causa di rallentamento, che può facilmente essere rilevata dall'utente, è senz'altro anche la più comune; basta disporre del programma Ping. Per attivare Ping da Windows selezionate Avvio, Esegui e poi digitate ping seguito da un indirizzo numerico IP nella casella che compare. La prima funzione di ping è rilevare la percentuale dei pacchetti perduti. Ping funziona così invia dei pacchettini "di sondaggio" e rimane ad aspettare la risposta del computer destinatario. Tutti i computer di Internet rispondono ai sondaggi di Ping, senza che i loro utenti debbano fare alcunchè. Queste conversazioni consentono a Ping la misura di un gran numero di parametri, tra cui la percentuale di pacchetti perduti. Se siete collegati a Internet via rete locale o via linea dedicata la percentuale dei pacchetti persi deve essere zero; per i collegamenti via linea telefonica commutata le percentuali possono anche essere superiori e dipendere dalle ore della giornata. Ecco quello che succede eseguendo un Ping alla macchina di un provider
Saved by Pingª 3.0.2 on
Gio, 14 dic 1997 230157
Packet Type Short ICMP
Echo
Testing device
194.20.36.9
Tested from
194.20.36.56, mask 255.255.255.0
Name Type Address
PercentDropped
calcio.telnetwork.it
Unknown 000.00.00.9 0.0
L'intestazione specifica la data, l'indirizzo di rete IP della macchina destinataria del sondaggio e di quella da cui è stata eseguita la prova. La riga ci dice il nome della macchina destinataria, il suo modello (non tutte le macchine lo rivelano) e la percentuale di pacchetti di sondaggio non pervenuti a destinazione. In ogni caso, se la percentuale di pacchetti perduti è maggiore di zero, vale la pena di rilevare più volte il valore delle perdite, facendo Ping successivamente a vari siti su Internet posti a grande distanza l'uno dall'altro. Se i valori rilevati in momenti successivi sono significativamente diversi, la colpa del rallentamento non è della linea telefonica locale, che è il tratto comune a tutti i percorsi esaminati.
Quindi non è detto che quando si accede a un sito Internet situato, poniamo, in America, il tratto più lento della connessione sia sempre quello realizzato via modem fino al vostro provider. Ma come rendersi conto di chi è veramente la colpa? Basta sapere che sulle connessioni lente (pochi bit al secondo) i pacchetti più lunghi (formati da molti bit) richiedono più tempo per essere trasmessi sulla linea; il computer trasmittente tiene conto di questo attendendo più a lungo l'ack di risposta prima di considerare perso un pacchetto. Ne consegue che i tratti lenti possono essere individuati dal mittente usando il programma Ping per misurare il round trip in modo differenziale. Ad esempio, si può rilevare il round trip da casa al proprio provider e poi da casa ai principali centri di smistamento Internet nazionali o internazionali (a patto di conoscerne l'indirizzo IP), e poi calcolare la differenza. Questo consente di valutare, sia pur molto grossolanamente, la qualità dei collegamenti di cui il nostro provider dispone.
Un’altra causa di rallentamento è la presenza di numerosi dispositivi di smistamento (i router) tra mittente e destinatario. Ogni router richiede però un tempo molto breve, da 0.1 a 10 millisecondi, per inoltrare ciascun pacchetto. Quindi, a meno di casi eccezionali, è difficile che sia questo il motivo principale del rallentamento; meglio passare per molti router su un percorso con tratti di linea veloci che transitare attraverso pochi su linee troppo lente. Anche il numero di router (detto hop number) attraversati dai pacchetti può comunque essere facilmente misurato con Ping da parte dell'utente.
Esercizio (10 punti)
Trovate e scaricate dalla rete un Ping shareware evoluto.
Come scegliere il provider
Per chi deve ancora collegarsi alla Rete un passo fondamentale è la scelta del provider. Anzitutto, bisogna fare una distinzione che sembra scontata, ma non lo è quella tra chi usa Internet per pubblicare informazioni e chi consulta la Rete per vedere quelle create dagli altri. Il primo caso riguarda le aziende che vogliono mettere il proprio catalogo su Internet; il secondo è quello della maggioranza dei privati. Anche se i collegamenti PPP sono offerti da tutti i provider, non è detto che uno valga l’altro. Ecco alcuni criteri per una scelta oculata
Rivolgetevi a ogni provider della vostra zona via fax, chiedendo le tariffe e ponendogli le domande suggerite nel seguito. Diffidate di chi rifiuta di fornirvi queste notizie. Tenete conto della posizione geografica un provider di provincia può fornire un buon servizio anche se non ha le grandi macchine indispensabili per il bacino d’utenza di Roma o Milano.
Le cinque domande
1) Chiedete il rapporto tra il numero di linee telefoniche del provider e gli abbonati. Più è basso, maggiore è la probabilità di trovare il telefono occupato nelle ore di punta. Fatevi dire la velocità massima di collegamento in commutata (dovrebbe essere almeno 28.800 bps) e quanti sono i modem del provider che effettivamente la supportano. Infine, occhio al futuro anche se oggi il tipo di connessione più diffusa è quella via linea telefonica, stanno assumendo importanza i collegamenti ISDN. Per un provider, offrirli già ora è un’ottima referenza.
2) Fatevi dire la configurazione delle macchine del provider. Molti provider improvvisati usano dei computer con poca memoria installata (16 Mbyte o meno). Una soluzione economica ma inadatta a chi ha più di 8 linee telefoniche, soprattutto se un solo computer fa da server PPP (cioè, ´risponde al telefono’), da server per il World Wide Web e gestisce anche la posta elettronica. Un provider serio disporrà di una workstation RISC o di più personal computer, ben dotati di memoria.
3) Domandate se è presente un proxy-server. Il proxy server, funziona così quando un utente richiede un’informazione da una macchina remota, il proxy si fa trasmettere anche tutte le altre informazioni a essa collegate, nella presunzione che l’utente finirà poi per richiederle. Più grande è il disco del proxy-server, maggiore è la possibilità che tutte le richieste dopo la prima siano soddisfacibili localmente e quindi più in fretta.
4) Importante è la velocità (e la tipologia) delle linee che collegano il provider al resto di Internet. Se un provider offre ai clienti connessioni PPP via modem a 28,8 Kbps e dispone egli stesso di una connessione a soli 64 Kbps con la Rete vuol dire che spera che le connessioni degli utenti risultino più lente del valore nominale. Probabilmente la speranza è giustificata, poichè in genere la velocità effettiva è una frazione di quella nominale. Comunque, questo trucco ricorda quello delle compagnie aeree, che vendono più posti sui voli di quanti ce ne siano nella ´certezza’ che qualcuno non si presenterà. La tipologia della linea tra il provider e Internet dev’essere almeno CDN (linea dedicata digitale) a 64 Kbps per i piccoli provider, anche se i più grandi ne hanno una da 2 Mbps. Infine, domandate se il provider ha un collegamento internazionale o sfrutta quello di un provider più grande, e se ha attivato connessioni dirette (peering) con altri provider italiani.
5) Domandate se il provider fornisce agli utenti il software di collegamento. Fatevi dire se l’installazione è automatica o se richiede che siate voi a eseguire la configurazione. Alcuni provider sono disponibili a mandare qualcuno a farlo per voi, gratis o per una cifra modica. Privilegiateli, anche se quest’aiuto non vi serve la presenza del servizio indica disponibilità verso la clientela.
Le caratteristiche tecniche non sono tutto, poichè un provider deve essere anche un buon consulente. Chiedete se è prevista l’assistenza telefonica e se si tengono corsi di formazione. Se avete un amico che dispone già del collegamento, approfittatene per consultare i siti Web dei vari provider della zona. Un sito Web ben curato indica che il provider ha solide competenze in casa. I migliori provider consentono ai clienti di avere una propria pagina Web gratis o a un prezzo simbolico sul loro server.
Infine, parliamo dei prezzi. Diffidate degli abbonamenti a basso prezzo con un limite di tempo. Gli utenti di questi abbonamenti sono spesso penalizzati per indurli all’abbonamento a prezzo pieno. Leggete attentamente le condizioni contrattuali. Non scegliete l’offerta più economica, ma guardate il complesso delle risposte alle domande suggerite in precedenza. Gli investimenti si pagano, e un provider troppo economico può essere sottodimensionato.
Consigli per le aziende
Se siete dirigenti, imprenditori o professionisti e state valutando l’idea di avere un accesso a Internet aziendale, probabilmente desiderate usare Internet per pubblicare delle informazioni. Tentando una schematizzazione possiamo dire che la gran parte delle imprese è interessata al Web a uno dei seguenti livelli
1 Pura presenza In questo caso si desidera solo che il marchio aziendale e magari un esempio di prodotti siano visibili sulla Rete in modo da non perdere in immagine nei confronti dei concorrenti. Le informazioni da pubblicare sono limitate a quelle necessarie per prendere contatto con l’azienda con altri mezzi (telefono o fax)
2 Comunicazione aziendale Alcune aziende desiderano legare più strettamente la propria immagine a quella della Rete, usando il Web come punto di colloquio con la propria clientele vecchia e nuova, a cui vengono presentate le novità produttive e le notizie aziendali. spesso si desidera che il cliente possa usare la Rete per comunicare con l’azienda, fornendo i suoi dati e ponendo domande.
3 Commercio elettronico Alcuni settori produttivi come quelli informatici o l’elettronica di consumo (hi-fi, video cassette e simili) sono adatti per una commercializzazione diretta dei prodotti via Rete. In questo caso occorre presentare l’intera produzione e gestire ordini e pagamenti direttamente su Internet
4 Intranet Avere un’Internet in piccolo, all’interno della propria azienda, si è già rivelata un’idea vincente per molte imprese. Di Intranet parleremo ancora nei prossimi tutorial.
Nei primi tre casi, è possibile (anzi, consigliabile) che l’azienda si limiti a fornire il contenuto informativo, lasciando al provider di fiducia il compito di presentarlo su Internet e di raccogliere le informazioni provenienti dalla clientela. Infatti, anche se l’azienda dispone di una connessione su linea commutata, questa non può essere usata per pubblicare informazioni, non solo perché è può essere lenta, ma soprattutto perché il numero IP di una macchina collegata su linea commutata cambia ogni volta che ci si collega. Questo rende la connessione via linea commutata inadatta alla pubblicazione di informazioni, visto che il pubblico deve disporre del nostro nome (oppure dell’indirizzo IP) per venirci a trovare. I provider sono in grado di "ospitare" presso le loro sedi la presenza in rete di più aziende grazie a una tecnica detta multicollegamento o multihoming che sfrutta la capacità di un computer fisico di "impersonare" più computer virtuali. Nel quarto caso, le macchine interessate sono quelle interne all’azienda; se poi si vuole che la propria Intranet privata sia collegata comunque a Internet, occorre disporre di una connessione permanente con tanto di router aziendale.
Guida alla connessione permanente
Per avere un collegamento permanente a Internet bisogna anzitutto affittare una linea dedicata tra la propria sede e il provider che fornisce il punto di accesso alla Rete. Ci sono due tipi di linee dedicate quelle digitali (nate per il trasporto dati) e quelle analogiche (nate per il trasporto della voce, ma utilizzabili anche per i dati grazie ad appositi modem). Contrariamente a quanto molti credono, il mercato italiano delle linee digitali è già oggi in regime di libera concorrenza; per affittarne una potete rivolgervi a Telecom o optare per altri fornitori, come Infostrada del Gruppo Olivetti. Qualunque vettore scegliate, è possibile affittare linee digitali a partire da 19,2 o 64 Kbps fino a 2 Mbps ed oltre, a prezzi che vanno da alcune decine a centinaia di milioni all'anno, compreso un consistente sovrapprezzo al chilometro per i tratti extraurbani. Attenzione l’affitto della linea dedicata non ha niente a che vedere con l’abbonamento Internet, che andrà stipulato separatamente con il provider che sceglierete. Certamente, tutti i soggetti che offrono linee digitali per trasporto dati vi segnaleranno volentieri società dello stesso gruppo in grado di fornire la connessione Internet; ma siete liberissimi di rivolgervi ad altri.
Un discorso diverso è quello delle economiche linee dedicate analogiche (ovvero per fonia), che grazie ai moderni modem stanno conoscendo una seconda giovinezza. Queste linee possono essere efficacemente usate per la connessione permanente ad Internet a velocità di 56 kbps ed oltre. Le linee analogiche, che costano assai meno delle loro controparti digitali e vengono in genere consegnate in tempo inferiore, sono però ancora in regime di monopolio fino al 1998, e per quest’anno possono essere affittate dalla sola Telecom
Digitale o analogica che sia, una linea dedicata permette comunque alle vostre macchine di essere visibili in permanenza sulla Rete, una condizione necessaria per tenersi in casa il proprio sito Web. Le connessioni digitali temporanee con tariffa a traffico, come ISDN, possono essere altrettanto veloci di quelle dedicate ma sono inadatte a questo scopo, a meno di non lasciarle permanentemente attive.
Una linea dedicata è sinonimo di connessione veloce; ma il motiovo principale per cui la si affitta è in genere quello di gestire un proprio dominio aziendale. Attenzione a scanso di equivoci, val la pena di sottolineare ancora che il collegamento permanente non è necessario per chi desidera soltanto avere un sito il cui nome coincida con la ragione sociale della propria azienda (ad esempio www.fiat.com). Questo infatti si può ottenere senza tenersi il server in casa, ricorrendo al multihoming .. Gestire un dominio significa invece avere un certo numero di indirizzi IP da attribuire stabilmente alle macchine collegate alla rete locale della propria organizzazione. Collegando la propria rete locale alla linea dedicata (e di lì al provider) tramite un router farete sì che le stazioni di lavoro e i server di rete aziendali siano potenzialmente visibili su Internet in permanenza e a tutti gli effetti. La configurazione del router (un compito che di solito spetta al provider) vi permetterà di stabilire in che misura questa presenza potenziale debba essere resa effettiva. Molte aziende limitano l’accesso dall’esterno verso l’interno della rete d’impresa ad alcune macchine e quello dall’interno verso l’esterno ad alcuni servizi Internet considerati di interesse aziendale, come la posta elettronica.
Diventare provider
Oltre alle aziende dotate di una rete d’impresa e agli Enti che, come le Università, sono interessati a Internet per motivi didattici o e di ricerca, c’è una terza categoria di utenti che devono obbligatoriamente ricorrere alla connessione permanente gli aspiranti provider, cioè coloro che intendono attivare un dominio per cedere temporaneamente degli indirizzi di rete alla propria clientela. Ovviamente, per i clienti che si collegano via modem, l’assegnazione di un indirizzo dura quanto una telefonata e riguarda un indirizzo diverso a ogni connessione. Se non si dispone di competenza (e risorse economiche) notevoli non è il caso di fare da soli per vendere connessioni alla Rete ci si può affidare alla formula del franchising, aprendo un Point of Presence (POP) di un provider nazionale, oppure aderire a un consorzio. Le formule di adesione sono le più svariate; molto spesso, comunque, è prevista la fornitura "chiavi in mano" all’aspirante provider del router e degli altri dispositivi necessari in cambio di un investimento iniziale e di una percentuale fissa sui ricavi. La società di frachising o il consorzio si incaricheranno di darvi assistenza sugli adempimenti di legge necessari ad iniziare l’attività In tutti i casi, l’aspirante provider dovrà affittare una linea dedicata , stipulando un contratto con Telecom o con altri fornitori.
Il D.L.103/95 del Marzo 1995 prevede tutta una serie di obblighi e di adempimenti per gli aspiranti provider. Secondo il decreto, i fornitori di servizi di telecomunicazioni (compresi BBS commerciali e Internet provider) si dividono in due categorie quelli che offrono alla clientela solo collegamenti in linea commutata (ovvero tramite connessioni telefoniche temporanee dalla sede del cliente a quella del provider) e quelli che offrono anche collegamenti permanenti tramite linee dedicate. Per i primi è previsto solo l’obbligo di notificare al Ministero delle Poste la loro attività usando i moduli pubblicati sulla Gazzetta Ufficiale n° 240 del 13/10/95. La notificazione è gratuita. La seconda categoria di operatori è invece tenuta a richiedere un’autorizzazione al Ministero, usando sempre i moduli pubblicati sulla Gazzetta Ufficiale n° 240. Le domande di autorizzazione devono essere corredate dal certificato di iscrizione alla Camera di Commercio e dal certificato Antimafia. Le autorizzazioni non sono cedibili e durano 9 anni; il rinnovo è previsto nei 120 giorni precedenti la scadenza. La richiesta di autorizzazione ministeriale comporta il pagamento di un contributo di un milione; c’è poi una tassa annuale, sempre di un milione, per ogni sede in cui siano installate "le apparecchiature di commutazione" ovvero i router. I nuovi operatori obbligati alla sola notificazione devono attendere 60 giorni dalla data della notificazione stessa per iniziare il servizio; chi invece è soggetto all’autorizzazione deve attendere che il Ministero gliela conceda. Il D.L. 103/95 stabilisce che il Ministero deve rispondere entro 90 giorni, eventualmente comunicando una dilazione (che deve essere motivata) non superiore a ulteriori 30 giorni. Il decreto prevede esplicitamente che l’autorizzazione debba essere sempre concessa tranne che per motivi di ordine pubblico, che il Ministero è obbligato a esplicitare al richiedente in modo dettagliato.
Tutorial 5
Il World Wide Web (WWW)
Passiamo ora a qualcosa di molto diverso dagli altri strumenti di Internet, come la posta elettronica, il Gopher, FTP e così via. Parleremo infatti del World Wide Web, una struttura ipertestuale fatta di milioni di pagine collegate tra loro, ricche di informazioni multimediali su qualsiasi argomento possa saltarvi in mente. Il Web è nato per organizzare l'enorme quantità di documentazione cartacea prodotta ogni anno da migliaia di ricercatori sparsi nel mondo, ed anche per permettere a questi ultimi di reperire le informazioni in modo semplice e veloce; oggi è usato da aziende Enti e semplici appassionati per gli scopi di comunicazione più vari. Ogni Web server (ricordate: un server è solo un computer di Internet su cui gira un apposito programma) pubblica alcune pagine. Per leggerle, se si è connessi a Internet, basta collegarsi al server con Netscape o Explorer (digitando il suo indirizzo di risorsa). Probabilmente molti tra i lettori di questo libro hanno già avuto occasione di vedere almeno una di queste pagine Web, ricca di grafica e magari di suono o animazioni. Ebbene, forse resteranno sorpresi nell'apprendere che quello che viaggia sulla Rete è un semplice file di testo. Naturalmente non si tratta di un testo qualunque, ma di un testo marcato, scritto in un particolare linguaggio detto linguaggio per la marcatura di ipertesti o HyperText Markup Language (HTML).
L'idea che sta alla base di questo linguaggio è semplice: invece di inviare un testo già formattato (cioè con titoli, grassetti, corsivi e così via) con il rischio che venga visualizzato diversamente su computer diversi, si mandano frammisti al testo dei marcatori o tag che dicono come va visualizzata ciascuna parte del documento (cioè se è un titolo, se va in grassetto, in corsivo e simili). Così ogni computer che riceve il file marcato eseguirà la visualizzazione a modo suo, cioè nel modo più adatto alle sue caratteristiche.
Un primo sguardo a HTML
Diamo una prima occhiata all'aspetto "vero" di una pagina Web, cioè al suo codice HTML.. Per far ciò, aprite il seguente URL
|
|

In breve, sarete davanti alla Casa Bianca di Washington, D.C. che contiene vari pulsanti, facendo clic sui quali finirete in altre pagine
La pagina della Casa Bianca è discreta, ma che aspetto ha il file HTML effettivamente ricevuto dal nostro computer ? Per saperlo, trovate il comando View source o Document Source tra le opzioni del vostro browser.
Se siete riusciti a vedere il file HTML, vi accorgerete che è un po' deludente rispetto alla pagina grafica.Ma ha un vantaggio su di essa: si può modificare. Come abbiamo detto, i tag che precedono le varie frasi hanno il compito di dire al browser del computer destinatario come visualizzare le frasi stesse.Ogni marcatore ha sempre un collega, posto alla fine della frase a cui va applicato. Impareremo più avanti il loro significato, ma alcuni marcatori sono abbastanza autodescrittivi:
<TITLE>Titolo (inizio) </TITLE> Titolo (fine)
<A> </A> Collegamento Ipertestuale (inizio e fine)
<P> Paragrafo (inizio)
<HR>Linea orizzontale
Come sarà fatto il marcatore di fone paragrafo? Intanto che riflettete eccovi, in forma di diagramma, le relazioni tra chi crea una pagina Web e chi la consulta:
I server HTTP
HTTP significa HyperText Transfer Protocol ed è, come preannunciato nei Tutorial precedenti, il protocollo di alto livello, basato su TCP, che viene usato per trasferire le pagine Web tra il server e il vostro browser. Un HTTP server è un programma sempre in esecuzione su una macchina collegata a Internet. Quando si digita un URL in Netscape o Explorer, il browser manda l'URL al server, che esamina la richiesta e risponde. Di solito, la risposta è l'invio di un file HTML.
Il browser, che sia Netscape o Internet Explorer, usa i marcatori HTML contenuti nel file per capire come va visualizzato il testo della pagina. Questo lavoro di interpretazione dei marcatori può essere fatto per un file ricevuto via Rete così come per un file creato localmente e ricevuto, ad esempio, su dischetto.
Esercizio (3 punti):
Usando Netscape o Internet Explorer esaminare un sorgente HTML e salvarlo come file di testo.
Fate una prova con la pagina della Fiat. Ecco l'URL:
Dopo aver selezionato l'opzione di Netscape o Explorer che serve per vedere il codice sorgente HTML, copiate il testo HTML nel Blocco Note facendo Taglia e Incolla Si fa così: evidenziate tutto il testo, poi selezionate Cut o Copy dal menù Edit di Netscape o Explorer e infine, dopo aver fatto clic sulla finestra di Blocco Note, selzionate Incolla dal menu Modifica). Poi salvate il file da Blocco Note con il nome FIAT.HTM.
Ora, ricaricate fiat.htm nel vostro Web browser. Con Netscape, per caricare il file locale fiat.htm, passate al menu File e scegliete Open File Cercate di ritrovare la cartella dove avete messo fiat.htm e poi fate doppio clic sul suo nome.La pagina comparirà, esattamente uguale a prima. Ma c’è un’importante differenza: quello che abbiamo visto questa volta NON è un file arrivato dalla Rete, ma un file locale, e quindi potremo modificarlo. Fate anzitutto una copia di sicurezza del file, chiamandola fiat2.htm o come volete. Poi tornate in Blocco Note, aprite fiat2.htm, togliete qualche marcatore a caso e salvate il file. Infine, passate a Netscape e riapritelo. Cos'è successo? Modificando i marcatori, l’aspetto della pagina cambia: sono loro a dire al browser come esesguire la visualizzazione.
Anche se non è ancora il momento di lavorare a fondo su HTML, possiamo provare un esercizio che migliorerà la nostra competenza in materia e si rivelerà anche utile. Per farlo, bisogna però aver capito cos'è il marcatore HTML che corrisponde a un collegamento ipertestuale.
I collegamenti sono ciò che unisce veramente le pagine, i documenti e i file che compongono il Web. Senza collegamenti non si potrebbe navigare, saltare o vagare sul Web. Ogni pagina sarebbe un punto d'arrivo, si dovrebbe digitare l'indirizzo specifico di ogni pagina Web che si è visitata e il mouse sarebbe inutile.
Fortunatamente la maggior parte delle pagine Web ha dei collegamenti ipertestuali. Questi possono far riferimento a diverse aree sulla stessa pagina, a pagine sullo stesso sito Web, a pagine precedenti, a file o grafici, a spezzoni audio o video, a indirizzi di posta elettronica e ad altri oggetti su Internet. Ogni collegamento è costituito da due parti: un'origine del collegamento e un punto d’arrivo, entrambi chiamati comunemente ancoraggi. L'origine del collegamento è la parte su cui l'utente fa clic, il grafico o il testo sottolineato. Il punto d’arrivo, che raramente si vede, è l'indirizzo della pagina a cui il collegamento fa riferimento.Ora si imparerà come aggiungere dei collegamenti che fanno riferimento agli elementi sul Web.
Si tratta di scrivere un URL nel testo di una pagina HTML in modo che chi visualizza quella pagina con un browser riscontri i seguenti effetti:
1 - Una frase scelta da noi compare sottolineata e in colore diverso dal resto del testo
2 - Se si fa clic sulla frase, si passa alla pagina corrispondente alla URL, che si trovi sullo stesso o su un altro server HTTP.
Ecco ecco come va scritta una URL nel file HTML perchè ci sia un collegamento funzionante:
<A HREF="http://weblab.crema.unimi.it/internetcourse.html"> Clicca qui per saltare</A>
Il testo posto prima del marcatore di
fine</A> è una frase scelta da noi (può essere qualunque) che sarà
visualizzata sottolineata dal browser. Facendo clic su di essa, si atterra sul
nostroWeb server Ricapitolando: per creare un collegamento ipertestuale bisogna
scrivere <A HREF=" inserire l'URL di atterraggio e chiudere con ">".
Poi si mette la frase che si vuole l'utente veda e infine il marcatore di chiusura</A>.
Ora passiamo a scrivere un po' di questi collegamenti ipertestuali in un file
fatto col Blocco Note, che poi salveremo con il nome parade.htm.
Questa sarà una pagina di collegamenti ai nostri luoghi preferiti sul Web.
Come finezza, possiamo fa precedere il nostro elenco di collegamenti da un marcatore <UL> che sta per "unordered list". Questo farà sì che il browser visualizzi la lista in modo più elegante. Basta mettere il marcatore <UL> prima dell'inizio della lista di collegamenti, inserire il marcatore <LI> prima di ciascun collegamento e infine ricordarsi </UL> alla fine dell'elenco.
Esercizio (7 punti)
Fatevi la vostra classifica di siti preferiti e apritela con il browser, poi inviatecela.
Ecco un esempio, un po' più difficile dell'esercizio proposto
<H2>Link che ho trovato in questi giorni<H2>
<UL>
<LI><A HREF=#Dic_28>28 Dicembre, 1997</A>
<LI><A HREF=#Dic_29>29 Dicembre, 1997</A>
</UL>
<UL>
<LI><A NAME=Dic_28>28 Dicembre, 1997</A>
Ecco le pagine di oggi, 28 Dicembre, 1997
<UL>
<LI><A HREF="http://www.crl.com/~gorgon"> Corsi Arlington</A>
<LI> <A HREF="gopher://gopher.tc.umn.edu">Porta al vecchio Gopher</A>
</UL><
<LI> <A NAME=Dic_29>29 Dicembre, 1997</A>
Queste sono le pagine del 29 Dicembre
<UL>
<LI><A HREF="http://www.visc.vt.edu/succeed/distance.html"> Apprendimento a distanza</A>
<LI><A href="http://www.focushope.edu/"> Progetto Speranza</A>
</UL>
</UL>
<HR>
<A HREF=#Dic_28>Torna al 28 Dicembre</A>
I nuovi marcatori usati nell'esempio sono i seguenti:
<HR> Linea orizzontale (filetto)
#xxx partenza di un salto INTERNO alla pagina
NAME=xxx arrivo di un salto INTERNO alla pagina
<H2></H2> Intestazione
Salvare e stampare le proprie scoperte
Il Web è un mercato delle pulci computerizzato dove si trova di tutto da fatti straordinari, storie fantastiche, poesie, spezzoni audio e video alla fotografia dell'attore o dell'attrice preferita. In genere si visualizza uno di questi elementi usando Navigator oppure Explorer, si dà una rapida occhiata e poi si passa velocemente a un altro sito.
Può capitare, però, di trovare qualcosa che si desidera tenere; in questo paragrafo si impareranno i vari metodi per mettere al sicuro i tesori che si trovano sul Web.
Come salvare ed eseguire gli spezzoni video e le immagini
Il metodo migliore per navigare sul Web è scaricare ciò che interessa, disconnettersi e poi esaminarlo in un secondo momento. Se il proprio provider ha una tariffa oraria non si vorrà certamente sprecare del tempo prezioso a guardare degli spezzoni video mentre si è ancora collegati. Esistono due modi per scaricare, cioè copiare su disco rigido, i file trovati sul Web. Si può fare clic con il pulsante destro del mouse sul collegamento all'elemento che interessa, che può essere un file di testo, della grafica, delle pagine Web o qualsiasi altra cosa e poi fare clic sull'opzione Save Link As o Save Image As.
L'apertura di un file locale
Il browser è prefettamente in grado di aprire i file posti sul computer locale purché siano documenti di testo e HTML. Questo rende possibile visualizzare i file che si sono scaricati precedentemente. Per aprire un file che è sul disco rigido locale si apra il menu File e si selezioni Open Page oppure Open File. Se si sceglie un documento di testo o HTML, Navigator lo apre come se fosse memorizzato su un server Web. Se il documento HTML contiene dei collegamenti, si può fare clic su quei collegamenti per aprirli, ammesso che si sia connessi a Internet con il proprio software TCP/IP.
La stampa su carta
Il World Wide Web è l'esempio lampante di editoria elettronica senza carta. capita, però, trovare un documento che si vuole stampare, magari una schermata della guida di un’applicazione o una citazione interessante. Per stampare un documento dal browser non c'è alcun trucco, basta semplicemente visualizzarlo e si faccia clic sul pulsante Print.
Se si stampa un documento Web, si ottiene una pagina base di 21 x 29,7 cm con un'intestazione e un piè di pagina e i margini di 2,5 cm. E' possibile, comunque, cambiare le impostazioni della pagina per riposizionare il testo sulla pagina o selezionare il tipo di informazioni che si desidera stampare nell'intestazione e nel piè di pagina.
Per modificare le impostazioni della pagina si apra il menu File e si selezioni Page Setup; si immettano semplicemente le impostazioni desiderate e poi si faccia clic su OK.
Si', viaggiare
A questo punto, dovrebbe essere ben chiaro che un collegamento ipertestuale è una frase sottolineata o messa in evidenza, oppure una zona della pagina che, quando viene selezionata, attiva il browser in modo da portarci immediatamente a un'altra parte dello stesso documento oppure a un documento o una risorsa di Rete completamente diversi. I lettori hanno la possibilità di decidere quali collegamenti seguire e quando. Poiché gli utenti del WWW godono della grande libertà di poter consentire alla propria immaginazione di vagare senza limiti non è affatto sorprendente che a volte si sentano persi. I collegamenti ipertestuali possono rendere seriamente difficile il reperimento delle informazioni se non viene dato spazio sufficiente alla loro definizione. Talvolta viene fornita una semplice descrizione del collegamento ipertestuale, ad esempio "Altre risorse di orticultura". Nei casi peggiori, il collegamento farà riferimento a una pagina in modo enigmatico, come "Texas A&M Gopher." In questo secondo caso, purtroppo, l'effetto ottenuto è nascondere informazioni di notevole importanza all'utente.
Fatevi una mappa
Dal punto di vista dell'autore della
pagina Web è difficile abituarsi allo sforzo mentale extra richiesto per
pensare agli agganci ad altri documenti mentre si sta realizzando il proprio.
Preparare una buona struttura di collegamenti per una pagina Web richiede una
notevole cura e una progettazione accurata. L'impegno extra di preparare i
collegamenti ipertestuali può rallentare significativamente il processo di
scrittura.
Anche il lettore è coinvolto in un lavoro mentale extra nel consultare le
pagine Web. Infatti, deve decidere tra molte possibilità: quali collegamenti
seguire e quali ignorare. Il problema di scegliere i collegamenti da seguire
viene a volte chiamato "miopia delle informazioni". Per ridurre la
"miopia" occorre che l'autore della pagina Web etichetti attentamente
i collegamenti con frasi esplicative, icone e così via, che indicheranno al lettore
quello che si deve aspettare quando seleziona un particolare percorso.
Il flusso di pensiero in una pagina Web dovrebbe apparire naturale e
intuitivamente ovvio al lettore. D'altro canto, questo richiede uno sforzo e
un'abilità considerevoli da parte dell'autore. Per l'utente delle pagine Web è
importante sapere se esiste qualcosa per poter ridurre il sovraccarico
conoscitivo e ridurre lo stress. Si supponga di essersi trasferiti in una
strana città dove non si conosce nessuno. Vi sono centinaia di strade e il
compito di impararle velocemente è umanamente impossibile. La reazione più
normale è quella di chiudersi in casa. Poi si passerà a caute esplorazioni per
tentativi e ci si concentrerà sul trovare gli elementi più necessari: una
drogheria, una farmacia, una banca, la scuola nei dintorni e così via. Poiché
questi luoghi hanno la tendenza a trovarsi sulla via principale, durante il
processo di ricerca si diventerà esperti di quella strada. A questo punto si
sarà sviluppata una "cartina mentale" dei propri dintorni che può
differire completamente da una cartina totale della città. Tuttavia funziona
per se stessi, perché include i luoghi che si visitano spesso.
La navigazione Web è un modo per costruire una mappa mentale delle pagine Web
che hanno il massimo valore personale. Per un biologo potrebbe essere
l'itinerario a un importante archivio di fotografie biologiche. Un procuratore
legale potrebbe essere interessato ai collegamenti a una pagina Web che parla
dei diritti d'autore. Anche se sarebbe bello avere una "mappa"
generale del WWW, non è necessaria, e anzi potrebbe non essere tanto utile
quanto avere una mappa mentale personale propria.
Un'operazione che si può eseguire più o meno immediatamente allo scopo di
"assumere il comando" delle propria navigazione Web è reimpostare la
pagina di apertura che appare quando si apre il browser Web. La maggior parte
dei browser forniscono una pagina di apertura preselezionata dal fornitore. Ad
esempio Netscape si connette alla home page della Netscape Communications
Corporation e Microsoft Explorer automaticamente si collega alla pagina
"Explore the Internet" di Microsoft. Anche se queste pagine
contengono molti elementi utili che certamente le rendono degne di essere
esaminate, ora faremo qualcosa di diverso: useremo come punto di partenza la
classifica creata in questo capitolo. Se si sta usando Netscape 2.0 o una
versione più recente, si visualizzi il menu Options dalla barra dei menu
e si selezioni l'opzione General
Preferences . Comparirà un
sottomenu o una scheda dove in una delle selezioni vi sarà Aspetto.
In Netscape Communicator (la versione più recente di Netscape) non esiste più nessun menu Options, che è sostituito da un'opzione Preferences. Quando viene selezionato Aspetto sullo schermo apparirà una finestra di dialogo : nel pannello Startup selezionare il bottone Home Page Location
In un riquadro sottostante sarà
presente un URL, probabilmente
http://weblab.crema.unimi.it/tppmsgs/msgs0.htm#19
la home page di Netscape
Communications Corporation. Si posizioni il cursore alla fine dell'URL nel
riquadro e si utilizzi il backspace o il tasto Canc per cancellare i contenuti.
Al suo posto si metta l'URL della classifica. Si noti che questa procedura è
diversa dall'esercizio precedente in cui si è usata l'opzione Open dal
menu File principale di Netscape per aprire il file fiat2.htm.
Per specificare la posizione della home page si deve infatti specificare l'URL
completo. In Netscape, per indicare che un file HTML è locale, invece di usare
i prefissi http, gopher, o ftp di cui si era già parlato, bisogna usare il
prefisso file:///
Questo può confondere leggermente perché nella maggior parte dei casi negli URL si usano solo due barre rovesciate in avanti (/) dopo i due punti. Per specificare però il percorso completo di un file locale si devono usare tre barre rovesciate in avanti. Se il file si trova in una sottodirectory si deve specificare il percorso completo. Ad esempio si supponga che classifica.htm risieda in una sottodirectory chiamata best sulla propria unità a disco C:. L'URL corretto è: file:///C:\best\parade.htm
Si osservi che non ha importanza la direzione delle barre rovesciate dopo gli ultimi due punti. Su un Macintosh, supponendo che l'unità a disco fisso sia denominata HD200, l'URL dovrebbe essere: file:///HD200/pippo/parade.htm
Se si sta usando Microsoft Internet Explorer 3.0 o successivi, il processo è un po' più complicato. Si porti in primo piano il menu File di Explorer e si selezioni Open. Sullo schermo apparirà una finestra di dialogo con un pulsante Browse.... Si faccia clic su di esso e comparirà una finestra in cui cercare il file parade.htm. Si trovi l'icona del file e si faccia clic su di essa. In seguito una volta che la pagina è aperta in Explorer si apra il menu View e si selezioni l'opzione Options. Infine si faccia clic sulla scheda Navigation e si vedrà una finestra di dialogo. Si faccia semplicemente clic sul pulsante Use Current per rendere parade.htm la propria pagina di apertura.
Si ricordi che la pagina di apertura o home page è solo un punto per ritornare e a cui far riferimento ripetutamente. Non è fatta per mostrarla ad altri ma per il proprio utilizzo personale. Se ci si perde nel cyberspazio, per ritornare agli agi della propria pagina basta fare clic su "Home".
Altri comandi utili
Con Netscape se si seleziona semplicemente il menu Go è possibile mostrare le pagine Web che sono state recentemente visualizzate. A differenza dal comando the Add Bookmark che verrà trattato in seguito, il menu a discesa Go tiene traccia automaticamente di parecchie pagine esaminate di recente senza nessuna richiesta da parte dell'utente. Infine, nessuna discussione riguardo alla navigazione sul WWW è completa senza menzionare il pulsante Stop. Con Netscape si può fare clic sul pulsante Stop sulla barra dei menu per interrompere l'operazione di caricamento di una pagina che va troppo per le lunghe. In modo simile, facendo clic sul pulsante con una "X" rossa sulla barra dei pulsanti di Microsoft Internet Explorer l'operazione di caricamento si fermerà.
Esercizio (ricreativo)
Per i filo-americani, ecco una speciale
pagina Web impostata per onorare l'Old Glory, ovvero la bandiera degli Stati
Uniti. L' URL di questa bandiera è
http://weblab.crema.unimi.it/tppmsgs/msgs0.htm#20
Per chi invece vorrebbe vivere in un
secolo diverso, ecco l'URL per l'Heritage Map Museum, specializzato in antiche
mappe originali dal XV al XIX secolo
http://weblab.crema.unimi.it/tppmsgs/msgs0.htm#21
Esercizio (5 punti):
Si esamini l'HTML di ciascuna delle pagine dell’esercizio precedente e si veda
se si riescono a identificare i marcatori degli elementi grafici (bandiere e
così via) presenti su queste pagine.
Come funziona un Web browser
Come si è visto nella parte iniziale del Tutorial, le pagine Web vengono trasferite sulla Rete nel formato HTML, che non è visibile agli utenti finali, a meno che non lo chiedano espressamente eseguendo un View Source o simili. Il compito principale del browser è
1- collegarsi a un server HTTP
2- ricevere il codice HTML di una pagina
3- ricevere eventuali file ausiliari che contengono immagini o altro
4- presentare all'utente la schermata grafica della pagina
Come ben sappiamo, il comando per collegarsi a un server Web può essere Open (Explorer) o Open Location (Netscape). Una volta collegati al server, riceviamo una pagina, che viene visualizzata sul nostro browser come testo formattato (cioè con corsivi, grassetti e simili ) condito con collegamenti ipertestuali, immagini e a volte suoni o animazioni. Come funziona tutto questo, visto che quello che è arrivato via Rete al nostro browser è un semplice file di testo marcato HTML (più eventuali file ausiliari) ?
Vi abbiamo consigliato di dare un'occhiata al sorgente HTML di varie pagine per provare a identificare i vari elementi , soprattutto i marcatori che includono le immagini. Le immagini sono contenute in file di formati speciali. I due formati grafici più comuni sul Web sono GIF and JPEG, indicati rispettivamente dalle estensioni .gif and .jpg dei nomi dei file.
Ad esempio, se nel file HTML c'è il marcatore
<IMG
SRC="hondius1663.jpg" ALIGN=CENTER ALT="Hondius, 1663">
il browser capisce "visualizza a questo punto della pagina l'immagine hondius1663.jpg, centrata" Ecco il significato degli altri codici di questo marcatore
IMG...........................indica che va inserita un'immagine
ALIGN=CENTER..................posizionamento
SRC=..........................significa "source" ovvero "provenienza"
ALT="Hondius, 1663"...........è una frase che verrà mostrata solo nei vecchissimi browser che non sono in grado di visualizzare immagini.
Oltre alle immagini, il testo HTML di una pagina può contenere vari "collegamenti ipertestuali", ovvero marcatori HTML che delimitano una frase o una parola e le associano una URL. Quando la pagina viene visualizzata, l'effetto è il seguente:
1- la frase viene visualizzata sottolineata e in colore diverso
2- se l'utente fa clic su quella frase, il suo browser si collega alla URL associata
Come abbiamo detto poco fa, la frase associata al collegamento viene chiamata "anchor" o "ancoraggio" nel gergo dei programmatori HTML. Ad esempio se nel file HTML c'è il marcatore <A HREF="http://www.fiat.com"> collegamento alla Fiat </A>
Il browser capisce "se, quando visualizzi la pagina qualcuno fa clic sulla frase "collegamento alla Fiat"", collegati al server www.fiat.com"
Come vedremo, non è detto che gli ancoraggi dei collegamenti ipertestuali siano sempre frasi o parole. Possono essere pulsanti, menu o anche parti di immagini. Si sarà notato che i due marcatori di inclusione di immagine e di collegamento ipertestuale sono molto diversi tra loro. In particolare, mentre il marcatore <A> comprende una URL intera, al marcatore <IMG> basta un nome di file. La ragione è che anche quello che sembra un nome di file in realtà è una URL, ma un URL "relativa", a cui va premesso il prefisso della URL del server su cui si trova. In altre parole: la URL relativa hondius1663.jpg viene estesa automaticamente dal vostro browser in http://www.carto.com/hondius1663.jpg
dove http://www.carto.com è la URL del server a cui siete in quel momento collegati e sul quale si trova il file dell'immagine
Browser: funzionalità aggiuntive
Oltre alle funzionalità di base, tutti i browser consentono di:creare dei "segnalibri" permanenti (bookmark) con gli indirizzi delle pagine interessantie di definire una lista temporanea (history) delle pagine già visitate per tornarvi rapidamente se necessario. Di queste tecniche ci occuperemo nel prossimo tutorial. Inoltre, i più diffusi browser (come Explorer e Netscape) sono in grado di ricorrere a programmi esterni per elaborare dati particolari, come file sonori o spezzoni video. I file multimediali vengono inclusi nella pagina HTML esattamente come le immagini, ma il browser non sa gestirli da solo e deve "chiedere aiuto" a moduli appositi programmi. Questi programmi esterni o helper si trovano in una sottocartella della cartella che contiene il vostro browser. Il browser è in grado di scegliere e attivare quello giusto sulla base dell'estensione del nome di file ausiliario che viene trasferito con la pagina HTML.
Esercizio (5 punti)
Create un file HTML che
contiene soltanto il riferimento a un'immagine HTML. Se usate il file hondius1663.jpg che si trova sul server www.carto.com, dovete usare una URL relativa o quella
completa?
In realtà, un documento contenente solo il riferimento a un'immagine non è HTML corretto, anche se i browser mostreranno di non accorgersi dell'errore. Ogni pagina HTML è infatti tenuta a seguire un certo formato complessivo, con un'intestazione fissa. Ecco la struttura da seguire:
<HTML>
<HEAD>
<TITLE> Qui va il titolo</TITLE>
</HEAD>
<BODY>
Qui va il vostro codice HTML, quando sarete in grado di scriverlo.
</BODY>
</HTML>
Riprovate l'esercizio precedente eguendo questo formato e d'ora in avanti USATELO SEMPRE. Ricordate inoltre che i browser non fanno dostinzioni tra maiuscole e minuscole nei marcatori, anche se noi useremo sempre le maiuscole per leggibilità.
Scaricare pagine complete
Siamo ora pronti a scaricare e salvare una pagina completa. Si tratta di un completamento di quanto visto in precedenza, quando abbiamo salvato una pagina HTML sul nostro disco e l'abbiamo poi aperta con il browser. Ora però vogliamo scaricare la pagina completa, compresi i file ausiliari delle immagini. Per fare questo, occorre salvare uno per uno i file delle immagini e salvarli nella stessa cartella in cui si salva la pagina HTML.
Esercizio (5 punti)
Cominciamo a salvare una pagina
HTML in una cartella creata allo scopo, seguendo il metodo della lezione
precedente Poi guardando il codice HTML si costruisca l'URL completa per
ciascuna immagine contenuta nella pagina, si acceda ad esse e si usi l'opzione Save As del
Web browser per salvarle una per una nella stessa directory in cui avete messo
la pagina iniziale. Caricate la pagina completa nel vostro browser
Ma qual è l'utilità di portare sul
nostro disco pagine HTML di siti remoti ? semplice: alcuni siti di rassegna
contengono pagine di collegamenti ad altri siti che si occupano di un certo
argomento. Se siete appassionati di un argomento, le pagine di elenchi di
collegamenti sono comode da avere localmente invece di dovervi accedere ogni
volta. Aprendo il sito
http://weblab.crema.unimi.it/tppmsgs/msgs0.htm#22
vi troverete nel punto di partenza preferito di molti appassionati di grafica
3D. Perchè non tenere una copia di questa pagina sul proprio computer?
Esercizio (preparatorio al prossimo Tutorial: 0 punti):
Accedete alla seguente URL:
http://www2.infoseek.com/
Si tratta di un sito commerciale che consente di "cercare" su tutto il Web le pagine che contengono una certa frase. In altri termini: voi digitate una frase e lui restituisce l'elenco delle URL delle pagine che la contengono. Provate varie volte a digitare nello spazio apposito delle frasi (o dei nomi di persona: magari siete citati in qualche sito e non lo sapete) . Notate qualcosa di strano nella URL del risultato della ricerca? Cosa?
Tutorial 6
Approfondiamo ancora un po' il discorso sui browser
Le applicazioni helper
Le applicazioni helper sono programmi che eseguono operazioni speciali che il browser è incapace di gestire da solo. Tipicamente, si tratta di programmi che visualizzano o eseguono i file multimediali, tra cui immagini, audio e spezzoni video. Per quanto riguarda le immagini, come si è visto, il browser è in grado di fare anche da solo: sia Netscape sia Explorer sono in grado di visualizzare dei file grafici nel formato GIF o JPG, anche se non saranno perfetti come i grafici in un programma di grafica dedicato, ad esempio LView Pro oppure Paint Shop Pro. L’intervento degli helper è invece indispensabile per altri tipi di file, ad esempio le immagini PCX e gli spezzoni video VDO. Per questi, bisognerà scaricare e installare un'applicazione helper oppure ricorrere a un plug in, di cui parleremo di seguito. Ogni volta che si fa clic su un collegamento a un file che il browser non sa eseguire, esso scarica il file sul disco locale e poi lascia il campo all'applicazione helper associata al file. L'applicazione helper apre il file e lo esegue.
Ovviamente questo avviene solo se tutti gli elementi sono configurati correttamente. Pertanto, ci si devono procurare e installare le applicazioni helper e poi comunicare al browser quale va usata per ogni tipo di file multimediale che si vuole eseguire.
Ad esempio se si fa clic su un collegamento a un filmato, il browser deve sapere se attivare l'esecutore audio, il visualizzatore grafico oppure l'esecutore video. E' necessario associare ogni tipo di file a un'applicazione helper che sia in grado di caricare ed eseguire quel genere di file.
Associare i tipi di programmi alle applicazioni helper è facile. Se si fa clic su un collegamento a un file che non è associato a un'applicazione helper, il browser visualizza una finestra di dialogo Unknown File Type, che in pratica chiede cosa deve fare. Si può fare clic su Save File e preoccuparsi del file in un secondo momento oppure eseguire le operazioni necessarie, lievemente diverse in Explorer e in Navigator, per associare il tipo di file a un'applicazione helper. Sebbene l'elenco dei tipi di file comprenda la maggior parte di quelli che si trovano comunemente sul Web, se ne può incontrare uno che non è nella lista e che richiede un'applicazione helper speciale. In questo caso si può creare un’associazione basata sull’esetensione del nome del file. Sullo schermo compare una finestra di dialogo che richiede un tipo MIME, una descrizione del tipo di file e l’estensione che avranno i nomi dei file di quel tipo. Poi si seleziona l'applicazione helper desiderata.
A questo punto, eseguire un collegamento multimediale è facile quanto fare clic su di esso. il browser trasferisce il file e poi attiva l'applicazione helper che lo carica e lo esegue, quindi non resta che stare a guardare.
Va ricordato che i file multimediali possono richiedere molto tempo per essere trasferiti, anche se si ha un collegamento veloce. La quantità di tempo che impiegano dipende dalla velocità della connessione, dalla dimensione dei file, dalla quantità di traffico sul server, dalla distanza del server dal vostro computer e dalla velocità del calcolatore che usate.
Ricordate anche che le schede audio a 8 bit e i monitor standard VGA non sono più adatte agli spezzoni audio e video memorizzati sul Web. Se state usando ancora la vecchia tecnologia, probabilmente navigare il Web vi darà l'incentivo per migliorare.
Se avete un monitor Super VGA e di una scheda audio a 16 bit o più, assicuratevi che siano configurati per la massima qualità. Se il monitor Super VGA è impostato a soli 16 colori, le immagini e gli spezzoni video daranno il temuto "effetto neve". Per godere appieno della multimedialità via Web, ci si assicuri di configurare il video per visualizzare almeno 256 colori; inoltre si controlli che la scheda audio sia in modalità stereo a 16 bit
I plug in e i controlli ActiveX
Fino a pochi anni fa i browser Web facevano assegnamento sulle applicazioni helper per eseguire i tipi di file che non sapevano gestire.
Abbastanza recentemente Netscape e Microsoft hanno trovato delle alternative alle applicazioni helper; in particolare Netscape è stata la prima a introdurre l'idea dei plug in. I plug in sono mouli aggiuntivi che aumentano le capacità del browser Web. A differenza delle applicazioni helper, che sono applicazioni separate, i plug in diventano una parte del browser Web, che lo rende più efficiente nell'eseguire file multimediali.
Cosciente dei vantaggi di questa impostazione, anche Microsoft ha creato la propria versione dei plug in, i controlli ActiveX. Come i plug in, i controlli ActiveX diventano parte del browser Web e gli consentono di gestire i tipi di file che diversamente non il browser saprebbe come trattare. ActiveX è un'ottima tecnologia di condivisione dei programmi e dei file che è stata progettata per lavorare principalmente con il browser Web della Microsoft, cioè Internet Explorer. Comunque, anche Navigator 4.0 supporta la tecnologia ActiveX tramite l'utilizzo di un plug in speciale, e consente di scaricare e usare i controlli ActiveX.
A volte, lo stesso tipo di file multimediale può essere gestito sia con un plug in, sia tramite un applicazione helper. Le applicazioni helper vanno preferite quando si desidera scaricare un file multimediale ed eseguirlo in un secondo momento. Usandole, per eseguire il file non è necessario far funzionare il proprio browser Web.
Come ottenere i plug in
A volte, il metodo più facile per procurarsi il plug in che serve è cercare di eseguire un tipo di file che il vostro browser non sa gestire. Le versioni più recenti dei browser Netscape, ad esempio, sono impostate in modo da avvisare quando hanno bisogno di un particolare plug in. Se fate clic su un collegamento che il browser non è in grado di eseguire e il vostro browser "sa" che esiste un plug in disponibile per quel tipo di file, viene visualizzata una finestra di dialogo che richiede che si scarichi il plug in appropriato.
Ad esempio ci si può spostare allindirizzo http://www.vdo.net
e fare clic sul collegamento VDO Guide. Così facendo compare un elenco di siti che contengono spezzoni video in formato VDO. Basta poi seguire le sequenze dei collegamenti a una delle pagine in VDO Guide; non appena si arriva a destinazione, se avete una versione recente, il browser visualizza un messaggio per comunicare che serve un altro plug in.
Nella maggior parte dei casi, dopo aver scaricato il file, si può fare semplicemente doppio clic su di esso per iniziare il processo d'installazione. Se la procedura è più complicata, il sito da cui si è scaricato il file dovrebbe avere le istruzioni specifiche. Se si incontrano dei problemi nell'installazione del plug in, si ritorni nella sua home page per ulteriori indicazioni.
La Stroud's List
E' possibile trovare i collegamenti alla maggior parte dei plug in che servono e anche le informazioni e le valutazioni su di essi visualizzando la cosiddetta Stroud's List, un documento Web molto utile, creato da Forrest H. Stroud.(http://www.stroud.com)
Se non si riesce a visualizzare questa pagina, ci si sposti in Yahoo al sito
e si cerchi Stroud's. Sullo schermo compare un elenco di collegamenti a vari server che riproducono la Stroud's List. Si selezioni il server più vicino.
Quando si arriva a destinazione, si faccia clic sul grande grafico di Stroud nella parte superiore della pagina. Si faccia poi scorrere la pagina fin che si vede il Main Menu.
Dal Main Menu si faccia clic sul collegamento Plug-in Modules e ci si sposterà in una pagina che elenca i moduli plug -in più comuni.
Sebbene la pagina Plug-in offra i collegamenti a molti dei più famosi plug in, la lista non è completa. Ad esempio, l'elenco non comprende FigLeaf, un visualizzatore grafico che esiste sia come applicazione helper sia come plug in. Se non si riesce a trovare il plug in che serve, si ritorni al Main Menu di Stroud e si faccia clic su un collegamento a una categoria di applicazioni. Ad esempio si potrebbe fare clic su Audio Apps per un riproduttore audio, su Graphics Viewers per un riproduttore di immagini o su Multimedia Viewers per un riproduttore video. La lista di Stroud classifica i plug in, indica se il plug in è stato controllato e mostra la dimensione del file che si sta scaricando. Ci si assicuri di verificare queste informazioni prima di eseguire il trasferimento. Per leggere una breve descrizione del prodotto e confrontarla con gli altri della stessa categoria, si faccia clic sul collegamento Full Review.
Quando si è pronti per scaricare il file, si faccia clic sul collegamento vicino a Location e poi si segua la sequenza di collegamenti. Si controlli di prelevare la versione corretta dell'applicazione helper (per Windows 3.1, Windows 95 o Macintosh).
Sebbene la lista di Stroud non faccia distinzioni tra i vari sistemi operativi, il sito di trasferimento tipicamente visualizza una form che consente di specificare il sistema operativo oppure mostra le varie versioni.
Il lato positivo dei plug in è che non richiedono che si intervenga sulla configurazione dell'applicazione per eseguire i file di un particolare tipo; basta installare il plug in e il browser si occupa del resto.
L'unico inconveniente è che i nuovi plug in eliminano ogni precedente plug in o applicazione helper che era incaricata di gestire lo stesso tipo di file. Se, quindi, si installa il plug in e poi si decide che, invece, si preferisce usare un'applicazione helper, si deve disinstallare il plug in (cosa piuttosto facile) e poi riassociare il tipo di file all'applicazione helper originale (operazione per niente semplice). L'installazione di un plug in è facile. Una volta lo si è scaricato, si finisce per avere sul disco rigido un file ad autoestrazione e di solito ad autoinstallazione. In alcuni casi il file ad autoestrazione potrebbe non essere ad auto installazione. Dopo aver decompresso il file, si può dover entrare nella directory dove sono memorizzati i file estratti e eseguire Setup.exe o Install.exe. I plug in tipicamente vengono forniti con una loro specifica utility di disinstallazione.
ActiveX
ActiveX è una tecnologia che consente agli sviluppatori di pagine Web di mettere su una pagina tutti i tipi di animazioni, programmi o altri oggetti e poi eseguirli. Il sistema ActiveX è costituito da tre componenti:
- Controlli ActiveX, una sorta di plug in che consente al browser di eseguire i componenti ActiveX.
- Documenti accessibili via ActiveX, documenti che si possono aprire e modificare in ogni applicazione che supporta ActiveX. Ad esempio si può aprire un documento Word o un foglio elettronico nel proprio browser Web.
- Script di ActiveX, un linguaggio di programmazione che permette agli sviluppatori Web di scrivere e inserire piccole applicazioni nelle loro pagine Web e coordinarle con gli altri componenti ActiveX. JavaScript e VBScript sono i linguaggi script di ActiveX.
Mentre Explorer ha la capacità nativa di eseguire gli elementi ActiveX, Netscape ha bisogno di un plug in speciale. Per procurarvelo visitate il sito NCompass (http://www.ncompasslabs.com). Il plug in consente a Netscape 4.0 di aprire i documenti Active, creati in Microsoft Word, Excel, PowerPoint e in altre applicazioni che li supportano.
Per procurarsi controlli ActiveX oltre
al solito sito di Stroud(http://www.stroud.com) si può consultare la
ActiveX Gallery della Microsoft presso il sito:
http://www.microsoft.com/activex/gallery .
Sullo schermo compare una pagina con i collegamenti a molte società che hanno prodotto controlli ActiveX.. Una volta entrati nella Gallery, basta fare clic sul controllo ActiveX che si vuole e viene visualizzata una pagina che descrive il controllo e presenta un collegamento per scaricarlo e installarlo.
Il mondo di Intranet
Immaginate di essere attesi a una importante riunione aziendale per la valutazione dei dati di vendita del trimestre. Avete bisogno di un aggiornamento dell’ultimo minuto dalla sede di Roma, ma i dati che vi servono sono in un archivio del loro elaboratore centrale. Dal vostro ufficio non potete accedere agli archivi di quel calcolatore: siete costretti a chiedere i dati per telefono a un vostro collega. Che è regolarmente in ferie. Oppure ha l’interno occupato. Mentre i preziosi minuti scivolano via, sicuramente vi chiedete se in quest’epoca di reti non c’è qualche altro modo per risolvere il problema.
Ebbene, come testimoniano i casi di
grandi aziende come Pirelli, Levi Strauss, Chevron e Goodyear, una soluzione
c’è già, e ha persino un nome: Intranet.
Gli appassionati di Internet avranno già capito dove si va a parare: l’idea è
dotare le varie sedi dell’azienda di server WWW "privati", non
rivolti al pubblico, ma alla distribuzione dell’informazione interna. Internet
non c’entra: per collegare le reti locali delle varie sedi aziendali si può
usare il protocollo PPP su linee dedicate, realizzando connessioni
punto-a-punto del tutto sicure, perchè non collegate a Internet.
Server e client Web funzioneranno senza problemi, ma limitatamente
all’inter-rete aziendale: la vostra Intranet. La tecnologia del Web consente
già oggi di interrogare server che girano su vari tipi di computer usando il
client Netscape, Explorer o altri, nella versione più adatta al proprio
personal preferito. Attraverso il server Web, un prodotto collaudato e
disponibile anche in versione proprietaria, la tecnologia Intranet permette di
accedere ad applicativi e database relazionali creando un unico sistema
informativo globale a livello di impresa. Inoltre, i client Web integrati nelle
suite di produttività personale più diffuse, come Microsoft Office e Lotus
Smartsuite, in modo che l’informazione distribuita via Web sia facilmente
integrabile con quella locale per produrre documenti, presentazioni, report e
così via.
Infine, va ricordato che oltre al Web, la tecnologia Internet offre i servizi di
base, come la posta elettronica e il trasferimento di archivi. Questi servizi
sono un supporto ideale alla gestione dei workflow e sono importantissimi per
le imprese perchè il modello di organizzazione del lavoro oggi prevalente nelle
imprese e nella Pubblica Amministrazione è cooperativo e caratterizzato da
flussi informativi di notevole intensità tra i singoli utenti e i gruppi di
lavoro a cui appartengono.
Morgan-Stanley, la grande banca d’affari americana, è stata all’avanguardia in questo tipo di applicazione. Prima di Intranet, i suoi "trader" (ovvero gli specialisti di transazioni finanziarie) specializzati in obbligazioni immobiliari passavano la giornata davanti al computer a fare il taglia-incolla prendendo i dati dall’aggiornamento sulle quantità di obbligazioni detenute dalla banca e sulle oscillazioni dei tassi d’interesse (100 pagine, in media) e inserendoli nei messaggi da inviare agli oltre 100 intermediari internazionali di cui Morgan-Stanley si serve. Risultato: spesso le informazioni arrivavano in Estremo Oriente dopo l’apertura dei mercati, e gli intermediari perdevano occasioni preziose. Oggi, l‘informazione è estratta dal database della banca e inserita automaticamente in un sito Web interno che gli intermediari di tutto il mondo consultano via Intranet. Oltre 4.000 dipendenti hanno oggi accesso alla rete interna di Morgan-Stanley, che la utilizza anche come economico sostituto delle telefonate intercontinentali grazie alla tecnologia del telefono su Internet. Internet Phone.
Videoconferenza e telefono via Rete
Internet Phone, WebPhone e altri programmi consentono di fare delle vere e proprie chiamate telefoniche tramite Internet o Intranet. Le telefonate via Web sono gratuite, ma se la vostra connessione a Internet è tramite un modem lento è meglio non avere grandi speranze di qualità. Come si è visto nel Tutorial 1, infatti, TCP/IP non è un metodo particolarmente adatto per trasmettere la voce: per consentire le conversazioni telefoniche: il programma deve registrare la voce, digitalizzarla (cioè trasformarla in un flusso i bit), dividere il flusso in pacchetti e poi inviarli via Internet. Lungo il percorso i pacchetti passano per parecchi router prima di arrivare a destinazione e subiscono dei rallentamenti. Con i modem, l'audio è tipicamente di qualità abbastanza bassa e presenta ritardi enormi. Il telefono via rete, però, funziona molto bene con una connessione permanente oppure su Intranet.
Quasi tutti i programmi per la telefonia via Internet, così come i loro omologhi incorporati nelle più recenti versioni dei browser, hanno le seguenti caratteristiche:
Telefonate gratuite se si ha una scheda audio, gli altoparlanti, un microfono e un amico con un computer con strumenti simili, si possono fare delle chiamate su Internet senza pagare la bolletta alla Telecom.
Una lavagna grafica condivisa molti programmi di comunicazione come Whiteboard di Netscape Conference consentono di seguire vere e proprie video conferenze visualizzando un'immagine sui monitor di tutti i partecipanti.
Uno strumento di conversazione via tastiera se il collegamento audio non funziona si possono comunque digitare i messaggi.
La navigazione collettiva sul Web Si può navigare sul Web con un amico, il che lo rende molto più interessante.
Purtroppo, per iniziare non è possibile collegare semplicemente il telefono al modem. Il vostro computer, infatti, deve avere alcuni accessori per fungere da telefono. Sono necessari una scheda audio, degli altoparlanti, un microfono e un apposito programma come Internet Phone, Net Meeting di Microsoft o Netscape Conference. In secondo luogo, non ci si può collegare a un telefono comune. Anche l'altro interlocutore deve essere connesso a Internet, avere un computer con una scheda audio, degli altoparlanti e un microfono e un programma telefonico compatibile Internet.
Perdipiù, quando si inoltra la chiamata
il destinatario deve sapere che lo si sta chiamando e avere il suo computer
impostato per la risposta; altrimenti si dovrà lasciare un messaggio di
segreteria telefonica. Per quanto riguarda la riservatezza delle chiamate,
inoltre, non si può davvero stare molto tranquilli. Internet non è il posto più
sicuro per le conversazioni riservate. I pacchetti rimbalzano su router
pubblici durante il loro percorso verso la destinazione, rendendo così facile
l'intercettazione ai curiosi. Se si tiene alla propria privacy, si esamini
PGPfone (Pretty Good Privacy) all'indirizzo
http://web.mit.edu/network/pgpfone/
Le modalità per eseguire una telefonata variano da programma a programma; comunque, il ruolo del numero telefonico è sempre sostenuto dall’indirizzo di posta elettronica del destinatario. Come alternativa si può digitare il suo indirizzo IP, che è un numero come 192.90.110.78. Molti provider, però, assegnano a ciascun utente un indirizzo IP diverso ogni volta che si collega, rendendo questo numero inaffidabile.Se non riuscite a contattare una persona utilizzando l'indirizzo di posta elettronica, potete provare a individuare l'utente selezionando il suo nome dal DLS (Dynamic Lookup Service, Servizio di ricerca dinamico). Un DLS è un server gestito da Netscape, Four11, o altre società che scelgono di fornire questo servizio. Tiene traccia di tutti gli utenti che vogliono essere elencati. Se la persona che si sta cercando ha scelto di essere inserita nell'elenco si può utilizzare il DLS per trovarlo.
Lavagne condivise e navigazione di gruppo
Una lavagna condivisa o whiteboard è uno strumento che permette di inviare delle immagini all'interlocutore di una chiamata, corredandole di annotazioni testuali e grafiche. Gli strumenti di questo tipo sono diventati molto più diffusi ora che molte aziende danno ai loro dipendenti l'opportunità (non sempre gradita, in verità) di diventare liberi professionisti oppure di lavorare con un computer da casa. Con una lavagna condivisa è possibile collaborare ai progetti e confrontarsi durante delle riunioni aziendali virtuali.
Con la lavagna condivisa si inviano dei file grafici attraverso Internet, proprio come se si stesse inoltrando un messaggio di posta. Se non si ha pronto il file grafico da spedire si può visualizzare una schermata sul proprio computer ad esempio quella di un foglio elettronico, e far sì che la lavagna condivisa catturi ed invii la schermata. Quest'immagine poi compare sul video del collega con cui si è in comunicazione e si può iniziare ad annotarla.
Nel caso di una teleconferenza via Internet o Intranet, ovvero di una chiamata a più partecipanti, l'immagine viene inviata immediatamente a tutti i partecipanti alla conferenza e compare sullo schermo di ciascuno.
Una volta che l'immagine è arrivata, chiunque partecipi alla teleconferenza può iniziare a disegnare sullo schermo usando degli strumenti di disegno simili a quelli di Paintbrush. La superficie di lavoro di una lavagna condivisa è costituita da due strati: uno strato dell'immagine e uno strato del disegno. Se qualcuno del gruppo trascina per sbaglio il mouse su tutta la schermata e danneggia l'immagine visualizzata, si può sempre cancellare lo strato di disegno non voluto e ricominciare.
Mentre si sta parlando si può aver bisogno di far riferimento alle pagine di un sito Web. Molti programmi di teleconferenza, come Microsoft NetMeeting e Conference di Netscape offrono uno strumento che permette a un partecipante alla teleconferenza di guidare gli altri in un viaggio tra le pagine Web, a scopi didattici o dimostrativi. Perché questo funzioni, basta solo che tutti i partecipanti stiano usando lo stesso programma di teleconferenza.
Tutorial 7
Chi cerca trova
Tutti gli esperti sono d'accordo su un fatto: il valore di una connessione Internet non dipende da quanta informazione si trova sulla Rete ma da quanti dati utili noi siamo effettivamente in grado di raggiungere "navigando" nel mare delle informazioni. Il problema è tutto qui: navigare, come ogni lupo di mare vi confermerà, è più un'arte che una scienza. Se siete interessati a imparare, questo tutorial è quello che fa per voi: parleremo delle tecniche e dei trucchi usati dagli esperti per muoversi "a vista" nel Web e scoprire quali sono le risorse più interessanti.
Tornare alle pagine preferite
Se si deve seguire su una sequenza di trentacinque collegamenti nel tentativo di trovare la home page di Bruce Springsteen, rimanendo collegati a Internet per un'ora, può capitare che alla fine non si abbia più tanta voglia di vedere le 120 fotografie del Boss disponibili in Rete. Per evitare tali situazioni, in questo paragrafo verrà spiegato come ritornare alle pagine già visitate selezionandole dalla lista history e come creare dei segnalibri per le pagine preferite.
La history
Quando fate clic su dei collegamenti o digitate degli URL, il browser tiene traccia degli URL delle pagine visitate e li aggiunge a una lista riepilogativa. Quando si utilizzano i pulsanti Back e Forward, in realtà ci si sposta verso l'alto e verso il basso della lista riepilogativa per ritornare ai documenti già visualizzati.
Quando si visitano dieci siti e si vuole rivedere il quinto, il metodo più rapido non è fare clic sul pulsante Back per cinque volte; per tornare indietro si può selezionare l'URL che interessa dalla lista riepilogativa. Il modo più semplice per eseguire ciò in Netscape è aprire l'elenco a discesa Location e fare clic sull'URL della pagina che si desidera.
I segnalibri
Il Web è un grandissimo libro costituito da milioni di pagine, quindi se si trova una pagina che contiene una figura o una citazione interessante la si vorrà ricordare per ritornarvi in seguito. Per semplificare le cose basta creare un segnalibro (bookmark ) per la pagina in questione. Un segnalibro è una voce che si può selezionare dal menu Bookmarks del browser per tornare rapidamente a una pagina visitata.
Il menu Bookmarks di Netscape 4.0, ad esempio, contiene già quasi cento segnalibri pronti che sono ordinati in categorie, tra cui Finance, Business, Computers ed Entertainment e raggruppati poi in sottomenu. Per spostarsi in una pagina con segnalibro, si apra il menu Bookmarks, si ponga il mouse sulla categoria che interessa e poi si faccia clic sul nome della pagina.
E' possibile creare velocemente dei segnalibri per qualsiasi URL di cui si disponga o per qualsiasi pagina visualizzata, anche se non la si è mai visitata prima. In Netscape, per creare un segnalibro per una pagina visualizzata, si eseguano le fasi seguenti:
1 Si apra la pagina che si vuole visualizzare.
2 Ci si assicuri che il documento sia stato trasferito completamente, perchè se è in fase di trasferimento, non lo si può contrassegnare.
3 Si apra il menu Bookmarks e si faccia clic su Add Bookmark oppure si prema Ctrl+D.
Il segnalibro viene aggiunto nella parte inferiore del menu Bookmarks.
Esercizio (2 punti)
Si esegua la stessa operazione usando le opzioni di Microsoft Explorer
Se si trova un collegamento che si vorrebbe visitare in seguito, si può creare un segnalibro senza aprire la sua pagina. Si faccia clic con il pulsante destro del mouse sul collegamento per visualizzare un menu di scelta rapida e poi si faccia clic su Add Bookmark.
Man mano che si aggiungono dei segnalibri, questi vengono raggruppati nella parte inferiore del menu Bookmarks insiema al nome o all’URL complicato che il Webmaster ha deciso di usare. Con il passare del tempo, il menu Bookmarks si riempie di URL e di nomi incomprensibili elencati senza ordine logico.
E’ importante tenere sotto controllo la proliferazione dei segnalibri, o sostituirli di quando in quando con una pagina web di partenza come quella suggerita in questo corso. Netscape 4.0 è in grado di creare una pagina di questo tipo automaticamente a partire dalla lista dei segnalibri dell’utente.
Metti un server nel motore
Ma come fare a trovare le pagine che parlano dell’argomento desiderato senza perdersi nel mare del Web? La tecnica di ricerca più semplice prevede di digitare una parola e trovare le pagine (a qualunque server appartengano) che hanno quella parola nel loro titolo o nella pagina stessa. Questo tipo di ricerca è possibile collegandosi a un server Web di ricerca di tipo "search engine", ovvero un "motore di ricerca" del WWW. Questi motori vengono creati in molti modi diversi.
Alcuni vengono generati partendo dalle hotlist; in altri casi sono gli utenti (i gestori di server WWW) a inserire le loro pagine nell'indice. Altri motori per catturare delle informazioni usano un "programma esploratore" detto Spider o Worm. Comunque siano stati creati, i motori di ricerca contengono un (lunghissimo) elenco di termini e, per ognuno di essi, la lista delle pagine Web in cui compare. Digitando una parola nelle apposite caselle di questi siti e facendo clic su Search.. o Query, si ottiene un elenco di tutte le pagine in cui quella parola compare sui server Web di tutto il mondo.
L'elenco è "cliccabile", nel senso che facendo clic sul nome di una delle pagine trovate si passa direttamente a quella pagina. I più rappresentativi di questi motori sono probabilmente Lycos e Altavista, anche se il loro numero è sempre in aumento.
Esercizio (3 punti)
Visitate i seguenti URL:
http://weblab.crema.unimi.it/tppmsgs/msgs0.htm#45
e leggetevi le modalità di ricerca avanzata per ciascuno di questi motori.
Esercizio (2 punti)
Eseguite due ricerche, una su Lycos e una su Altavista, usando una singola parola di interesse per la vostra professione o hobby
(ad esempio: "embryology"
oppure "router").
Quale "motore" vi ha soddisfatto di più?
Alcuni siti, come WebCrawler, sono in grado di usare più motori di ricerca come subroutine, e di mettere poi insieme i risultati.
Visitate l'URL http://www.webcrawler.com
ed eseguite la ricerca della stessa parola che avete usato per l'esercizio
precendente e paragonate i risultati.
Esercizio(5 punti)
Create una pagina HTML nel file motori.htm con tutti questi di collegamenti, in modo da poterla utilizzare come punto di partenza sul Web.
Attenzione: se volete cercare locuzioni di più parole (ad esempio "Beverly Hills" o "Agrate Conturbia") dovete in genere collegarle con la particella AND. La mancanza di connettivi logici viene interpretata come OR: il motore vi restituisce tutte le pagine che contengono almeno uno dei termini elencati.
Esercizio(10 punti)
Consultate la guida di ciascun motore di ricerca fin qui descritto per imparare a fare ricerche a parole multiple su ognuno di essi. Trovate per ciascun motore la sintassi della ricerca a parole multiple che individua i documenti Web che contengono insieme le parole "Crema" e "Lodi" ma non "Cremona". Aggiungete una tabella che mostra quanti documenti ci sono sul Web con queste caratteristiche secondo ciascuno dei motori visti.
Classificazioni per argomenti
Sulla Rete esistono molti server "di ricerca", il cui scopo è velocizzare l'accesso alle pagine di altri server classificandole per argomenti. Un vero esperto deve conoscere questi punti d'accesso per poter trovare velocemente le informazioni che gli servono. Tutti gli attuali sistemi di classificazione però sono molto incompleti e nessuno riesce ad andare di pari passo con lo sviluppo del Web. I server di ricerca per argomenti sono di due tipi. Al primo appartengono i server gestiti da un singolo o da un piccolo gruppo di persone, che osserva le pagine sul Web, trova quelle utili e le include nel server di ricerca in base a una classificazione per argomenti. Questi elenchi saranno sempre incompleti perchè gli autori non possono far fronte assolutamente alle centinaia, se non migliaia, di nuove pagine che vengono create ogni giorno. L'altra categoria di server di ricerca è costituita da quelli dotati di autoregistrazione. Il gestore mette a disposizione degli utenti (che sono a loro volta gestori di server WWW) una pagina con una scheda di classificazione.
Questa scheda permette loro di inserire nel server di ricerca una registrazione relativa al server che gestiscono. Alcune schede evolute consentono anche la creazione di nuovi argomenti
YAHOO
Yahoo è molto diverso dai siti visti nella prima parte della lezione perchè non è un motore di ricerca, ma un catalogo di siti Web organizzato per argomento. Anche se non tutti i siti Web di Internet sono presenti negli elenchi tematici di Yahoo, il sistema contiene informazioni su più di 40.000 pagine Web.
Provate a dare un'occhiata per conto vostro a http://www.yahoo.com/
La pagina principale riporta quattordici argomenti principali, scegliendo uno dei quali si passa ai suoi sottoargomenti e così via. Se non avete pazienza di seguire la classificazione, potete iniziare la vostra ricerca digitando le parole che cercate. Yahoo ricorrerà ad Altavista per trovare le pagine e poi confronterà il risultato della ricerca con il suo sistema di classificazione. Ad esempio, digitando le due parole: "Università Milano" vedrete i siti che contengono informazioni sulle Università milanesi. Se avete un server Web tutto vostro, potete informarne Yahoo scegliendo l'opzione "Add URL" dal menu principale e compilando la scheda di registrazione.La pagina dei risultati di Yahoo contiene anche alcuni collegamenti ad altri motori di ricerca, come Lycos, WebCrawler, e altri. Rispetto agli altri motori di ricerca basati sulla sola ricerca di parole chiave, Yahoo trova meno corrispondenze, ma spesso di qualità assai migliore.
EXCITE
Anche questo motore, posto all'URL http://weblab.crema.unimi.it/tppmsgs/msgs0.htm#63 si basa su un sistema di classificazione intelligente
Esercizio (2 punti)
Eseguite due ricerche, una su Yahoo e una su Excite, usando la stessa locuzione di sue parole (ad esempio: "network congestion" oppure "genetic algorithms". Osservate le differenze tra i risultati delle due ricerche. Quale "sistema di classificazione" vi ha soddisfatto di più?
La suddivisione per organizzazioni
Oltre alla classificazione per argomenti alcuni siti forniscono una serie di pagine che suddividono il WWW in base ai tipi di organizzazioni a cui appartengono i server. Ad esempio, si possono elencare separatamente i server delle Università, delle aziende e delle organizzazioni non a scopo di lucro.
Le aziende vengono spesso divise a loro volta in sottogerarchie come "Produttori di hardware", "Prodotti aereospaziali" o "Prodotti chimici". Queata classificazione è utile quando si cerca una particolare organizzazione per conoscere i suoi servizi e/o i suoi prodotti. . Ecco alcuni server con classificazioni di questo tipo.
Server con classificazione per organizzazioni
Università Americane http://weblab.crema.unimi.it/tppmsgs/msgs0.htm#64
Siti Commerciali "Top http://weblab.crema.unimi.it/tppmsgs/msgs0.htm#65
I nuovi siti
Gli esperti di WWW si tengono costantemente aggiornati sulle nuove pagine che compaiono sul Web. Il Centro nazionale per le applicazioni dei supercomputer, (NCSA, National Center for Supercomputer Applications), ha fornito per molto tempo una pagina che conteneva gli annunci di nuove pagine. La pagina si chiamava "What's New" e il suo URL è ancora attivo; date un'occhiata facendo clic su
http://www.ncsa.uiuc.edu/SDG/Software/Mosaic/Docs/whats-new.html
I pulsanti "What's new" e "What's cool" di Netscape Navigator mettono in comunicazione con le omonime e famosissime pagine del sito Netscape, che oggi hanno sostituito NCSA come punto di riferimento del Web. fate clic qui per dare un'occhiata:
http://home.it.netscape.com/it/home/whats-new.html
Infine, ecco un breve elenco di motori di ricerca interessanti:
Hotbot (http://weblab.crema.unimi.it/tppmsgs/msgs0.htm#46)
L’indice più completo del Web con
oltre 54 milioni di documenti. Potente motore di ricerca con tecnologia Inktomi
InfoSpace (http://weblab.crema.unimi.it/tppmsgs/msgs0.htm#68)
Stessa tecnologia di Altavista ,
con bonus aggiuntivi come la posta elettronica gratuita.
Infoseek (http://weblab.crema.unimi.it/tppmsgs/msgs0.htm#47)
Uno dei motori di ricerca
"storici" del Web Contiene registrazioni su oltre 10 milioni di siti
Magellan (http://weblab.crema.unimi.it/tppmsgs/msgs0.htm#69)
Questo servizio, contiene
descrizioni e recensioni sui migliori siti Web. Contiene registrazioni su
oltre1.5 milioni di siti, 40.000 dei quali recensiti e valutati (da 1 a 4
stelle).
Ricerca : Non solo Web
Quando si esegue una ricerca bisogna rendersi conto che non tutta l'informazione potenzialmente utile si trova sulle pagine Web. Le notizie che cerchiamo possono essere in archivi FTP, server Gopher, ma soprattutto nelle news., che contengono il materiale più aggiornato, sebbene spesso controverso.
DEJA NEWS
Per cercare nelle news si può usare il motore di ricerca DejaNews, presente all' URL http://www.dejanews.com/
DejaNews offre la scelta tra una ricerca veloce (Quick Search, quella che compare per prima) e una completa (Power Search), con l'opzione posta in basso a destra sulla prima pagina. Attenzione ancora una volta al problema delle parole multiple. Se si digita ad esempio la locuzione "Neural Network", DejaNews mostrerà una lista di articoli delle news che contengono le parole "Neural" oppure "Network." Poichè "Network" è una parola assai comune, la gran parte degli articoli trovati da Dejanews riguarderà le reti. Con l'opzione all DejaNews troverà solo gli articoli che contengono entrambe le parole "Neural" and "Network." E' anche possibile usare un "filtro" per limitarsi a un unica persona, gruppo di discussione o data, scegliendo Power Search e poi Create Filter
Esercizio (3 punti)
Quand'è che l’autore di questo corso (Ernesto Damiani)ha inviato l'ultima volta un articolo alle news? Su quale argomento? (Suggerimento: In Dejanews, scegliete Power Search e poi Create Filter. Nella maschera che compare inserite nome e cognome dell'autore che volete trovare (legati con la particella AND, se no troverete gli articoli il cui nome autore contiene l'uno o l'altro).
Osservate bene le altre condizioni di filtro di Power Search.
VERONICA
Veniamo ora ad occuparci dell'informazione contenuta nelle migliaia di server Gopher presenti su Internet. Per fortuna la situazione è assai migliore che sul Web: Veronica,sviluppata all'Università del Nevada accede a un'indice di TUTTI i gopher server del mondo. Il modo migliore per trovare un server Veronica da interpellare è collegarsi all' URL gopher://gopher.tc.umn.edu/
Dal menu che compare si scelga Other gopher and Information Servers. Comparirà una schermata in cui scelga la terza opzione Search titles in Gopherspace using Veronica. Si crei un segnalibro in Netscape o Explorer per ritrovare questo punto se necessario. Eccoci di fronte al menu di Veronica. Veronica consente di specificare delle parole che verranno cercate nei titoli dei documenti presenti sui Gopher oppure, se si vuole più rapidità, nei soli nomi delle directory gestite dai server. Le due scelte corrispondono alle opzioni Find Gopher Directories e Search Gopherspace. Scegliete quella che preferite e digitate il testo da cercare.
Esercizio (6 punti)
Trovare via Veronica i documenti sulla logica modale ("modal logic") presenti sul Gopher
Le ricerche con Veronica sono lente (un minuto o due al minimo) e durante l'attesa non compare alcun messaggio sullo schermo. non preoccupatevi e attendete fiduciosi. Infine, comparirà una lista di elementi trovati, alcuni con l'etichetta DIR(directory), o FILE (file di testo). Facendo clic su di essi potrete accedere ai dati voluti.
Esercizio(25 punti)
Eseguite a scelta uno dei seguenti esercizi:
1- Usate Internet per trovare i migliori reparti chirurgici italiani ed europei dove si esegue il trapianto di fegato (in inglese: liver transplant). Immaginando di rivolgervi a un paziente, stendete un breve rapporto sui risultati della vostra ricerca, specificando i motori che avete usato.
2- Usate Internet per trovare i nuovi modelli della casa automobilistica coreana Daewoo. Immaginando di rivolgervi a un possibile acquirente o importatore, stendete una tabella con fotografie, caratteristiche e prezzi specificando i motori che avete usato
Se la montagna non va a Maometto..
Anche se gli utenti diventano sempre più bravi nel cercare informazioni sulla Rete, i progettisti Web sono ugualmente impegnati dello sforzo di trasformare lo schermo del computer in qualcosa di simile a quello di un televisore facendo in modo che siano le informazioni che desideriamo ad arrivare da noi. Il modulo Netcaster di Netscape consente di abbonarsi ai siti Web e di ricevere automaticamente le pagine Web aggiornate, mentre si sta lavorando con altro. Funzionalità simili sono offerte dall’ultima versione di Microsoft Explorer.
Il server push
L'ultima novità della tecnologia Web è il server push, che si basa sull'idea che si può usare un server Web per far arrivare le pagine al computer dell'utente senza aspettare che sia lui a visitare il sito. Per ottenere ciò, dovete prima abbonarvi al sito Web trasmittente che vi invierà automaticamente gli aggiornamenti. Questo vi permetterà di pianificare quando ricevere gli aggiornamenti delle pagine e di fare in modo che giungano al vostro calcolatore mentre state lavorando ad altro. Le pagine Web arrivate possono poi essere visualizzate con calma dal proprio disco locale. Anche se per il trasferimento è richiesta la stessa quantità di tempo, almeno non è necessario aspettare.
In realtà, il termine "server push" può essere fuorviante perchè in realtà il sito non spinge affatto le pagine verso il vostro computer. Quello che accade è che invece di digitare l'indirizzo di una pagina o di fare clic su un collegamento per aprirne una, si comunica al browser da quali "stazioni emittenti" ricevere gli aggiornamenti. In questo modo si rende possibile, almeno in una certa misura, la navigazione offline o fuori linea, minimizzando il tempo di connessione alla Rete che occorre per navigare sul Web. Molte aziende e centri di ricerca sono impegnati a trovare dei modi per rendere più veloce Internet. Le società che producono cavi, modem e dispositivi di commutazione hanno seguito il un approccio hardware al problema , cercando di aumentare la velocità a cui i dati viaggiano su Internet. Queste soluzioni, però richiedono spesso agli utenti più tempo e denaro di quanti vogliano investire.
Il server push rappresenta una soluzione parziale, ma economica allo stesso problema. Invece di aspettare dall'utente la richiesta di pagine, i siti Web possono trasmettere il contenuto aggiornato al vostro calcolatore mentre siete occupati a fare dell'altro. In seguito, il vostro calcolatore è automaticamente disconnesso da Internet e voi potete navigare visualizzando le pagine fuori linea.
Netcaster fondamentalmente è il telecomando per questa trasmissione via Web. Si esegue la programmazione dei canali che si desidera visualizzare e poi li si può vedere semplicemente facendo clic su un pulsante. La lista Channel Finder di Netcaster elenca oltre cento siti Web famosi che hanno già registrato le loro "stazioni trasmittenti" con Netscape. Lo stesso vale naturalmente anche per Microsoft Explorer
Esercizio (5 punti)
Se disponete delle ultime versioni dei browser date un'occhiata all'elenco dei canali messi a disposizione e fateci sapere quali sono per voi i più interessanti.
Tutorial 8
Creare pagine e siti Web
In questo tutorial approfondiremo l'uso di HTML e il progetto delle pagine Web. In particolare si vedranno alcuni esempi di pagine HTML, si analizzeranno le differenze tra il Web e gli strumenti tradizionali e si descriveranno i principi base del progetto di pagine; poi si parlerà del server web e di come fare a pubblicare le proprie pagine sul Web. Il Web è pieno di programmi interattivi, giochi e presentazioni che si dovrebbero sperimentare di prima mano. In questo tutorial parleremo degli strumenti usati per crearli: applet Java, spezzoni Shockwave e i programmi per esplorare i mondi interattivi tridimensionali.
HTML per esempi
Diamo ora un rapido ripasso degli elementi di HTML appresi nei tutorial precedenti. Ricordiamo anzitutto la struttura generale di un semplice documento HTML:
<HTML>
<TITLE> qui va il titolo </TITLE>
<BODY>
<H1> titolo </H1>
testo del documento
<ADDRESS> indirizzo del compilatore del documento </ADDRESS>
</BODY>
</HTML>
Titoli
I titoli sono di tre livelli a seconda delle dimensioni. Ecco i marcatori per delimitarli:
<H1> ..... </H1>
<H2> ..... </H2>
<H3> ..... </H3>
Notate che questi marcatori definiscono le dimensioni relative e non quelle assolute del testo. Su questo tema torneremo nel seguito del tutorial
Comandi vari
Ecco alcuni semplici comandi di formattazione:
<B> ... </B> grassetto
<I> ... </I> corsivo
<P> fine paragrafo (a capo con riga bianca)
<BR> break (a capo semplice)
<!-- inizio commento; fino a --> il testo non viene interpretato
<PRE> .... </PRE> il testo compreso tra i due comandi non viene formattato
<HR> inserisce una riga orizzontale continua
Link
I link consentono di collegare il documento o una porzione di documento a un altro documento. Il collegamento è effettuato tramite il nome di un file (se nome di directory, si sottintende index.html). I collegamenti sono effettuati tramite "ancore", indicate con <A> e terminate con </A>.
Esempio:
<A HREF="curri.html">Fai clic qui per vedere il mio curriculum</A>
Immagini
Si includono con il marcatoriIMG. E' senz'altro il comando che ha dato al WWW l'impulso maggiore perché permette il controllo dell'inserimento della grafica nelle pagine Web. La forma minima, come sappiamo, è la seguente:
<IMG src="nomefilegrafico.gif">
In forma estesa:
<IMG src="nomefilegrafico.gif"> alt="testo alternativo" align=bottom/middle/top/left/right/texttop/absmiddle/baseline/absbottom,height=valore width=valore units="unità alternativa" border=valore, lowsrc="filebassariso.gif" hspace=valore vspace=valore>
Il testo alternativo (attributo alt ) è la frase che compare al posto dell'immagine a chi non ha un browser grafico. Per l'allineamento (align), fate delle prove includendo un immagine con tutti i valori possibili.
Esercizio(5 punti)
Quali dei valori di allineamento sono attributi riconosciuti solo da Netscape ? height e width stabiliscono la dimensione dell'immagine in pixel; ricordate che la maggioranza degli utenti tiene gli schermi impostati a 640 per 480 pixel e che la finestra del browser è sensibilmente più piccola.
Units consente di specificare un'unità di miura diversa dal pixel (ad esempio in, pollici).
Border inserisce un bordo attorno all'immagine, il cui spessore in pixel è dato dal valore.
Lowsrc definisce il nome di un file grafico a bassa risoluzione, quindi piccolo e svelto da caricare, che viene presentato mentre si carica il file grafico finale, cioè quello indicato da SRC. Si tratta di una tecnica vitale per non perdere chi ha collegamenti lenti.
Hspace e vspace definiscono (in pixel) lo spessore di uno spazio vuoto attorno all'immagine.
Siamo ora pronti per seguire un esempio un po' più complicato Esaminate la pagina che segue e provate a visualizzarla in locale con il vostro browser. Capite il significato di tutti i marcatori usati?
<HTML>
<HEAD>
<TITLE>Polo Didattico e di Ricerca di Crema</TITLE>
</HEAD>
<BODY>
<H1>Teledidattica
via Internet<BR>
Main
Menu</H1>
<P><HR>
<A
HREF="people"><IMG SRC="icons/personal.gif"
ALIGN=middle></A> <A
HREF="people">Collaboratori</A><BR>
<P>
<A
HREF="course "><IMG SRC="icons/corsi.gif"
ALIGN=middle></A> <A HREF="course
">Corsi</A><BR>
<P>
<UL>
<LI> <A HREF="link.html">Internet: primo livello </A><BR><BR>
<LI> Internet: secondo livello<BR><BR>
<LI> Altri corsi <BR><BR><BR>
</UL>
<P> <A HREF="index.html"><IMG SRC="icons/up.gif" ALIGN=middle></A> <A HREF="index.html"> Alla pagina iniziale </A>
<P><HR>
<ADDRESS><A
HREF="internetcourse.html">corso@medusa.crema.unimi.it</A>,
May. 10, 1997 </ADDRESS>
</BODY>
</HTML>
Come vi sarete accorti che le immagini e i collegamenti della pagina d'esempio non funzionano. Il motivo è che mancano i file relativi.
Esercizio (15 punti)
Aggiungete esempi delle pagine necessarie e fate in modo che i collegamenti funzionino.
Proseguire nello studio di HTML
I marcatori HTML sono tantissimi. HTML esiste in diverse versioni; quella riconosciuta da tutti i browser attuali è la 2.0 La più recente è HTML 3.2. Per informazioni sulle varie versioni dello standard si possono visitare le URL seguenti:
HTML 2.0 http://www.w3.org/hypertext/WWW/MarkUp/html-spec/html-spec_toc.html
HTML 3.2 http://www.w3.org/pub/WWW/MarkUp/Wilbur/
I pochi marcatori visti fino qui riguardano la presentazione e, come vi sarete accorti, non si fa cenno all'interazione con gli utenti, che sarà trattata nei prossimi tutorial. Anche l'impaginazione tuttavia migliora molto se si usa l'importantissimo marcatore <TABLE>, che consente di disporre gli elementi in una tabella sulla pagina, garantendone l'allineamento.
Esercizio (20 punti)
Procurartevi dal sito W3 (vedi seguito) la definizione del marcatore TABLE e create una pagina HTML con due colonne di testo, usando la tabella per l'allineamento.
Per avere una visione completa dei marcatori, potete fare un salto a http://weblab.crema.unimi.it/tppmsgs/msgs0.htm#36
Si tratta della sede del WWW
Consortium, l'organismo che segue l'evoluzione del linguaggio HTML. Qui troverete
anche materiale interessante sul linguaggio. A quest'altro indirizzo, che in
parte già conosciamo: http://lcweb.loc.gov/global/html.html
ci sono tutti i collegamenti a materiale su HTML noti alla Biblioteca del
Congresso.
Come abbiamo visto, le tabelle non si usano solo per creare matrici di dati. E' possibile utilizzare le tabelle anche per dare una struttura grafica alle pagine.
Ad esempio, si può usare una tabella per creare una barra dei pulsanti. Se si va alla home page di Netscape si vede un'immagine mappa nella parte superiore della pagina che offre dei pulsanti etichettati Netscape Destinations, Company & Products e così via. E' possibile creare una barra simile usando una tabella. Create semplicemente una tabella di una riga nella parte superiore della pagina e in ciascuna inserite un collegamento. Si puì anche ingrandire il margine della cella e la larghezza del bordo e aumentare la dimensione del testo.
Il supporto dei browser per le tabelle
Le tabelle si sono dimostrate così utili che solo alcuni vecchi browser rifiutano ancora di gestirle. Sfortunatamente molte persone utilizzano ancora questi browser. Se guardano una delle pagine formattate a tabella, è probabile che vedano solo una parte disorganizzata di testo e grafica. E' facile evitarlo scegliendo HTML dal menu Visualizza e poi inserendo il marcatore <BR> alla fine di ogni cella della tabella appena prima del marcatore </TD>. L'inserimento di <BR> fa sì che i browser che non capiscono la tabella mostrino i contenuti delle celle impilati nell'ordine in cui sono scritti. Con il contenuto in un ordine logico la pagina è ancora leggibile. Per variare la spaziatura si può usare anche il marcatore <P> ma questo influenzerà la visualizzazione nei browser che supportano le tabelle, quindi ci si assicuri di essere coerenti.
I frame
Un frame o riquadro è una parte di una pagina HTML che ne contiene un’altra (ovviamente, miniaturizzata). Non si tratta di un collegamento: nel riquadro c’è proprio tutta una pagina, completa di elemenri grafici e collegamenti ipertestuali. Se usati con moderazione, i frame possono aiutare a rendere un sito Web più facile da navigare. Ad esempio si può creare un riquadro che visualizza un sommario, completo di collegamenti, e usare un riquadro ausiliario per mostrare i contenuti del collegamento selezionato nel primo riquadro. Questo permette ai visitatori di navigare con facilità perdere mai di vista il sommario. Si tenga presente, però, che è consigliabile non usare mai più di tre frame su una sola pagina. Troppi frame distolgono l'attenzione dalla pagina Web principale rendendo difficile navigare sul sito.
Per creare dei frame basta inserire i loro marcatori in una pagina Web. Questi marcatori comunicano al browser Web come dividere la sua finestra in riquadri e quale pagina caricare in ogni riquadro. Si ha la massima libertà di azione con questi codici, ad esempio è possibile nidificare una serie di marcatori dei frame in un'altra.
Ora, però, vedremo i marcatori da inserire per creare una semplice finestra a due frame e poi si vedrà come modificare i parametri dei marcatori per migliorare il progetto. Prima si creino con Blocco Note tre pagine Web: quella dove inseriremo i marcatori per la creazione di frame e due pagine ausiliarie, una da mostrare nel riquadro di sinistra e l'altra in quello di destra. Attenzione: ad uso dei vecchi browser Web che non sono in grado di visualizzare i frame è meglio mettere i marcatori dei frame all’inizio del file della pagina Web principale. Questi marcatori dicono al browser le operazioni da eseguire se riesce a gestire i frame . Subito dopo, potrete inserire una pagina tradizionale di scorta ta i marcatori <NOFRAME></NOFRAME>; un browser che non sa gestire i frame potrà così visualizzare la pagina di scorta senza frame Ora si apra il file della pagina Web principale nell'editor di testi e si sposti il punto d'inserimento prima deil marcatore <BODY>; i marcatori di creazione dei frame non possono essere posti tra i marcatori <BODY> e </BODY>. Si immettano i marcatori seguenti:
<FRAMESET
COLS="25%, 75%">
<FRAME
SRC="index.htm" NAME="index">
<FRAME
SRC="main.htm" NAME="main">
</FRAMESET>
<NOFRAME>
{Si inserisca qui il contenuto della pagina Web di scorta}
</NOFRAME>
Visualizzate la pagina nel browser per avere un’idea dell’effetto prima di tornare indietro e modificare i marcatori per sistemare il progetto La lista seguente considera i marcatori uno per uno, spiega la funzione di ciascuno e chiarisce come modificarli:
<FRAMESET COLS="25%, 75%"> Attiva i frame e divide la finestra in un riquadro di sinistra e uno di destra. Quello di sinistra è pari al 25 per cento della larghezza della finestra del browser e lascia il 75 per cento al riquadro destro. Si possono inserire diverse percentuali. Per dividere la finestra in un riquadro superiore e uno inferiore si può usare <FRAMESET Rows="25%,75%">
<FRAME SRC="index.htm" NAME="index"> Questo marcatore comunica al browser quale pagina Web caricare nel primo riquadro, in questo caso quello di sinistra. Al posto di index.htm si digiti il nome del file della pagina Web che si vuole venga visualizzato nel riquadro di destra; ad esempio la classifica che avte creato in precedenza. Al posto di index, dopo NAME= si digiti un nome per il riquadro, qualcosa che sia facile da ricordare.
<FRAME SRC="main.htm" NAME="main"> Questo marcatore comunica al browser quale pagina Web caricare nel secondo riquadro, in questo caso quello di destra. Al posto di main.htm si digiti il nome del file della pagina Web che si vuole venga visualizzata nel riquadro di destra. Al posto di main, dopo NAME=, si digiti un nome per il riquadro.
</FRAMESET> Questo marcatore dice semplicemente che si è terminata la definizione dei frame
.
<NOFRAME> Questo marcatore dice al browser Web cosa deve fare se non sa gestire i frame . Alcuni browser più vecchi non sono in grado di interpretare i marcatori dei frame .
{ Si inserisca qui il contenuto della pagina Web } Al posto di questo commento, si deve inserire qui una pagina alternativa per i browser che non sanno visualizzare i frame. E' possibile immettere un semplice collegamento che fa riferimento a una pagina senza frame oppure i marcatori di un'intera pagina Web.
</NOFRAME> Questo è il marcatore di chiusura per NOFRAMES.
Va notato che invece di immettere delle impostazioni precise per le dimensioni dei frame , si possono usare degli asterischi per fissare delle dimensioni relative. Ad esempio invece di inserire <FRAMESET COLS="25%,75%"> si potrebbe digitare <FRAMESET COLS="*,3*">. Questo comunica al browser di dare una parte della finestra al riquadro di sinistra e tre parti a quello di destra.
Se si apre la pagina con i frame in Navigator o Explorer e si prova a usare la classifica nel riquadro sinistro per aprire le pagine, accade qualcosa di molto preoccupante. Quando si fa clic su un collegamento nel riquadro di sinistra, la classifica scompare e viene sostituito dalla pagina a cui fa riferimento il collegamento. Il browser "non sa" che si pensava aprisse la pagina nel riquadro di destra.
Per risolvere questo problema si deve aggiungere al marcatore di destinazione un attributo, che comunica al browser quale riquadro usare per visualizzare la pagina collegata. Il marcatore seguente comunica al browser di aprire la pagina Hollywood OnLine nel riquadro denominato main:
<A
HREF="http://www.hollywood.com/" target=main>Hollywood
Online</A>
Il nome main deriva dai marcatori dei frame inseriti nell’esempio precedente.
Un po’ di stile
Prima di buttarvi a realizzare pagine HTML, rispondete a questa domanda: come è fatta una "bella" pagina Web ? Se ci pensate un po' vedrete che non è facile rispondere. Se provate a eseguire una ricerca con Yahoo cercando"style" o "design," assieme a "WWW" e "HTML," (fatelo!) troverete moltissimi articoli tra cui alcune guide stilistiche complete. Ecco quella del creatore del Web, Tim Berners-Lee http://weblab.crema.unimi.it/tppmsgs/msgs0.htm#38
Un'altra ottima è http://www.willamette.edu/html-composition/strict-html.html
Peccato che tutte le guide abbiano un piccolo difetto: riflettono solo le idee del loro autore. Dai siti che abbiamo visitato in questo corso, comunque, dovrebbe apparire chiaro che una pagina HTML non è la stessa cosa di una pagina su carta; piuttosto è simile alle schermate di interfaccia che vengono presentate dai programmi per Mac o per Windows, con pulsanti, caselle da riempire, animazioni, punti cliccabili e così via. Non bisogna mai gettarsi a testa bassa a scrivere in HTML pensando di sapere già tutto sulle esigenze e gli interessi di chi visiterà le pagine. Procuratevi un riscontro immediato; se state progettando pagineWeb per una scuola media, chiamate qualcuno dei bambini e fateli partecipare al ciclo di progetto.
Le pagine Web non sono "vere pagine"
Come molti progettisti grafici hanno scoperto a loro spese il nome di "pagine" dato alle pagine HTML è fuorviante; non c'è niente di più diverso da una pagina stampata di una pagina Web. La pagina stampata appare ai nostri occhi tutta insieme, e gli elementi grafici guidano lo sguardo del lettore sugli elementi chiave (un titolo, una figura, un sommario). Solo dopo aver avuto un colpo d'occhio sulle cose più importanti il lettore è lasciato libero di vagare per il corpo del testo. Le pagine Web invece vengono caricate lentamente, soprattutto se contengono immagini. Dopo che sono caricate, occorre eseguire uno scorrimento per vederle tutte sui piccoli schermi della maggior parte dei computer. Il ruolo degli elementi grafici non è solo di guida, poichè devono intrattenere il visitatore intanto che il contenuto arriva. Quindi attenzione: il vostro problema non sarà imparare HTML, che è relativamente facile, ma capir come usarlo bene.
Ecco le sei caratteristiche del Web che lo differenziano da un mezzo di stampa:
1 Chi progetta il sito web non è l'autore: l'autore è chi lo visualizza
2 Il Web è una visualizzazione orizzontale (la carta è verticale)
3 La gente si stanca più velocemente di leggere sullo schermo del computer
4 Si ha un controllo limitato sulla posizione e l'aspetto dei caratteri
5 Il Web è un'esperienza multimediale
6 Il Web è un'esperienza ipermediale
nel seguito le commenteremo brevemente una per una.
L'autore è chi visualizza il sito
Poichè sono coinvolti molti tipi diversi di contenuto, è più probabile che un sito Web venga creato da un gruppo che da una singola persona; tuttavia anche se sarete l'unico creatore di un intero sito, non potrete mai esserne l'autore a meno che non siate l'unica persona che usa il sito. Questo avviene perchè se il sito è progettato in modo corretto, ogni persona che lo visualizza avrà un'esperienza diversa. La maggior parte delle persone leggono un libro o un articolo di una rivista dall'inizio alla fine, da sinistra a destra, dall'alto in basso. Lo scrittore crea l'esperienza per il lettore. Nel processo di navigazione sul Web i lettori o coloro che visualizzano il sito creano la propria esperienza, in altre parole sono loro gli autori.
La visualizzazione orizzontale
Tutti sono abituati a osservare le pagine stampate e tendono a usarle come riferimento nei progetti di comunicazione. Il progetto HTML è ben diverso dal progetto delle pagine stampate. Se i progetti Web devono essere paragonati a un mezzo tradizionale, forse quello dovrebbe essere la televisione. Le pagine stampate di solito sono fatte in modo che il layout verrà visto in una posizione verticale. Gli schermi dei computer, d'altra parte, sono come gli schermi della televisione, infatti sono più larghi che alti. Un motivo per cui le dimensioni delle finestre dei browser sono più strette di circa un terzo rispetto allo schermo è per evitare di avere delle righe di testo troppo lunghe per un esame veloce. Si ricordi che se il testo non è posto in una colonna a larghezza fissa di una tabella, il browser lo farà scorrere fino ad adattarlo alla finestra. L'orientamento orizzontale dello schermo dei computer di solito rende invisibile la parte superiore e inferiore del contenuto di una pagina. Il ruolo dei grafici sul Web è ben diverso quindi da quello che hanno nelle pubblicazioni su carta.
L'importanza di un testo breve
Quando si legge un libro è facile dopo un po' di tempo che si sia stanchi di rimanere fermi. Il monitor di un computer tende a tenere l'utente ancor di più fisso in un posto. Inoltre lo schermo è illuminato da dietro, il che rende il fatto di osservarlo simile a guardare i fari anteriori di una macchina che sta arrivando. Nessuno può sentirsi a proprio agio per molto tempo Si tenga quindi il testo breve e si dividano i paragrafi lunghi in parti corte. Si diano agli utenti molti collegamenti in modo che possano muoversi all'interno del sito quando sono stanchi.
I limiti del controllo
Una delle principali lamentele tra i progettisti grafici che lavorano sul Web è la mancanza di controllo sui caratteri. Dagli esempi delle scorse lezioni dovrebbe essere charo che HTML consente di stabilire l'ordine relativo delle informazioni che l'utente vedrà ma non la loro posizione o dimensione assoluta. Il Web browser si incaricherà di stabilire dove sullo schermo dell'uente andrà un certo elemento e quanto sarà grande, anche se voi stabilite cosa viene prima di cosa e cosa è più grande di cosa.
Le pagine Web sono visualizzate su
molti tipi di computer e le prime versioni di HTML non fornivano alcun metodo
per controllare il tipo di carattere usato. Le richieste in questo senso sono
state tali che i due sviluppatori principali di browser hanno iniziato a
incorporare alcuni controlli dei caratteri specificati in HTML 3.2. Per la
prima volta nelle loro versioni 3.0, Netscape Navigator e Microsoft Internet
Explorer hanno introdotto dei marcatori che consentono di specificare i tipi di
carattere effettivi.
FrontPage 97 è il primo strumento autore HTML per permettere di specificare i
tipi di carattere. Si può utilizzare qualsiasi tipo di carattere installato sul
sistema (Windows 95 e in futuro Macintosh). E' possibile anche specificare le
dimensioni in punti. Questa è la grande novità. Il lato negativo è che solo
Microsoft Internet Explorer 3.0 e successivi e Netscape Navigator 3.0 e
successivi saranno in grado di vedere questi caratteri come sono stati
progettati. Inoltre questo avviene solo se i tipi di carattere sono installati
sul computer dell'utente. Se un determinato tipo di carattere non viene
trovato, il browser mostra il tipo di carattere che l'utente ha selezionato per
la visualizzazione generale.
La maggior parte degli altri browser consente di controllare la dimensione del testo solo attraverso una dimensione relativa. <H1> può essere più grande di <H2> ma la larghezza esatta dipende dal browser e dalla piattaforma su cui viene visualizzato. Inoltre non sono disponibili molti tipi di carattere. Vi è un buon motivo per questi limiti: essi danno un potenziale pubblico più esteso di quanto si avrebbe altrimenti. Lo scopo di Internet è fornire delle informazioni in un modo che sia visualizzabile su quasi ogni computer del mondo.
I collegamenti
La caratteristica più specifica del World Wide Web sono i collegamenti ipertestuali. Se si progettano questi collegamenti in modo che sia facile e divertente spostarsi tra molte informazioni diverse, vi sono buone probabilità che il sito abbia successo. Parte del segreto è assicurarsi che sia facile sia arrivare al punto a cui conduce un collegamento sia ritornare indietro. Un altro punto importante consiste nel tenere i segmenti informativi il più ridotti possibile senza però tralasciare informazioni importanti. Ci si assicuri che i lettori sappiano l’argomento di un segmento informativo, prima di vederlo. I lettori devono essere in grado di muoversi velocemente se il materiale non li interessa. Inoltre la tendenza dei lettori è quella di saltare ciò che non afferra immediatamente il loro interesse. Questa è la conseguenza di una quantità eccessiva di informazioni sul Web e del fatto che risulta ancora molto più lento scaricare le pagine web rispetto a girare una pagina in un libro.
Le funzioni multimediali del Web
Forse la differenza più ovvia tra la stampa e il Web sta nelle capacità multimediali del Web. Il World Wide Web è stato inventato come veicolo per fornire elementi multimediali su Internet. L'intento dei suoi inventori fu fornire un contesto per del contenuto stimolante sia da vedere che da sentire. Il fatto che i primi browser come Netscape 1.1 e Mosaic riconoscevano solo il marcatore HTML più primitivo e non erano compatibili con molti del plug-in multimediali più famosi odierni, sembrava quasi essere in contraddizione con lo scopo iniziale. I browser odierni sono molto più avanzati nella loro capacità di visualizzare sia elementi multimediali sia controlli più precisi di progettazione.
Attenzione alla tecnologia
Se le pagine che create sono rivolte al pubblico generale del World Wide Web, usate la grafica con moderazione. La maggior parte degli utenti utilizza modem 28,8 kbps e molti usano ancora modelli 14,4 kbps. Queste connessioni sono 10 volte più lente delle connessioni ISDN e 100 volte più lente delle connessioni dedicate a 2 Mbps come quelle (sia pur condivise!) messe a disposizione da molte Università. Nel corso avanzato verranno forniti dei consigli e un aiuto per creare dei video efficienti da mostrare sul web; questo include l'animazione creata al computer e i file audio analogici (AIFF su Mac o WAV su Windows).
Le regole fondamentali della progettazione
Esistono alcuni principi di progettazione che si applicano a tutti i mezzi di informazione. Se non siete progettisti grafici professionisti a cui l'esperienza ha già insegnato queste regole, non affliggetevi. Queste regole di base sono date semplicemente dal buon senso. Le si può imparare velocemente oppure si possono già sapere d'istinto. Le si utilizzi e il vostro lavoro non sembrerà quello di un profano.
La creazione di uno storyboard
Una tecnica comune nella progettazione richiede che si delineino a mano prima le proprie idee. Questo può dare l'impressione che per fare belle pagine HTML si debba essere un artista, ma non è affatto così . Non bisogna mostrare lo storyboard a nessuno; non serve l'approvazione di alcun comitato. La tecnica migliore per i neofiti consiste semplicemente nel fare lo schizzo delle pagine su delle schede e poi disporle sul pavimento e scoprire dove portano i collegamenti. Se i collegamenti non funzionano o non si è soddisfatti dell'organizzazione delle pagine, si riordini la disposizione delle schede e si ritraccino i collegamenti. Non ci si preoccupi del tempo che si investe in questa fase del progetto. Ogni dieci minuti che si trascorrono lavorando sullo storyboard faranno risparmiare tre ore del tempo di sviluppo del sito.
Risparmiare banda
Nel progettare pagine Web, ci si ricordi sempre che solo una minoranza dei monitor esistenti ha una dimensione maggiore di 15 pollici. Sebbene sia possibile impostare schermi piccoli a risoluzioni maggiori, la grande maggioranza delle odierne macchine Mac e Windows sono impostate a 640x480. Anche quando un utente ha uno schermo più grande, la finestra del browser è spesso impostata a una dimensione inferiore. Gli utenti si annoieranno se devono trascorrere del tempo a ridimensionare la finestra prima per leggere il suo contenuto Infine, bisogna tenere a mente i problemi di prestazioni. Sebbene vi siano molti trucchi e tecniche per fare in modo che le pagine vengano caricate più velocemente, tutto si riduce a ricordare alcuni fatti di base In primo luogo, la grafica DIVORA la larghezza di banda. Per fortuna c’è un trucco semplice ed efficace che si può adottare: ogni volta che è possibile, si replichino gli stessi grafici in diverse posizioni nel sito. La maggior parte dei browser memorizza ciò che è già stato scaricato in una memoria temporanea sull'unità a disco fisso del client in modo che quando si chiama un'immagine per la seconda volta, la carica dall'unità a disco fisso locale invece che attraverso la connessione modem. I grafici sovradimensionati e una sovrabbondanza di elementi multimediali sono comunque le cause principali dei caricamenti lenti delle pagine web. Una buona fonte per altri consigli su come risparmiare la larghezza di banda è la Bandwith Conservation Society che si trova al seguente URL: http://weblab.crema.unimi.it/tppmsgs/msgs0.htm#40
Indipendenza dalla piattaforma
Il World Wide Web è stato progettato per funzionare su Macintosh, Windows, DOS e Unix. Vi sono però alcuni punti che bisogna tenere presenti, se si vuole che le proprie pagine abbiano una buona resa su tutti questi sistemi. Anzitutto, si utilizzino i colori indipendenti dal browser. Sia Netscape Navigator sia Microsoft Internet Explorer usano delle tavolozze da 216 colori sui sistemi che possono visualizzare solo 256 colori (standard VGA). Se una tavolozza contiene solo quei colori per i quali si è sicuri che Netscape Navigator e Microsoft Internet Explorer li interpreteranno correttamente, viene chiamata tavolozza indipendente dal browser. Si utilizzino i colori indipendenti dal browser solo per grafici semplici e non si cerchi di utilizzarli per opere d'arte ombreggiate o fotografie.In secondo luogo, si ricordi che le finestre di Windows sono più piccole Le finestre dei browser per la maggior parte dei browser Windows, escluso Microsoft Internet Explorer, sono più piccole di una coppia di righe di testo a 12 punti rispetto alle loro controparti Macintosh. Questa è una differenza sufficiente per eliminare le didascalie sotto a una fotografia o nascondere la barra di spostamento inferiore, quindi se si stanno creando delle pagine su un Mac, si realizzino le pagine di una coppia di righe più corta di quanto sembri necessarioInfine, un ultimo avvertimento: se si creano i grafici su un Macintosh si tengano le immagini più chiare possibili. Questo avvertimento non si applica a che crea le immagini sui computer Windows. I Macintosh visualizzano grafici leggermente più luminosi delle macchine Windows. Questa reputazione sembra derivare dal fatto che molti utenti Windows impostano i loro schermi, di solito per nessun apparente motivo, a soli 256 colori, il che rende scure le fotografie e agli altri grafici non progettati con colori indipendenti dal browser. Se si stanno creando i grafici su un Mac li si schiarisca almeno un po'.
Un altro modo per mantenere un certo controllo sull'aspetto grafico delle pagine è utilizzare i marcatori dei tipi di carattere. Fino a poco tempo fa non esisteva un modo per specificare il carattere tramite le misure convenzionali come i punti, i pica o i pollici. Anche adesso che Netscape Navigator e Internet Explorer supportano la dimensione dei tipi di carattere, la maggior parte degli utenti utilizza dei browser che non supportano questo tipo di controllo. HTML tradizionalmente specifica le dimensioni dei caratteri rispetto alla dimensione dei caratteri predefinita nel browser che visualizza la pagina. La dimensione effettiva di questo carattere predefinito varia da browser a browser e da piattaforma a piattaforma. Ad esempio Netscape Navigator è impostato sul tipo di carattere Times Roman a 12 punti ma gli utenti possono specificare qualsiasi font e dimensione scelgano in Preferences. Sul Macintosh il carattere Times Roman a 12 punti appare più piccolo che su Windows. Times 12 sul Mac è circa l'equivalente di Times10 sul PC.
Vi sono due modi per modificare la dimensione del carattere nel marcatore HTML. Prima della specificazione W3C HTML 3.2 si doveva usare un marcatore d'intestazione (<H1>-<H6>). Netscape poi ha introdotto i marcatori <FONT SIZE=1>-<FONT SIZE=7>. I marcatori d'intestazione comportano un invio a capo forzato alla fine del marcatore in modo che non si possa inserire un carattere più grande all'interno di un paragrafo. La soluzione di Netscape, ora adottata da molti altri browser, è utilizzare il marcatore <FONT SIZE=valore>; i browser che non supportano la dimensione del carattere lo ignoreranno. Si può iniziare e finire il marcatore <FONT SIZE=valore> ovunque nel testo. Nessun invio a capo obbligato è posto dopo di esso, rendendo possibile la modifica delle dimensione del carattere ovunque all'interno del paragrafo. La dimensione del carattere predefinita nella maggior parte dei browser è l'equivalente di <FONT SIZE=3>. Recentemente Netscape ha fatto ulteriori passi avanti e il marcatore <FONT SIZE=valore > può essere usato per specificare le dimensioni in punti esatte. Come probabilmente si sarà già dedotto, le versioni di Netscape Microsoft Internet Explorer successive alla 3.0 alsupportano i marcatori <FONT SIZE=valore>.
Elementi multimediali
Una recente innovazione del Web è la possibilità di ricevere audio e video in tempo reale. Fino a poco tempo fa bisognava scaricare un intero file audio o video prima di poterlo vedere o sentire. La nuova tecnologia detta flow o di flusso ha cambiato tutto. Quando un file che usa questa tecnologia viene scaricato inizia l'esecuzione non appena arriva sufficiente materiale al computer client per consentire che il resto venga scaricato prima che il filmato finisca la sua esecuzione. Questo tipicamente significa che un video verrà scaricato e inizierà l'esecuzione in circa un terzo del tempo che altrimenti sarebbe necessario. Per inserire qualsiasi tipo di elemento multimediale in una pagina HTML basta usare il marcatore <EMBED>.
Attenzione però: non sempre la visualizzazione avviene correttamente. Se l'utente vede ciò che si è incorporato, è solo merito del fatto che egli ha la combinazione browser/plug-in richiesta.
I browser della prima generazione non riuscivano a vedere questo tipo di materiale. Ciò non sarà un problema se si aiutano i vecchi browser usando i marcatori <NOEMBED> e <IMG> insieme al marcatore <EMBED> per inserire un grafico laddove l'evento multimediale verrebbe visualizzato in un browser più avanzato. Ecco un esempio per mostrare come sistemare questi marcatori. In questo esempio si vuole incorporare un file video .mov in una pagina Web e fornire un'immagine GIF come alternativa per gli utenti che non possono visualizzare un file video. Ne risulta il codice:
<EMBED
SRC=video.mov>
<NOEMBED>
<IMG
SRC="still.gif">
</NOEMBED>
Queste stesse istruzioni possono essere usate per incorporare VRML, RealAudio o qualsiasi altro materiale eseguito dai plug-in.
Esercizio di rilassamento (0 punti)
visitate alcune pagine che secondo noi meritano davvero e facendoci avere il vostro giudizio:
Online
Bonsai Icon Collection http://www.hav.com/~hav/tobicus.html
Secrets
of the Sega Sages http://www.segasages.com/
Disney
Home Page http://www.disney.com/
Active
Worlds http://www.activeworlds.com
La pubblicazione della pagina
Quando una pagina ha tutti i requisiti di buona pagina Web si possono darle gli ultimi tocchi e poi pubblicarla sul Web. Vedremo ora come trasferire una pagina a un server Web rendendola accessibile a chiunque nel mondo possieda un computer, un collegamento a Internet e un browser Web.
Se si sta lavorando direttamente su un server Web, un computer connesso permanentemente a Internet che ospita il programma che fornisce le pagine Web ai browser, non si deve fare proprio nulla per posizionare la pagina sul Web. Quando si salva la pagina in una directory sul server Web, la si sta già pubblicando. Si ricordi infatti che la parte terminale di un URL è proprio il percorso della directory in cui è posta la pagina. Se si salva la pagina parade.htm sul disco del server pluto.unimi.it nella directory pippo, la pagina diventa immediatamente visibile alla URL http://pluto.unimi.it/pippo/prova.htm e i collegamenti verso di lei presenti su altre pagine del Web diventano validi. Se invece si sta lavorando sul proprio personal computer si dovrà trasferire la pagina via FTP al server Web per renderla disponibile.
Trovare una collocazione per la propria pagina
Prima di iniziare è necessario essere sicuri di sapere dove mettere la pagina Web. La cosa migliore da fare è chiamare il proprio provider Internet. La maggior parte dei provider mette a disposizione degli abbonati dello spazio sui propri server Web in modo che possano memorizzare le pagine Web personali. Si chiami il provider e si verifichino le seguenti informazioni:
1 Il provider rende disponibile dello spazio Web agli abbonati. Alcuni provider offrono una quantità limitata di spazio su disco che di solito vale per una o due pagine Web.
2 L'indirizzo del server a cui ci si deve connettere per trasferire il file della pagina
3 Il nome utente e la password necessari da inserire per ottenere l'accesso al server FTP.
4 La directory nella quale si deve collocare il file e il nome da assegnare alla pagina Web. In molti casi il servizio consente di inviare una singola pagina Web e lo si deve chiamare index.html.
Una volta che la pagina è sul Web, la si apra e la si controlli di nuovo per essere sicuri che non sia stata danneggiata durante il trasferimento, che tutti i grafici e le linee sono posizionate correttamente e che i collegamenti funzionino. Se si ha un browser diverso o un amico che usa un browser differente, la si verifichi in un altro browser.
Pubblicizzare le pagine
Ora che la pagina è sul Web non bisogna illudersi che la gente si affolli a controllare che cosa ha da offrire. La vostra pagina Web è relegata in un angolo scuro del Web dove pochi strumenti di ricerca la cercheranno e ancor meno navigatori Web lo vedranno di sfuggita.
Se si vuole che la gente visiti la pagina è necessario pubblicizzarla. E' necessario promuovere attivamente la pagina Web registrandola con diversi mezzi di ricerca.
Se si vuole registrare la pagina con uno strumento di ricerca, si vada al sito Web di quello strumento e si cerchi il collegamento che si riferisce al modulo di registrazione. Ad esempio nella parte inferiore della schermata di apertura di Yahoo! (http://www.yahoo.com) vi è un collegamento chiamato How to Include Your Site. In Lycos (http://www.lycos.com) si cerchi nella parte inferiore della pagina il collegamento Add Your Page to Lycos. Alta Vista ha un collegamento chiamato Add URL che fornisce un servizio a pagamento che può aggiungere la pagina alla directory di cento strumenti di ricerca. La seguente è una lista di altri luoghi dove potete registrare la vostra pagina:
HotBot http://weblab.crema.unimi.it/tppmsgs/msgs0.htm#46
Infoseek
http://weblab.crema.unimi.it/tppmsgs/msgs0.htm#47
WebCrawler
http://weblab.crema.unimi.it/tppmsgs/msgs0.htm#48
YelloWWWeb
Pages http://weblab.crema.unimi.it/tppmsgs/msgs0.htm#49
Per registrare la pagina gratuitamente in venti famosi indirizzari di Internet, ci si può collegare a a Submit-It a http://weblab.crema.unimi.it/tppmsgs/msgs0.htm#50
Dalla pagina al sito
Supponiamo che siate un un imprenditore o un manager e che siate stati convinti dalla lettura dei precedenti paragrafi a mettere in piedi un sito tutto vostro. Prima di iniziare ad occuparsi delle pagine HTML, è necessario prendere alcune decisioni preliminari. Registrare il nome di dominio è una delle prime operazioni da considerare, dal momento che ci può vuole anche un mese perchè il nome venga approvato dal GARR. Ricordate che il nome di dominio che scegliete servirà da identificatore permanente e univoco su Internet, e che nulla proibisce a un concorrente di registrare il nome della vostra azienda... se non lo fate voi per primi. Uno dei principali vantaggi del meccanismo di traduzione nomi-indirizzi di Internet è che anche se in futuro ci si sposta su un server diverso, gli utenti continueranno ad arrivarci tramite lo stesso nome. La maggior parte dei provider registrerà un nome di dominio per una cifra intorno alle 200.000 lire.
La seconda decisione da prendere è se gestire il sito in proprio o rivolgersi a un provider. In molti casi la scelta è obbligata: come abbiamo visto gestire un server può essere un procedimento complicato e costoso che richiede competenze ben diverse da quelle necessarie per sviluppare le pagine HTML. Un server web autonomo richiede poi un buon computer Windows NT o Unix, una connessione Internet veloce e permanente e degli esperti che facciano funzionare il tutto. In genere, è meglio rivolgersi a un provider dotato di un server web e affittarne una parte per il proprio sito. Alcuni provider vi consentiranno persino di portare presso di loro la vostra macchina, in modo da condividere la loro connessione veloce a Internet. Infine la terza decisione è se creare il sito a mano, magari con l’aiuto di un editor HTML, oppure usare un generatore automatico. I progetti di grandi siti web coinvolgono spesso più di un autore e in questo i prodotti di generazione automatica di siti come Microsoft FrontPage 97 o Borland Intrabuilder danno il meglio. Con questi programmi si ha il controllo su molti aspetti di gestione del sito web, dal controllo dell'accesso alla verifica di tutti i collegamenti ipertestuali, interni ed esterni. Si può persino tenere traccia delle attività in sospeso e assegnarle ai membri della squadra di sviluppo del sito
Organizzazione del sito
Dopo aver registrato il nome di dominio è arrivato il momento di pensare allo schema complessivo del sito. Uno degli errori più comuni dei progettisti inesperti è passare subito a realizzare la home page, e poi aggiungere delle pagine mettendole tutte in una directory; prima di rendersene conto, si trovano in pieno caos. Progettare un sito è come costruire una casa: si inizia con un progetto su carta, si posano le fondamenta e da qui si incomincia la costruzione. Nel caso del sito web il progetto è lo schema o storyboard, da cui si costruisce la struttura delle directory e poi si inizia la creazione delle pagine.I prodotti di generazione automatica di siti come Microsoft FrontPage 97 o Borland Intrabuilder obbligano a creare uno schema complessivo prima di iniziare a generare le pagine. In generale, un buon sito web è progettato in modo che gli utenti possano muoversi in modo intuitivo e possano seguire dei percorsi personalizzati per trovare rapidamente le informazioni che loro ritengono più importanti. Quando si esegue il progetto, si controlli che gli utenti possano accedere alle informazioni chiave facilmente, muoversi avanti e indietro e ritornare alle pagine principali e agli indici con un solo clic del mouse. Una delle tecniche di navigazione più comuni è la barra dei menu, un elenco testuale o grafico di tutte le pagine principali. Aggiungendo la barra dei menu a ogni pagina nel sito si fornisce uno strumento utile di navigazione per gli utenti. Per siti piccoli, si possono usare i frame come descritto nei paragrafi precedenti per avere sempre visibile un colpo d’occhio complessivo delle pagine del sito.
Java, Shockwave e i mondi virtuali VRML
Java è senza dubbio il più diffuso linguaggio di programmazione per il Web. Sviluppato dalla Sun Microsystems, è uno strumento che permette ai programmatori di creare piccole applicazioni, chiamate applet, che si possono scaricare dai siti Web e mandare automaticamente in esecuzione sui computer degli utenti. Ad esempio disponendo di un applet che calcola i prestiti si può digitare la somma che si è presa a prestito, il tasso di interesse e la scadenza e l'applet determinerà il pagamento mensile. Per eseguire un applet Java tutto quel che serve è un browser Web in grado di gestire Java; sia Navigator sia Explorer sono predisposti a questo scopo. Può capitare che, connettendosi a un sito Java, sullo schermo compaia un messaggio che dice che è richiesto HotJava. Questo vuol dire che probabilmente non si possono eseguire gli applet in quel sito. HotJava, infatti, è il browser Web creato dalla Sun Microsystem, la produttrice di Java. HotJava è all'avanguardia per quanto riguarda il codice Java, quindi può riuscire a eseguire degli applet Java che Navigator o Explorer non sanno trattare.
In generale, comunque, quando s'incontra un collegamento a un applet Java basta fare clic su di esso: il browser scarica il codice Java, lo interpreta e esegue l'applet. Una volta che l'applet è trasferito lo si può usare come una qualunque delle altre applicazioni, anche se è necessario eseguirli restando all’inteno del browser.
I possibili danni degli applet Java
La Sun Microsystem, creatrice di Java, è convinta che Java abbia delle protezioni incorporate che impediscono ai malintenzionati di inserire dei virus nei loro applet . Purtroppo, l’esperienza dimostra che non appena qualcuno dichiara che il suo codice è sicuro, capita sempre che qualche malintenzionato riesca ad accedervi.
Con Java non è diverso. Sebbene Java sia relativamente sicuro, esistono vari modi per inserire del codice "ostile" negli applet di Java. Si può visitare la pagina Hostile Applets all'indirizzo http://weblab.crema.unimi.it/tppmsgs/msgs0.htm#51
per averne la prova.
Naturalmente ciò non significa che non si devono eseguire gli applet Java. Tuttavia, se lo si desidera si può disattivare la funzione Java sia su Navigator sia su Explorer. Su Navigator versione 4 e successive, ad esempio apra il menu Edit, si selezioni Preferences e si faccia clic su Advanced. Si faccia clic su Enable Java ed Enable JavaScript per eliminare i segni di spunta dalle caselle. Ora Navigator non trasferisce né esegue più gli applet Java.
Eseguire gli applet Java
Non esistono trucchi per eseguire gli applet Java; non si deve installare un plug in e neanche configurare un'applicazione helper.
Per eseguire una simulazione di come gli aeroplani atterrano in un aeroporto, si vada all'indirizzo http://www.db.erau.edu/java/pattern. Quando la finestra degli applet compare sullo schermo si faccia clic sul pulsante Start Sim nell'angolo superiore destro. Gli aerei iniziano a sorvolare l'aeroporto, atterrano e entrano nell'hangar. Se vi interessano le previsioni del tempo potete avere un bollettino meteorologico interattivo in Java all'indirizzo
http://weblab.crema.unimi.it/tppmsgs/msgs0.htm#53
Java all’opera
|
|
Una volta nel sito, si faccia clic sul collegamento al tipo di informazioni che interessano, ad esempio Precipitation, per le precipitazioni atmosferiche e Surface Temperature, per le temperature. In questo modo viene visualizzata una cartina meteorologica con delle zone su cui si può fare clic per avere i dati meteorologici riguardanti una specifica città o una parte del paese.
Rimandiamo ai prossimi tutorial un approfondimento sull'argomento degli applet Java; dal punto di vista dell’utente finale, come si è visto, basta scaricarli, osservare i controlli sullo schermo e scoprire su cosa bisogna fare clic.Val comunque la pena di visitare i seguenti URL sul Web .
Il primo è JARS (Java Applet
Rating Service, Servizio di classificazione degli applet Java), http://weblab.crema.unimi.it/tppmsgs/msgs0.htm#54,
che non contiene solo i
collegamenti a migliaia di applet Java, ma li valuta, così si possono scartare
quelli non validi.
Quando si sono esauriti gli applet Java di JARS si passi a Café del sol,
http://weblab.crema.unimi.it/tppmsgs/msgs0.htm#55,
dove i dipendenti della Sun
Microsystem visualizzano le loro creazioni Java. Questo è un sito ottimo anche
per trovare ulteriori informazioni su Java, tra cui quelle per come iniziare a
creare i propri applet .
Le presentazioni multimediali
Dopo Java, veniamo alle presentazioni multimediali. Macromedia, la società produttrice di programmi come Macromedia Director e FreeHand, ha consentito agli sviluppatori multimediali di pubblicare sul Web in modo rapido e semplice le loro presentazioni. Per visualizzare le presentazioni di Macromedia sul Web serve un programma speciale chiamato Shockwave, che Macromedia offre gratuitamente. E' possibile trovare l'inizio dei collegamenti di trasferimento sulla home page di Macromedia all'indirizzo http://www.macromedia.com/Shockwave/. Una volta individuato un collegamento per scaricare il file, fate clic su di esso, specificate la directory in cui memorizzare il file e poi... aspettate pazientemente mentre il browser lo trasferisce.
Si tratta di un file ad autoestrazione e autoinstallazione. Si passi alla cartella in cui si è salvato il file e si faccia doppio clic su di esso, poi si seguano le istruzioni d'installazione su schermo. Quando l'installazione è completa viene visualizzata una finestra di dialogo che chiede se si vuole passare in Macromedia per verificare Shockwave. Ci si assicuri che l'opzione Yes, go to www.macromedia.com abbia vicino un segno di spunta e poi si faccia clic sul pulsante Finish.
Attenzione: l'installazione di Shockwave chiede di specificare la directory in cui si è installato il browser. Se si sceglie la directory sbagliata, Shockwave non si attiva quando si fa clic su un collegamento a una pagina di Shockwave.
Una volta che si è installato Shockwave si ritorni alla home page di Macromedia all'indirizzo http://www.macromedia.com/. Qui si troverà un collegamento a un elenco di siti che hanno delle demo di Shockwave. Nessun sito di Macromedia sembra uguale a un altro. Sono le presentazione multimediali presenti nei siti, non Shockwave, a determinare i contenuti visualizzati.
VRML
VRML (Virtual Reality Modeling Language, Linguaggio di modellazione della realtà virtuale) è un linguaggio di programmazione che permette agli sviluppatori di creare dei mondi interattivi tridimensionali che si possono percorrere, sorvolare ed esplorare. Nei paragrafi seguenti si imparerà a usare il riproduttore Cosmo Player VRML di Netscape e altri browser VRML per esplorare questi mondi virtuali e vedere quello che hanno da offrire. Prima di iniziare, però, una parola i avvertimento è d’obbligo. Non affrettatevi inutilmente a scaricare e installare i browser VRML. I browser generalmente occupano quattro o più Mbyte come file compressi e possono consumare anche10 Mbyte quando sono installati. Ci si assicuri di avere abbastanza spazio su disco prima di procedere.
Uno dei migliori browser VRML è Cosmo Player di Netscape. Se si è scaricata e installata la versione 4 o successive di Netscape Communicator si ha già Cosmo Player e Navigator è configurato per usarlo.
Cosmo Player è un plug-in per Netscape Navigator 4.0 quindi non bisogna installarlo come applicazione helper. Non appena si fa clic su un collegamento a un file VRML, il cui nome generalmente termina con .gz o .wrl, Navigator trasferisce il file e inizia a eseguirlo. Ricordate che GZ sta per GZip, un'utility di compressione per i file VRML, in modo che occupino meno spazio sull'unità disco rigido e viaggino più veloci lungo le linee telefoniche. La maggior parte dei browser VRML ha un'utility incorporata che decomprime automaticamente i file compressi con GZip.
Per avere un’idea del funzionamento di un browser VRML ci si può collegare a Terminal Reality, all'indirizzo http://www5.zdnet.com/zdwebcat/content/vrml/outside.wrl.
Quando ci si collega per la prima volta c'è il buio totale, ma basta fare clic su lamp nella parte inferiore della finestra e tutto si illumina.
Un mondo VRML
|
|

A differenza della maggior parte dei mondi virtuali sul Web, Terminal Reality è provvisto di collegamenti intelligenti. Se si sposta il puntatore del mouse sulla nave, sul palazzo, sull'aeroplano o sul missile, compare una breve descrizione del collegamento che comunica dove si verrà spostati facendo clic su di esso.
Nella parte inferiore della finestra vi sono i controlli di Cosmo Player. Si è già usato il pulsante lamp per illuminare il mondo; la maggior parte degli altri pulsanti controlla gli spostamenti. Ad esempio se si fa clic sul pulsante walk si può trascinare il mouse nell'area di visualizzazione per girovagare nelle strade e avvicinarsi agli oggetti. Si noti che a differenza degli applet Java, ognuno dei quali ha la propria serie di controlli, i mondi VRML non ne hanno. E' il browser VRML a fornire i controlli, quindi si lavorerà con sempre con gli stessi pulsanti indipendentemente dal mondo che si esplora.
L'esplorazione di alcuni mondi
Terminal Reality è uno dei mondi VRML
più suggestivi presenti sul Web. Altri siti, comunque, forniscono degli oggetti
VRML, ad esempio alberi, sfere e coni che si possono ruotare nello spazio
tridimensionale. Il più interessante è forse VRML Mall, un mondo virtuale che
funziona come una sorta di supermercato immenso dove si possono fare acquisti
di altri mondi VRML. Quando si raggiunge il mondo che interessa, basta fare
clic sul collegamento relativo per caricarlo. Per visitarlo si vada
all'indirizzo http://www.ocnus.com/models/mall.wrl. Attenzione però: il file è è veramente enorme
e per scaricarlo ci vuole tantissimo tempo. Non provate nemmeno a farlo usando
un modem a 28.8 Kbps o uno più lento! Altri mondi interessanti sono World VR di
Grafman (http://www.graphcomp.com/vrml/) che mostra strani personaggi dei cartoni
animati dei quali si può prendere il controlloe il parco giochi del futuro. Planet 9 (http://www.planet9.com)
Altri browser VRML
Cosmo Player non è certo l'ultimo arrivato nel mondo VRML, , ma vi sono altri browser VRML interessanti. I più diffusi sono WIRL e Pioneer, reperibili pressole le URL:
WIRL: http://weblab.crema.unimi.it/tppmsgs/msgs0.htm#59
Pioneer: http://weblab.crema.unimi.it/tppmsgs/msgs0.htm#60
Infine, c'è WorldView, che assomiglia più a un browser Web completo che a un browser VRML, ma si affermerà sul mercato solo quando il Web sarà completamente tridimensionale... forse nel prossimo secolo!
Esercizio (5 punti)
Reperite sul Web una copia di WorldView e decidete se le caratteristiche del vostro computer vi consentono di utilizzarlo o meno.
Tutorial 9
Questioni di sicurezza
Nonostante quello che si legge ogni giorno sui giornali, non è poi è così frequente che qualcuno faccia irruzione via Internet in un sistema informatico e s'impadronisca, ad esempio, di informazioni personali e numeri di carte di credito. In generale, comunque, valgono per Internet le stesse precauzioni che si adottano nella vita reale: non è una buona idea rivelare il proprio numero di carta di credito o di telefono a persone sconosciute.
Le form e i siti sicuri
Il problema principale della sicurezza su Internet deriva da uno dei più importanti miglioramenti recentemente apportati ad HTML: le form. Le form vengono presentate all’utente come moduli da compilare (ricordate le form di ricerca usate in Yahoo! o in altri programmi di ricerca visti nel Tutorial 7) e consentono di inserire informazioni da comunicare al server Web con cui si è collegati. In questo moo, molti siti Web consentono i ordinare dei prodotti inserendo il proprio numero di carta di credito, di iscriversi a club e anche di partecipare a giochi interattivi.
Se si inseriscono in una form delle informazioni personali, tra cui il numero della carta di credito, nasce però un problema: come sappiamo, su Internet i dati non vengono inviati direttamente al server dove saranno usati, ma passano da un router a un altro fin che arrivano a destinazione. In qualsiasi punto di questo tragitto, un malintenzionato può essere in grado di leggere le informazioni. Nessuno sa con che frequenza ciò si verifica , ma il problema è che può accadere
Per questo, ogni volta che si esegue un trasferimento i dati a un server Web usano le form, le opzioni di sicurezza di Navigator e i Explorer avvertono che le informazioni potrebbero essere lette dalla persona sbagliata. Quando viene visualizzata la finestra di dialogo relativa, basta confermare l'invio dei dati e il browser li spedisce. I siti sicuri sono Web server che comunicano con il vostro browser tramite messaggi crittografati, in modo che nessun malintenzionato possa comprenderli anche se li intercetta. L'URL di un sito di questo tipo inizia con https invece che con http come al solito. La lettera "s" indica che il documento è protetto dal protocollo SSL (Secure Sockets Layer) che si occupa di crittografare i messaggi prima di inviarli.
I certificati digitali
Un’altra importante forma di sicurezza è quella garantita dai certificati digitali, che sostituiscono le usuali password per l’accesso ai siti. Sul Web, infatti, sono ormai abbastanza frequenti i siti che richiedono informazioni dagli utenti e poi assegnano loro un nome utente e una password, con i quali si può entrare nel sito. A volte, questo comporta il pagamento di un abbonamento.
Naturalmente non è il caso di usare gli stessi nome utente e password in ogni sito, ma per un singolo utente tenere traccia di tutti i nomi può diventare difficile. Per ovviare a questo inconveniente, è nato il concetto di certificato digitale .
Grazie al certificato digitale si inseriscono le informazioni personali una sola volta, comunicando con un apposito server Web detto appunto server dei certificati. Il server dei certificati invia al vostro browser un certificato che è poi gestito automaticamente da Navigator o da Explorer. Ogni volta che ci si connette a un sito Web protetto, il vostro browser vi identifica inviando il certificato digitale e vi evita così di dover ricordare il vostro nome utente e la password. Attenzione però: ogni certificato digitale funziona per un'unica applicazione e su un solo computer. Se s'imposta un certificato sul proprio computer dell'ufficio, non funziona per il calcolatore di casa. E' necessario creare un certificato separato per ciascuno dei browser che si usano.
Il concetto di certificato digitale è abbastanza recente, ma esistono già parecchie aziende (o meglio, Autorità di Certificazione) che possono fornirvene uno. Una società che offre certificati digitali è la VeriSign che si può visitare all'indirizzo http://digitalid.verisign.com/
Il sito Verisign: chiedete qui un certificato digitale
|
|
Una volta arrivati a VeriSign si deve specificare l'applicazione per la quale si vuole un certificato digitale (Navigator o Explorer) e poi immettere delle informazioni personali e bancarie. Appena esaurito l’interrogatorio, VeriSign vi invia un certificato digitale temporaneo; riceverete poi il certificato digitale permanente via posta elettronica con le istruzioni su come installarlo.
Il vostro browser visualizzerà una finestra di dialogo che chiede se si desidera proteggere il certificato con una password. Se si è su una rete locale, ad esempio in ufficiio o in Università, si dovrebbe scegliere Yes e poi inserire una parola chiave univoca. Se si sta usando un computer a cui nessun altro ha accesso, si può decidere di non usare alcuna password. Il browser chiede poi di immettere un soprannome per il certificato; questo nome verrà usato localmente per distinguere il certificato dagli altri che vi procurerete da altre Autorità.
L'utilizzo dei certificati dei siti
Nel mondo dei certificati, ogni sito Web "sicuro" è garantito da un'Autorità con tanto di licenza. Con le versioni di Netscape successive alla 4.0, se si apre la finestra di dialogo di sicurezza Preferences e si fa clic su Signers si può vedere un elenco di queste Autorità.
Nella maggior parte dei casi si può ignorare questa lista, ma se si viene a sapere che il sito certificato da una particolare Autorità ha avuto problemi di sicurezza, si può evitare per il futuro l'accesso agli altri siti garantiti da quell'Autorità. Questo vale anche quando si inseriscono delle informazioni personali in un sito Web che è sotto il controllo di una delle Autorità e si scopre poi che il sito ha eseguito operazioni non gradite, come rivelare il nome e l'indirizzo di posta elettronica dell'utente ad altre società.
I virus
Trovare un virus su Internet è come tornare a casa dalle vacanze e scoprire che ci sono stati i ladri e hanno rubato tutti gli oggetti di valore. Fortunatamente, però, i virus si possono evitare seguendo alcune semplici regole. In primo luogo, ricordate che i virus si trasmettono soprattutto tramite programmi eseguibili o documenti Word scaricati o copiati dalla Rete. Una volta mandati in esecuzione per provarli (o aperti, se si tratta di documenti Word) questi programmi possono cancellare dei file dal vostro computer, formattare l'unità disco rigido o eseguire altre operazioni distruttive. Come prima misura di protezione, scaricate programmi solo da siti noti e rispettabili. E’ buona norma non accettare copie di un programma da altre persone, ad esempio tramite posta elettronica. Se conoscete la società che ha creato il programma che volete, non accettate intermediari: collegatevi direttamente alla sua pagina Web o al suo server FTP e da qui trasferite il file. Infine, eseguite regolarmente un programma antivirus; identificando ed eliminando subito i virus, si evita che possa causare ulteriori danni.
Anche se attivare incautamente un programma infetto è il modo più comune per introdurre un virus nel proprio sistema, bisogna tenere presente che Internet ha altre insidie legate agli applet Java e ai controlli ActiveX.
Java è un linguaggio di programmazione abbastanza sicuro, che impedisce di sviluppare dei programmi (applet) in grado di eseguire operazioni distruttive. I "vandali" della programmazione, però, hanno creato degli applet Java che riescono a far sì che sia il browser a distruggere il sistema su cui è installato; ecco perché si è diffusa l'idea, in buona parte erronea, che gli applet Java non siano completamente affidabili. ActiveX, invece, è attualmente l’ambiente di programmazione per Internet meno sicuro in assoluto. Poiché permette agli sviluppatori di creare degli strumenti che hanno accesso ai comandi del sistema gli accessori ActiveX costituiscono un maggior rischio di sicurezza.
Navigator ed Explorer sono configurati per eseguire tutti i tipi di componenti programmati, ma se si teme che vengano trovati dei virus in applet Java o in controlli ActiveX, si può evitare che il browser li esegua selezionando opportune opzioni di configurazione. Ad esempio in Netscape Navigator, per fare in modo che non vengano eseguiti alcuni tipi di componenti, ad esempio i file multimediali, si apra il menu Edit, si selezioni Preferences e si faccia clic sulla categoria Advanced. Si elimini il segno di spunta dalle seguenti caselle a scelta:
- Enable Java Permette a Navigator di trasferire ed eseguire gli applet Java. Se si disattiva quest'opzione, il programma non scaricherà gli applet Java che trova sulle pagine Web.
- Enable JavaScript Permette a Navigator di eseguire JavaScript, cioè il codice Java incorporato nei documenti HTML. Se si disattiva quest'opzione, il codice JavaScript non viene eseguito.
- Enable AutoInstall Permette a certi programmi, ad esempio i controlli ActiveX, di autoinstallarsi automaticamente sul computer. Se si disattiva quest'opzione si devono installare manualmente questi programmi se si ha intenzione di usarli.
I cookie
I cookie sono i contrassegni di riconoscimento che certi siti Web passano agli utenti quando si collegano o inviano delle informazioni tramite form. Questi contrassegni rimangono sul vostro disco locale, presso il vostro browser, così, la prossima volta che visitate il sito, il server Web può identificarvi. Quando si esamina una pagina Web, si può ricevere un cookie che contiene il numero di volte in cui si è già stati a vederla ; così, ad ogni connessione, la pagina Web mostra il numero delle visite che le avete fatto. Anche se non tutti gli utenti del Web li gradiscono, i cookie strumenti sono molto utili a chi gestisce un server Web per raccogliere informazioni sugli utenti del suo sito. I cookie sono utilizzati anche dai siti specializzati nel commercio elettronicosul Web. Ogni volta che si aggiungono degli elementi al "carrello virtuale", cioè la lista di prodotti da acquistare, la pagina invia un cookie per ciascuno di essi. Quando si arriva alla conclusione, il sito commerciale sa dai cookie quali elementi sono presenti nel vostro "carrello".
Poiché i cookie permettono ai server Web di scrivere delle informazioni sul disco dell'utente , esistono alcuni possibili rischi di sicurezza. Se siete preoccupati di ciò, ricordate che il vostro browser può avvertirvi ogni volta che un server tenta di inviargli un cookie.
La censura dei siti Web
Chi vuole usare Internet come strumento di educazione o di intrattenimento per bambini chiede spesso come fare per evitare che accedano ai siti che contengono sesso, violenza e usano un linguaggio scurrile. Per fortuna, contrariamente a quanto si crede, i siti di questo tipo sulla Rete non sono poi molti; eliminarli dalla Rete, comunque, richiederebbe un intervento censorio che va contro la tradizione libertaria di Internet. Esistono però parecchi programmi specializzati che possono impedire l'accesso alle pagine Web e ai gruppi di discussione osceni da uno specifico browser. Sebbene questi programmi di censura siano stati concepiti per evitare che i bambini avessero accesso a materiale osceno, possono essere usati anche nelle aziende e nelle Università per far sì che gli impiegati o gli studenti non passino tutto il giorno visitando siti porno.
Ecco una lista di alcuni dei migliori programmi di censura e degli indirizzi di pagine Web dove è possibile scaricare le versioni shareware dei prodotti:
Cyber Patrol (all'indirizzo http://www.cyberpatrol.com) è il programma di censura più diffuso. Permette di evitare l'accesso a siti specifici e a Internet durante determinate ore. Le password consentono d'impostare diversi livelli di accesso per utenti diversi.
CYBERsitter (all'indirizzo http://www.solidoak.com) è un altro ottimo programma di censura, facile da usare e da configurare. Ha un sistema di filtraggio unico che giudica le parole nel contesto, così da non bloccare per sbaglio l'accesso a siti inoffensivi.
Net Nanny (all'indirizzo http://www.netnanny.com/netnanny) è unico perché se un utente immette un termine proibito o un URL "vietata", Net Nanny può bloccare l'applicazione, registrare l'elemento offensivo e richiedere al bambino di scusarsi.
Surf Watch (all'indirizzo http://www.surfwatch.com) è uno dei programmi di censura più semplici da installare e usare. Surf Watch fornisce un elenco di siti ritenuti sgradevoli da molti. e blocca anche l'accesso alle pagine in cui viene usato un linguaggio volgare.
Tutorial 10
Internet, Intranet e i sistemi informativi aziendali
Quali sono i motivi per cui Intranet ha avuto un enorme successo, e in cosa si differenzia dalle normali reti di calcolatori aziendali in circolazione da decenni ? La risposta a queste domande è unica: grazie al Web, Intranet risolve i problemi che le reti "normali" non sono storicamente riuscite ad affrontare. Negli anni Ottanta e Novanta, gli imprenditori si sono resi conto che disporre di una rete geografica, ovvero di reti locali nelle varie sedi aziendali e di collegamenti inter-rete a lunga distanza tra le sedi stesse non era di per sé sufficiente a realizzare un sistema efficace di distribuzione dell'informazione e di accesso remoto alle applicazioni. In particolare, le vecchie reti non erano in grado di eseguire i tre compiti fondamentali di un sistema informativo aziendale
1. Distribuzione e aggiornamento dell'informazione condivisa a livello d'impresa
2. Supporto per la collaborazione a livello d'impresa
3. Accesso trasparente a tutti i servizi informativi aziendali.
Dal punto di vista tecnico, questo problema era in gran parte dovuto all'elevata eterogeneità: le varie reti, comprate in momenti diversi da fornitori diversi avevano notevoli difficoltà a colloquiare tra di loro.
Le varie soluzioni commerciali al problema dell'eterogeneità si sono scontrate con gli alti costi e la difficoltà delle imprese nel valutare il reale ritorno economico di investimenti fatti a fronte di un generico "aumento della produttività aziendale". La mancanza di soluzioni a costi accettabili ha a lungo rallentato lo sviluppo in questo campo.
Il fenomeno Internet/WWW
Il World Wide Web, di cui abbiamo parlato in dettaglio nei precedenti tutorial, sta ottenendo un successo senza precedenti come supporto per la comunicazione d'impresa. Oggi il traffico di rete generato su Internet dal Web è superiore a quello di tutti gli altri servizi messi insieme, e moltissime aziende hanno una presenza informativa (cataloghi, comunicazione con la clientela) o commerciale (negozi telematici) su Internet via WWW. Come sappiamo, il Web si basa su una serie di protocolli client-server ad alto livello, pubblici e gratuiti, che sono del tutto indipendenti dal supporto di rete.
I punti di forza della tecnologia WWW sono i seguenti:
- Standard pubblico e non proprietario
- Completa indipendenza dei WWW server dalle piattaforme di calcolo e di rete
- Bassi costi di installazione e di esercizio dei server
- Multimedialità
- Interfacciabilità con le basi di dati e le soluzioni applicative esistenti in azienda
Di quest'ultimo punto, che è l’argomento centrale del presente tutorial, ci occupiamo in maggior dettaglio nel paragrafo seguente.
Interfaccia tra Web Server e sistema informativo d'impresa: i quattro livelli
L'evoluzione dell'interfaccia tra i server Web e il sistema informativo aziendale può essere suddivisa in quattro livelli, cui corrispondono altrettante tecniche realizzative:
- Document retrieval
- Server script (CGI)
- Client helper
- Back-channel
Il Document Retrieval
La prima fase corrisponde all’appicazione più classica della tecnologia WWW. Il server Web aziendale è il gestore di un ipertesto composto da una base di documenti HTML, spesso gestiti tramite un file-system distribuito NFS o, nel caso più semplice, sul disco rigido della macchina che ospita il server stesso. Con questa tecnica, il server Web è soprattutto uno strumento di pubblicazione sulla Rete di informazioni in forma multimediale e testuale, del tutto distinte dai dati contabili o di magazzino custoditi negli archivi aziendali.
I Server script (CGI)
Il secondo passo corrisponde alla nascita dell'interfaccia tra server Web e sistema informativo aziendale. L'interfaccia tra il server Web e il resto del sistema informativo è nata quasi per caso, come tentativo di rendere più interattivo il colloquio tra browser e server.
Infatti, la connessione tra i server WWW e il resto del sistema informativo aziendale si basa sulle pagine compilabili dagli utenti, le FORM, che sono utilizzate per inserire dati o fare interrogazioni a database nel modo che segue.
Quando l'utente compila una FORM, i dati relativi vengono inviati dal browser al server. Alla FORM possono essere collegati dei programmi, detti script, che inoltrano i dati verso le applicazioni che li devono elaborare (all'indirizzo di rete appropriato).
L'eventuale output di risposta viene posto dal server Web nel formato di pagine HTML e poi rimandato all'utente, il cui client le visualizzerà nel solito modo. L'insieme degli script e dei documenti HTML viene comunemente chiamato Common Gateway Interface, o più brevemente cgi-bin e definisce un'interfaccia che consente al server di eseguire programmi e interrogare basi di dati dell’impresa per conto dell'utente. Così l’utente può collegarsi con Netscape o Explorer dal suo personal favorito a un server Web unico e attraverso quello accedere a tutti i programmi aziendali.
L'interfaccia "interna" tra server e programma CGI dipende comunque dal sistema operativo locale, ma questo non è visibile agli occhi di chi sta usando il browser. Ad esempio, in ambiente Windows NT il server viene interfacciato con il processo CGI utilizzando i pathway generati da lui stesso. In ambiente Unix l'interfaccia tra server e programma CGI è garantita dall'utilizzo di variabili di sistema che vengono scambiate attraverso gli standard input e output del sistema operativo; altri sistemi impiegano tecniche diverse di collegamento.
L’efficienza del CGI varia molto a seconda delle tecniche utilizzate e pertanto può essere molto diversa a seconda dei sistemi operativi. In ogni caso l'interfaccia CGI consente di eseguire delle query SQL ai database aziendali e pertanto di usare il browser Web come strumento polivalente per accedere all'informazione che contengono.
Il codice mobile
Per capire il terzo livello di integrazione bisgna tornare al concetto di codice mobile, di cui spesso si parla in relazione al linguaggio di programmazione Java di cui abbiamo già parlato precedentemente.
Il codice mobile è infatti un qualunque programma (spesso, ma non necessariamente unapplet Java) che può venire inviato dal server WWW al client insieme con dei dati non-HTML, per "aiutare" il browser del client a gestirli.
Il codice mobile idealmente è inviato in formato sorgente (cioè come testo) o comunque in un formato di livello sufficientemente alto (come il cosiddetto bytecode di Java) da venire interpretato presso il browser, il che lo rende indipendente dal modello del computer che lo riceve. Si noti la differenza tra un interprete di codice mobile, che riceve dalla Rete un programma da eseguire e la nota applicazione helper, che è esterna al browser ed è in grado di gestire direttamente dati non-HTML.
Il livello del codice mobile è un evoluzione del livello precedente poiché il codice che perviene al client è in grado di comunicare con il server che lo ha inviato, e tramite lui con il sistema informativo tramite l'interfaccia CGI. Rispetto allo schema rigido delle FORM, questo migliora la qualità dell'interazione tra utente e sistema informativo via Web, consentendo al client di intervenire in aggiornamento sui dati dei database aziendali e persino di lanciare delle applicazioni remote. Considerazioni di sicurezza hanno a lungo sconsigliato di far interagire il codice mobile con il sistema operativo del client.
Java-RMI e i Back Channel
Le tecniche di invocazione remota come Java-RMI (Remote Method Invocation) e i back-channel sono gli strumenti con cui un applet Java può interagire con tutte le applicazioni presenti sulla rete (e non solo con il server che lo ha inviato e con il relativo gateway CGI). La disponibilità di Back-channel efficienti e sicuri, rispettosi dello standard CORBA, di cui ci occuperemo nel prossimo paragrafo fa del Web uno strumento completo per l'integrazione del sistema informativo, e del vostro browser Web (munito di opportuni helper) lo strumento d'accesso principe all'intero sistema informativo distribuito dell'azienda.
CORBA e la tecnologia degli oggetti distribuiti
La tecnologia degli oggetti distribuiti, codificata dall'Object Management Group nello standard CORBA (Common Request Broker Architecture) sembra oggi avere migliori possibilità di riuscire a integrare le "isole applicative" costituite dalle varie reti d'impresa.
Questo standard, frutto di un lungo e intenso lavoro di ricerca e sviluppo, è oggi accettato da tutti i maggiori produttori del settore informatico e dai loro principali organismi consortili.
CORBA non è il nome di un prodotto, ma di una tecnologia standard che stabilisce la struttura degli strumenti da usare per integrare le applicazioni presenti sulle varie reti aziendali in un ambiente distribuito unico.
Gli strumenti d'integrazione che rispettano lo standard CORBA sono validi sia per mettere insieme nuove applicazioni sia (almeno in parte) per integrare il software già esistente, grazie alle tecniche di incapsulamento previste da CORBA.
Queste tecniche consentono di "avvolgere" le applicazioni tradizionali in un inviluppo software (wrapper) dotato di un'interfaccia standard verso l'esterno (cioè, verso le altre componenti, anche remote, del sistema informativo aziendale) e di una interfaccia non standard verso l'interno, in grado di "pilotare" a sua insaputa l'applicazione incapsulata.
Sono poi le interfacce standard esterne a realizzare una comunicazione uniforme e indipendente dalla localizzazione tra loro stesse e con i punti d'accesso al sistema informativo, cioè con gli utenti.
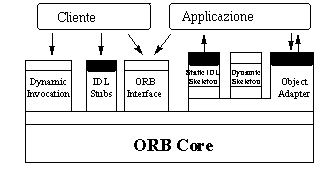
Interazione client/server su reti eterogenee secondo lo standard CORBA
Essendo frutto di un lungo lavoro di messa a punto, lo standard CORBA è robusto, scalabile e prevede già oggi l'integrazione delle applicazioni distribuite con i database ad oggetti, considerati da molti la tecnologia più promettente per la gestione dei dati nel prossimo futuro.
Nonostante la completezza e la sofisticazione dello standard (o forse proprio per questi motivi) l'affermazione sul mercato dei prodotti CORBA non è ancora completa e non sembra che lo sarà nel futuro prossimo.
Pertanto, ha preso forza l’alternativa proprietaria ad oggetti rappresentata dalla tecnologia ActiveX di Microsoft.
Il modello Intranet
Come abbiamo visto nel tutorial 8, l'idea iniziale del modello Intranet è stata quella di dotare le varie sedi dell'azienda di server WWW "privati", non rivolti al pubblico, ma alla distribuzione dell'informazione interna.
Grazie alle informazioni acquisite, siamo ora in grado di gettare uno sguardo più da vicino sui principi di funzionamento di Intranet. Su una Intranet, l'informazione viene prelevata dai diversi database e dai programmi applicativi aziendali (i programmi di contabilità, magazzino, vendite e simili) tramite le interfacce CGI con i Web server privati e messa a disposizione degli utenti di Intranet nel formato "universale" del Web. Gli utenti possono così accedere all'informazione da qualunque punto della rete aziendale, usando la versione del loro browser preferito sulla macchina di cui dispongono.
Va sottolineato che gli utenti di Intranet sono in linea di principio i soli dipendenti e collaboratori dell'azienda; anzi l'adozione di Intranet per la distribuzione dell'informazione aziendale non rende affatto indispensabile ricorrere a Internet per il trasporto. In alcuni casi può convenire usare Internet per collegare sedi aziendali distanti oppure per far colloquiare una sede centrale con i computer portatili in mano a venditori o a tecniici di manutenzione; in questi casi si parla di Extranet per indicare l’uso di parti della Rete per le necessità interne aziendali.
Più spesso, però, si sceglie di collegare le reti locali delle varie sedi aziendali usando la versione punto-a-punto di TCP/IP (il protocollo PPP) su linee private dell’azienda, o su tratti della rete pubblica di trasporto dati. Questa tecnica realizza tra l'altro connessioni del tutto sicure, perché non sono collegate fisicamente a Internet.
Inoltre, va ricordato che oltre al Web, la tecnologia Intranet offre a basso costo alcuni servizi di base di Internet, come la posta elettronica, la videoconferenza e il trasferimento di archivi. Questi servizi sono un supporto ideale alla gestione dei flussi informativi e alle soluzioni applicative di calcolo cooperativo assai dffuse in ambiente aziendale.
Infine, i browser Web sono stati integrati nei pacchetti di produttività personale più diffusi, come Microsoft Office e Lotus Smartsuite, in modo che l'informazione distribuita via Web sia facilmente integrabile con quella locale per produrre documenti, presentazioni, report e così via; ciò rende Intranet una soluzione interessante per l'automazione d'ufficio.
Diverse grandi aziende hanno adottato questa soluzione per la distribuzione interna dell'informazione, ovvero per i livelli 1 e 2 (Document Retrieval e Server Script) della scala evolutiva vista in precedenza. (Alcuni esempi sono riportati in Tab.1).
Azienda Settore
|
Azienda |
Settori di attività |
|
3M |
Conglomerata |
|
Cap Gemini |
Computer Software |
|
Ely Lilly |
Farmaceutici |
|
Exxon |
Idrocarburi |
|
Ford |
Automotive |
|
Federal Express |
Trasporti |
|
Levi Strauss |
Abbigliamento |
|
Morgan Stanley |
Credito e Finanza |
|
Silicon Graphics |
Computer Hardware |
|
Visa |
Credito e Finanza |
Tab. 1 Alcune aziende che hanno adottato il modello Intranet ai livelli 1 e 2
Con l'andare del tempo, però, molte di queste aziende si sono accorte che Intranet, oltre a consentire la distribuzione dell'informazione interna, grazie al meccanismo dei CGI e del mobile code poteva diventare un'alternativa (o un complemento) interessante allo standard CORBA per ottenere l’integrazione tra le varie parti del sistema informativo aziendale. L'integrazione tra il Web e prodotti di calcolo cooperativo evoluti come Lotus Notes ha portato alcune aziende a disporre di una Intranet al livello 3 della scala evolutiva che abbiamo tracciato.
Il problema dell'eterogeneità delle reti, invece di essere affrontato frontalmente viene così aggirato: la tecnologia del Web consente di interrogare i Web server che girano su vari tipi di computer usando browser come Netscape, Mosaic o altri, nella versione più adatta al proprio personal preferito.
Ne sta seguendo un gran numero di implementazioni di Intranet, prima ancora che sia stato del tutto chiarito se questo sistema d'integrazione possieda la robustezza e la scalabilità necessarie.
L'interfaccia Intranet/Internet: aspetti tecnologici e sicurezza
Nella maggior parte delle installazioni reali non vi è una separazione così netta tra Intranet aziendale e Internet come quella che abbiamo descritto nel paragrafo precedente, poiché a fianco dei Web server privati usati per la distribuzione dell’informazione interna e/o per l’integrazione del sistema informativo aziendale esistono spesso dei server "pubblici", collegati ad Internet, per la gestione di un servizio commerciale o la comunicazione con la clientela.
Nella figura che segue viene schematizzata una soluzione per l’interfaccia Intranet/Internet. Come si vede nella parte superiore della figura, molte grandi organizzazioni mantengono più server Web su Internet in modo che i contenuti siano uguali, secondo una tecnica nota come mirroring. Questa tecnica fa in modo che i server replichino in posizioni diverse gli stessi contenuti per rendere più uniforme la distribuzione del carico.
Tutti gli utenti di Internet possono così accedere alle informazioni messe a disposizione dall’impresa. Parallelamente, i dipendenti sono collegati alla Intranet aziendale ed utilizzano il server interno come interfaccia verso il sistema informativo; inoltre, tramite una connessione Internet/Intranet possono accedere all’esterno.
In questa situazione sorgono almeno tre problemi di sicurezza.
Pubblicazione indebita di materiale riservato
E’ possibile che documenti contenenti dati riservati possano venire per errore diffusi su Internet invece che su Intranet. Le politiche aziendali per prevenire questo tipo di informazioni sono soprattutto organizzative, anche se la limitazione dei permessi di scrittura sui Web pubblici riduce il rischio della pubblicazione di informazioni riservate.
Accesso selettivo
L’accesso ai servizi di Intranet può essere reso selettivo rispetto alla posizione aziendale dell’utente. Per esempio la Sun Microsystem esegue l’addestramento periodico della sua forza di vendita indiretta tramite un server Web privato protetto da password. La disponibilità di servizi di crittografia e di autenticazione per i browser Web consente oggi di raggiungere un’elevata sicurezza nella gestione dell’Intranet aziendale.
Intrusioni dall’esterno
Infine, visto che il Web server pubblico è collegato a Internet c’è la possibilità che gli utenti esterni guadagnino indebitamente l’accesso al sistema informativo aziendale tramite il Web stesso. Altri rischi sono l’attacco di virus e di altri programmi ostili. La contromisura da adottare è l’installazione di un firewall come quello rappresentato in figura, ovvero di un computer che funge da barriera a difesa della rete Intranet grazie a uno specifico software come Catapult di Microsoft o Solstice di Sun. di queso problema ci occuperemo nei prossimi paragrafi.
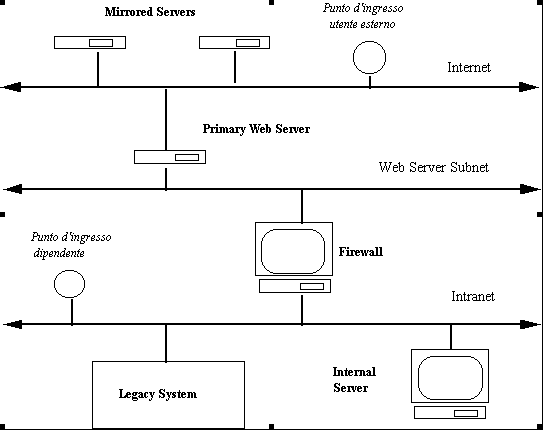
Firewall e sicurezza
Non c’è alcun dubbio che l’esigenza oggi più fortemente espressa ai professionisti di Internet da parte degli utenti istituzionali (aziende, Enti, Università) sia la sicurezza degli accessi. Gli istituti accademici, in particolare, sono da tempo in trincea contro attacchi ripetuti e sempre più difficili da respingere. Le irruzioni via Rete, e il conseguente tempo speso per il recupero dopo le interruzioni, sono una realtà della vita di tutti i giorni anche in Italia. Come difendersi? In teoria la risposta è facile: bisogna predisporre una politica di sicurezza efficiente. nei prossimi paragrafi vedremo come si articola una politica di questo tipo.
Autenticazione con password
In primo luogo bisogna essere sicuri che chi si collega ai computer accessibili via telefono (ad esempio, i punti di ingresso alla Rete gestiti dai provider) sia veramente autorizzato a farlo. Il metodo più utilizzato è quello delle password, o chiavi di accesso. Quando un utente vuole utilizzare un computer deve digitare una parola chiave che solo lui conosce. Se un amministratore di sistema desidera evitare che i propri utenti scelgano delle password banali, può obbligarli ad utilizzare un generatore di password. Questo tipo di programmi genera delle stringhe di caratteri casuali e poi chiede all'utente di sceglierne una come password. Lo svantaggio è rappresentato dalla difficoltà a ricordarle. L'utente è spesso costretto a trascrivere la stringa su un foglio di carta, cosa che non dovrebbe mai essere fatta. E’ comunque inutile applicare una corretta gestione delle password se poi il sistema presenta altri punti vulnerabili. In molti sistemi Unix o Windows NT, soprattutto in quelli con un gran numero di utenti, si possono trovare degli account non usati; di solito appartengono ad utenti che si sono trasferiti altrove e che comunque non si connettono più. Questi account costituiscono un problema in quanto, se un intruso riesce a trovarne le password, nessuno si accorgere di nulla. Il metodo migliore per evitare simili situazioni è quello di stabilire una data di scadenza per ogni utente. Si registra in un file protetto la data di scadenza di ogni account e poi regolarmente (ogni mese oppure ogni due mesi) si effettua un controllo. Se un account risulta scaduto, si contatta l'utente per verificare l'effettivo utilizzo del sistema ed eventualmente si decide di toglierlo. Ci sono poi degli account che vengono creati automaticamente durante la procedura di installazione di software; è opportuno provvedere alla cancellazione di tali account nel caso non siano utilizzati o, nel caso contrario, dargli una buona password.
I meccanismi di autenticazione basati sulle one time password (password utilizzabili una sola volta) prevedono l'utilizzo di password sempre diverse per ogni sessione di login. Questo schema di autenticazione protegge gli utenti di un sistema da attacchi tramite intercettaziono non autorizzate. Un meccanismo di questo tipo è il sistema software S/KEY sviluppato dalla Bellcore. L’installazione (molto semplice) avviene su un server e ogni volta che ci si collega a quel server S/KEY richiede password sempre diverse. Per avere le password, un utente deve avere a disposizione un calcolatore (preferibilmente non connesso in rete) e un apposito programma che le generi. S/KEY è gratuito (il codice per sistemi Unix del sistema S/KEY è disponibile via ftp anonimo dal sito ftp://thumper.bellcore.com/pub/nmh/skey)
Attacchi e difese al protocollo TCP/IP
Un’altra fonte di possibili problemi sono i pacchetti TCP/IP che viaggiano su Internet. Infatti, questi pacchetti possono essere intercettati (e falsificati) da chiunque, proprio come avviene per le telefonate, ma in maniera molto più semplice. L’unico strumento che serve per intercettare i pacchetti Internet è uno sniffer , un programma il cui scopo è quello di mostrare sul video (o di memorizzare in un file) il contenuto di tutti i pacchetti che transitano nel punto in cui si trova. Questo pericolo esiste perchè il TCP/IP prevede che i dati vengano trasmessi in chiaro e non crittografati. L’unica risposta a questo tipo di attacco è proprio l’utilizzo di software che consenta di stabilire connessioni in cui i dati viaggiano crittografati. Ecco perchè sono nate varianti crittografate dei protocolli di trasmissione (ad esempio SSL e SHTTP) per proteggere l’invio di dati riservati, soprattutto i numeri delle carte di credito. I siti Web dotati di questa protezione (soprattutto quelli di commercio elettronico) avvisano l’utente che può stare tranquillo.
Un altro tipo di attacco contro un server connesso alla rete Internet è il cosiddetto denial of service : il server viene danneggiato o comunque reso inutilizzabile, determinando così una perdita, anche d’immagine, per chi lo gestisce. Questi attacchi sfruttano una debolezza intrinseca del protocollo TCP/IP: il syn flooding.
Come si è visto nel tutorial iniziale, l’inizio di una connessione TCP/IP richiede uno scambio di messaggi tra client e server detto triplo handshake.
La sequenza prevede che il client invii al server un pacchetto di richiesta connessione (il cosiddetto SYN packet); il server invia al client un pacchetto di conferma di disponibilità alla connessione (SYN/ACK packet); il client invia al server un pacchetto di conferma (ACK packet) e viene stabilita la connessione. Quando il server riceve il primo pacchetto di sincronizzazione (il SYN packet), lo memorizza e poi invia al client il SYN/ACK packet. Quando il server riceve l’ACK packet del client, cancella il SYN packet dalla memoria. Se dopo qualche minuto il server non ha ancora ricevuto l’ACK packet, il SYN packet viene comunque eliminato. Se al server arrivano contemporaneamente (o quasi) più richieste di connessione, i SYN packet vengono messi tutti nella memoria
Generalmente la coda di attesa di un server può contenere solo una decina di SYN packet: se la coda di attesa è piena i successivi SYN packet vengono scartati e i client che li hanno inviati non si potranno connettere al server (al più potranno tentare in un secondo momento). Quando il server preleva un SYN packet dalla coda di attesa, lo elabora, invia il SYN/ACK packet al client e poi rimette il SYN packet nella coda, in attesa dell’ACK packet relativo. Nel frattempo il server elabora altri SYN packet presenti nella coda, invia i relativi SYN/ACK packet e rimette i SYN packet in coda (quindi nella coda di attesa si trovano SYN packet sia elaborati che da elaborare). Attenzione a distinguere le richieste di connessione dalle connessioni vere e proprie. Di solito un server di media potenza riesce a supportare qualche centinaio di connessioni contemporaneamente (si hanno così centinaia di utenti connessi simultaneamente allo stesso server). Lo stesso server però non riesce a memorizzare nella coda di attesa più di una decina di richieste di connessione. Le richieste di connessione diventano connessioni solo quando il server riceve l’ACK packet del client. Se la coda di attesa si riempie, i SYN packet che arrivano successivamente vengono scartati e nessuno può più connettersi al server. L’attacco syn flooding consiste proprio nel riempire la coda di attesa di un server. La tecnica è molto semplice. Supponiamo che: il server che si vuole attaccare abbia una coda di attesa che può contenere al massimo 10 SYN packet; il server attenda un minuto prima di togliere dalla coda di attesa un SYN packet per il quale un client non abbia inviato anche un ACK packet. Se un intrusoinvia al server 10 SYN packet diversi contemporaneamente (cioè fa 10 richieste di connessione diverse) e non fa seguire i relativi ACK packet, per un minuto il server non accetterà più richieste di connessione in quanto la coda di attesa è piena. Passato il minuto il server svuoterà la coda di attesa e potrà accettare nuovamente delle richieste di connessione. Se a questo punto l’intruso ripete l’operazione, il server rifiuterà richieste di connessione per un altro minuto. Supponiamo che il server venga utilizzato da un Internet provider per gestire le connessioni ad Internet dei propri abbonati, nessuno degli abbonati potrà collegarsi alla rete! E’ sufficiente poi che l’intrusomodifichi l’indirizzo del mittente (che si trova tra le informazioni aggiuntive presenti in ogni pacchetto che viaggia su Internet) per evitare di farsi scoprire. Difendersi da questo tipo di attacco è piuttosto difficile. Le uniche cose che si possono fare immediatamente sono: diminuire il tempo di permanenza dei SYN packet nella coda di attesa; aumentare la dimensione della coda di attesa.
Firewall
Un firewall è un dispositivo hardware/software messo a protezione di una LAN connessa ad Internet. Molto spesso si tratta di un computer destinato esclusivamente ad analizzare il traffico di rete, ma si possono trovare anche singoli router opportunamente configurati, oppure una combinazione di router e computer (
In questo modo tutte le connessioni vengono filtrate e controllate. In altre parole il firewall legge tutti i pacchetti che viaggiano da e verso Internet (proprio come uno sniffer), distruggendo quelli considerati pericolosi o comunque indesiderati.
Nel caso si abbia un server connesso ad Internet è opportuno pensare seriamente all’installazione di un firewall. Esistono sia prodotti commerciali che costano qualche decina di milioni, sia software di pubblico dominio a costo zero quali il Firewall Toolkit della TIS; provate a dare un’occhiata a http://www.tis.com
Prima di spendere dei soldi in un firewall conviene rendersi effettivamente conto delle proprie esigenze e di cosa si può e si deve chiedere ad un firewall. Attenzione però: nessun firewall può garantire l’inviolabilità assoluta; bisogna verificare continuamente il corretto funzionamento del firewall; è necessario stabilire delle norme di sicurezza, cioè una politica aziendale. Di questo ci occuperemo nei prossimi paragrafi parlando dello standard SURF (Stanford University Research Firewall - Firewall di Ricerca dell’Università di Stanford), sviluppato per difendere i sistemi di rete senza "strozzare" troppo i loro canali di comunicazione. Va detto subito che questo metodo è diverso da quelli adottati da alcuni prodotti commerciali. Comunque, SURF si basa su un ragionamento molto convincente: la maggioranza degli utenti di Internet desidera una difesa "ragionevole", i cui costi siano proporzionati al valore intrinseco dell’integrità e non all’intensità degli sforzi che gli intrusi potrebbero mettere in atto per violarla.
I principi base
Il principio base del SURF è presto detto: pur garantendo la massima sicurezza possibile, vogliamo consentire ai nostri utenti di decidere a quali servizi sui computer esterni accedere, invece di farlo noi per loro. Questo principio si traduce tecnicamente in tre semplici regole
1. (Regola d’oro) La richiesta autorizza la risposta
Tutti i pacchetti diretti verso l’esterno possono uscire; i pacchetti diretti verso l’interno possono entrare nel sistema difeso da SURF solo se sono risposte a richieste precedenti.
2. Sacrificare gli "ostaggi"
I pacchetti verso alcuni computer lasciati volutamente esterni al firewall (gli "ostaggi") non hanno limitazioni. Un "ostaggio" SURF è una macchina esterna i cui dati possono essere facilmente ricreati partendo da informazioni tenute in modo sicuro dietro al firewall. L’immagine pubblica esposta a Internet è sempre il primo obiettivo per gli intrusi. Limitando il numero di computer esposti e rinunciando a difenderli si riduce l’esposizione degli altri agli attacchi più banali.
3. Esterni sì ma con prudenza
Solo i pacchetti provenienti da computer o da utenti esterni autenticati sono ammessi entro il firewall.
Il fondamento delle regole è semplice. La regola 1 deriva dalla convinzione che l’accesso "aperto" alla Rete sia un’esigenza indispensabile; la politica di sicurezza si basa quindi sul fatto che una richiesta uscente contiene implicitamente il permesso di introdurre la risposta nella nostra rete sicura. La regola 2 consente la divulgazione delle informazioni tramite computer "sacrificabili" al di fuori del perimetro di difesa. La regola 3 garantisce agli utenti l’accesso a risorse protette mentre lavorano da casa o in viaggio. Ma vediamo ora come mettere in pratica queste regole
3. La regola d’oro: implementazione
Per mettere in pratica la regola di richiesta-risposta occorre installare un firewall ovvero un filtro dei pacchetti sulla linea che collega il nostro sistema al resto di Internet. Si tratta di un dispositivo, hardware o software, che non inoltra all’interno i pacchetti IP che non soddisfano alle condizioni prefissate sul valore di alcuni campi. Per semplicità e facilità di manutenzione è meglio realizzare il filtro usando componenti già pronti, anche se quelli disponibili non sempre si comportano in modo ottimale.
Ma il filtro da solo non basta: occorre anche presupporre il comportamento corretto del software di rete dei sistemi operativi dei computer interni. Dobbiamo affidarci al comportamento dei nodi interni perché il filtro dei pacchetti di solito è privo di stato; cioè "vede" solo il pacchetto corrente e non ha accesso ai pacchetti precedenti o allo stato di un qualsiasi computer interno.
L’obiettivo è individuare se un pacchetto entrante è effettivamente una risposta a una precedente richiesta di un computer interno ed eliminarlo in caso contrario. Si ottiene ciò eliminando le richieste di connessione entranti e lasciando poi che siano i computer interni a lasciar cadere i dati estranei che il filtro lascia passare. Questa semplice tecnica funziona perfettamente per i servizi esterni che stabiliscono connessioni TCP esplicite, ma come vedremo sfortunatamente non vale in tutti gli altri casi, per i servizi che usano UDP.
La convivenza con NFS
La politica di sicurezza SURF consente che i client NFS protetti dal firewall abbiano accesso a filesystem esterni dotati di una primitiva di mount tipo NFS. Questa decisione è molto diversa dalle politiche tradizionali di sicurezza, assai più conservatrici. Ma la "libertà di mount" non significa che SURF rinunci a difendere la porta NFS del nostro sistema.
In pratica, per realizzare un (approssimativo) filtraggio richiesta-risposta sulle richieste di lettura e scrittura NFS, si possono esaminare i contenuti dei pacchetti diretti alla porta NFS e lasciare cadere tutti i pacchetti tranne le risposte a precedenti RPC. Si ricordi che il processo di esecuzione di un mount NFS richiede un dialogo con il programma di mount del sistema remoto. Per evitare problemi con la gestione delle porte UDP, occorre sostituire su tutti i sistemi difesi da SURF il mount NFS standard con un’utility remota che esegua l’accesso al server via TCP invece che via UDP.
Uso dei proxy
I più attenti tra i lettori non avranno mancato di osservare che i protocolli a livello di applicazione basati su UDP, come il DNS per la traduzione nomi - indirizzi, non rispettano il paradigma di richiesta-risposta richiesto da SURF. Il problema è che la maggior parte delle applicazioni utilizza UDP in modalità senza connessione, e quindi riceve tutti i pacchetti a lei indirizzati indipendentemente dall’indirizzo o dalla porta esterni da cui provengono; in questo caso il sistema operativo del ricevente non elimina i pacchetti estranei come fa TCP, e il filtraggio richiesta-risposta non è garantito.
Per le applicazioni critiche si possono però usare dei proxy per forzare lo schema di richiesta-risposta su un protocollo che altrimenti si comporterebbe male. Questi proxy girano su un computer "di difesa", un computer interno configurato specificatamente per questo scopo. In un ambiente difeso con SURF possono esistere vari computer di difesa, con il vantaggio di migliorare le prestazioni e di specializzare ciascun computer di difesa in una serie limitata di protocolli applicativi. Il filtro dei pacchetti viene impostato in modo da accettare i pacchetti entranti per i protocolli applicativi basati su UDP solo se sono destinati a un preciso computer di difesa.
Ad esempio, per quanto riguarda DNS, si, possono configurare una serie di nameserver DNS interni subordinati che inoltrano a nameserver esterni tutte le richieste che ricevono. Per quanto riguarda gli altri protocolli basati su UDP, SURF prevede che gli utenti possano attivare questi servizi solo su una macchina "ostaggio" esterna al firewall.
Si noti che esistono programmi proxy già pronti per i clienti X remoti, per l’FTP (ne esiste anche uno realizzato a scopo didattico in Italia, presso l’Università di Verona) e per le login degli utenti. Si tratta di una soluzione spesso usata dai firewall aziendali. Comunque, l’utilizzo di proxy a livello applicativo è solo un palliativo in attesa di una riprogettazione dei protocolli applicativi che tenga conto della sicurezza e permetta di realizzare completamente la politica di richiesta-risposta.
La seconda regola: ostaggi e software non sicuro
Alcuni tipi di software sono intrinsecamente non sicuri, specialmente quando gli input arrivano dall’esterno del sistema protetto da SURF. L’esempio più ovvio è la posta elettronica. Vista la lunga storia di problemi di sicurezza del programma sendmail, quello che trasmette la posta in partenza usando il protocollo SMTP, SURF propone di non usare un sendmail interno per trasmettere posta elettronica che ha origine dall’esterno del firewall. Tutta la posta elettronica esterna dev’essere inoltrata da un sendmail "insicuro", posto su un computer ostaggio. La posta elettronica d’origine interna, al contrario, è elaborata da un sendmail protetto, posto su un server di posta elettronica interno. I computer protetti sono informati solo dei server di posta elettronica interni; i computer esterni vedono solo i server di posta elettronica esterni.
C’è un apparente problema in questa tecnica, rappresentato dal fatto che la separazione tra posta elettronica interna ed esterna sembra forzare gli utenti ad usare due programmi di posta diversi nei due casi, visto che devono accedere a due file di spool separati. Per affrontare questo problema, il server della posta elettronica interna può usare NFS per eseguire un mount della directory di spool del computer ostaggio usato per la posta elettronica esterna. Per ogni utente autorizzato sul sistema interno, viene poi creato un processo che controlla periodicamente la posta elettronica nella directory di spool del server esterno e se necessario la aggiunge al file di spool interno appropriato. Per l’utente, quindi, la posta elettronica interna ed esterna sono indistinguibili, anche se le due categorie vengono elaborate da processi di sendmail attivi su macchine diverse.
Questa tecnica offre due vantaggi significativi rispetto all’usuale POP (Post Office Protocol) che abbiamo visto in precedenza. Prima di tutto, a parte un leggero ritardo nell’arrivo della posta elettronica dall’esterno del firewall, la consegna remota e locale sono trasparenti per gli utenti. Inoltre, i meccanismi standard di invio della posta elettronica e gli alias sono naturalmente estesi all’ambiente del firewall. Infine, poichè la posta elettronica interna non lascia mai il firewall, il nostro sistema consente l’invio di posta elettronica interna a continuare e rimanere sicura anche quando la connessione con la rete esterna viene a mancare; non appena la rete è ripristinata, l’invio di posta elettronica esterna riprende come al solito.
La terza regola: estranei sì ma con prudenza
I firewall aziendali presuppongono spesso una gerarchia di rete che corrisponde alla gerarchia aziendale. La maggior parte degli utenti, quindi, è collocata fisicamente all’interno del firewall aziendale. Questo crea un problema, ad esempio, alle Università, dove l’utente remoto, professore o studente che lavora da casa potenzialmente si avvicina al firewall attraverso una rete non sicura.
L’architettura SURF consente di affrontare questo problema in due modi. La prima tecnica, detta tunnel IP sicuro , serve per collegare due sottosistemi protetti con SURF via un tratto di Internet non sicuro.
Per connettere i due siti isolati si crea via router un tunnel IP sicuro tra di loro. Su queste connessioni sicure, i pacchetti sono crittografati prima della trasmissione. I punti terminali del tunnel sono noti e il filtro assicura che i pacchetti entranti sono effettivamente parte di un tunnel già registrato. In alternativa, si può usare una connessione privata non Internet, cioè una linea dedicata o un modem veloce. In molti casi, però, i tunnel IP permanenti non bastano. I clienti di un provider, per esempio, non useranno certo un computer di fiducia prefissato. Per consentire l’accesso entrante in questi casi, occorre che i canali di collegamento remoto realizzino un collegamento in emulazione di terminale a una macchina all’interno del firewall. Il supporto per questo servizio è facile: basta che il filtro dei pacchetti consenta agli utenti remoti l’accesso a una singola macchina di difesa. Solo dopo che hanno superato l’autenticazione sulla macchina di difesa, agli utenti viene dato un proxy che permette una singola sessione telnet a una macchina posta all’interno del firewall. Si noti che non viene dato accesso a una shell Unix sulla macchina di difesa, perchè in genere una macchina su cui si può eseguire la shell è più facilmente attaccabile.
Quello che SURF non può dare
Lo standard SURF è tutt’altro che impenetrabile. Anzi, presenta tre evidenti vulnerabilità: manca una seconda linea di difesa (dietro al firewall c’è un ambiente aperto), il filtro dei pacchetti entranti è approssimativo e c’è la possibilità di sfruttare per scopi ostili le connessioni iniziate a scopi leciti. Affrontare queste vulnerabilità è possibile, ma occorre comunque pagare un prezzo. Il primo rischio sorge perchè non si controlla il traffico tra le macchine poste dietro al firewall e non si filtrano i pacchetti in uscita. Di conseguenza, un intruso che entri nel perimetro di sicurezza ha un accesso illimitato a tutti i computer interni. In realtà, una volta che è stato forzato, SURF offre più alcuna protezione. Tuttavia, qualsiasi tentativo per ridurre questi rischi diventerebbe visibile agli utenti autorizzati e potrebbe rendere il firewall inaccettabile ai loro occhi.
Il secondo rischio sta nel progetto dei filtri. Poichè si usa un filtro a granularità grossa e ci si basa sui computer interni per eseguire filtraggio aggiuntivo, in pratica si ammettono pacchetti che possono anche non essere risposte a richieste sospese. Questa politica espone il sistema a un attacco basato su pacchetti di disturbo. Il rischio, però, esiste con qualsiasi tecnica di protezione, quindi non lo si considera significativo.
Comunque, nel dare fiducia a computer interni perchè scartino i pacchetti non corretti ammessi dal filtro, dobbiamo scegliere attentamente la serie di protocolli che il filtro dei pacchetti accetta; potremmo altrimenti ammettere dei pacchetti "Cavallo di Troia" che si fingono risposte a un’applicazione ma sono infatti richieste a un’altra. Per lo meno, però, questi rischi si conoscono in anticipo. Prima di ammettere un particolare protocollo di applicazione attraverso il firewall, i gestori della rete protetta devono valutare il rapporto rischi/vantaggi.
L’ultimo rischio nasce da potenziali attacchi eseguiti sulle connessioni autorizzate. Per affrontare questi pericoli, però, basta stare attenti nel selezionare le applicazioni che sono disponibili agli utenti. Ad esempio, è sconsiderato permettere che un’applicazione passi attraverso il firewall se i suoi pacchetti di risposta possono ottenere il controllo di una shell all’interno del firewall. SURF è vulnerabile a questo tipo di attacco perchè consente accesso autenticato attraverso computer potenzialmente insicuri esterni al firewall. Inserendosi fraudolentemente tra l’utente remoto e SURF, gli intrusi possono ottenere un accesso completo alla nostra rete. Questi rischi verranno eliminati del tutto solo quando saranno disponibili dei personal in grado di supportare telnet crittografata. Per ora, non resta che consigliare l’adozione di password monouso.
Tutorial 11
Programmare applicazioni Internet
Quest’ultimo tutorial di rivolge agli esperti programmatori, ma anche ai semplici appassionati, che vogliono capire "come si realizzano" gli strumenti software che abbiamo usato nei tutorial precedenti. In questo tutorial faremo spesso riferimento al concetto di processo, ed alle primitive che, in un ambiente esecutivo multitasking, consentono a più processi di comunicare tra loro. Sistemi multitasking sono OS/2, Windows NT e il sistema operativo dell’Amiga; in un certo senso anche Windows 95 e le più recenti versioni di Mac0S possono dirsi tali. Per semplicità, tuttavia, utilizzeremo come punto di partenza il sistema operativo Unix. Infatti, la versione per personal computer di Unix che prende il nome di Linux è diffusissima tra gli studenti e gli appassionati di programmazione distribuita. Per questo premettiamo alla trattazione vera e propria una breve introduzione a Unix, ovviamente valida anche per Linux, con particolare riferimento alla problematica della comunicazione tra i processi. Per motivi di spazio, questa trattazione presuppone le nozioni di base sui sistemi operativi e una conoscenza elementare dei linguaggi di programmazione C e Java..
Un ripasso su Unix
In una prima schematizzazione il
sistema operativo Unix può essere suddiviso verticalmente in due livelli, un livello utente per i programmi
applicativi ed un livello kernel
che interagisce direttamente con l' hardware. Orizzontalmente, invece si può
dividere in tre sottosistemi funzionalmente separati: il file system per la gestione
del disco, il sistema di gestione
dei processi e il
sistema per la gestione delle comunicazioni in rete.
Le applicazioni interagiscono con il kernel attraverso un insieme ben
individuato di chiamate di sistema; per il programmatore C queste
chiamate di sistema sono accessibili per il tramite di apposite librerie
di funzioni fornite con il compilatore. In Unix, sono eseguiti al livello
utente anche dei compiti che in altri sistemi operativi richiedono il passaggio
al livello inferiore; ad esempio, è un processo utente lo stesso interprete dei
comandi di sistema, che può essere la Bourne shell (così chiamata dal
nome del suo implementatore, Steve Bourne), la C shell (che incorpora un
potente linguaggio di programmazione), oppure una tra le varie interfacce
grafiche basate su X/Window oggi disponibili. Inoltre, sono programmi
utente anche tutta una serie di strumenti per lo sviluppo di software
(dall'editor vi al sistema di sviluppo per il linguaggio C al generatore
automatico di compilatori yacc) che non verranno qui trattati ma che
costituiscono uno dei punti di forza del sistema.
Tra i compiti del kernel di Unix sono comprese anche la gestione della memoria e del multitasking, la gestione degli archivi su disco, la gestione dell'input/output e la comunicazione tra processi. Questi compiti non sono realizzati da specifici processi indipendenti di sistema, con cui le applicazioni utente devono colloquiare; anzi, il codice che realizza queste funzioni viene di volta in volta agganciato ai vari processi in esecuzione. Ogni processo viene così eseguito parte in modalità utente, parte in modalità kernel; la transizione sincrona tra queste due modalità avviene appunto tramite le chiamate di sistema. Ovviamente il codice del kernel non è riprodotto ogni volta bensì condiviso tra i vari processi; parimenti condivise sono oggi anche le librerie utente di utilizzo più frequente (librerie condivise o shared libraries).
Nell'accezione intuitiva del termine, un processo non è altro che un programma in corso di esecuzione e quindi fornito del contesto a ciò necessario. Nella terminologia di Unix, più precisamente, un processo (spesso detto istanza di esecuzione di un programma) è costituito da tre segmenti di memoria, codice, dati e stack, nonché da uno stato che comprende il valore corrente delle variabili locali, oltre all'elenco dei file aperti. Per descrivere lo spazio di indirizzamento di un processo conviene immaginarlo come una zona di memoria ad indirizzi linearmente crescenti e suddivisa in più parti. La prima parte è riservata al codice (le istruzioni macchina che costituiscono il testo del programma) ed è, come abbiamo detto, condivisibile in tutto o in parte; la sua dimensione resta costante durante il corso dell'esecuzione. Con le stesse caratteristiche può poi essere presente una zona di memoria per le librerie condivise . A seguire si trova il segmento dati, che è suddiviso in due parti: una zona espandibile a lettura e scrittura detta heap (che ovviamente non è condivisibile), ed una zona di dimensioni costanti, sempre a lettura e scrittura, che può invece essere condivisa.
Infine vi è il segmento stack:
una zona di memoria non condivisibile con accesso in lettura e scrittura, che
ovviamente è espandibile. Si noti che la espansione dello heap avviene per indirizzi
crescenti, mentre quella dello stack per indirizzi decrescenti e pertanto vi
può essere competizione per l'utilizzo della memoria disponibile per il
processo. Nella implementazione odierna questa struttura logica è distribuita
su più pagine fisiche che possono risiedere su memoria centrale o su disco
secondo quanto stabilito dall'algoritmo di memoria virtuale (demand paging).
Ad eccezione del primo, tutti i processi di Unix nascono per filiazione
attraverso la coppia di primitive fork()
ed exec().
La prima ha l'effetto di duplicare
le aree dati e stack e lo stato (ivi compresa la tabella dei file aperti) del
processo che la esegue, mentre la seconda ha il compito di sostituire l'area
codice del processo neonato con il testo di un programma caricato da disco. E'
a questo punto quindi che le due immagini di memoria di due processi padre e
figlio assumono un aspetto diverso. Si osservi che già questa sostituzione può
comprendere una forma di comunicazione tra processo padre e processo figlio
poiché la exec() ha numerose varianti che consentono tutte il
passaggio di parametri. Vi sono altre chiamate di sistema che consentono un
certo grado di sincronizzazione tra processo padre e processo figlio: la
chiamata wait() consente al padre di sospendersi finché il
figlio non termina la sua esecuzione. Ciò ad esempio accade quando la shell
attiva un comando come processo figlio (esecuzione foreground). Se la
chiamata wait() non viene fatta la shell può accettare altri comandi mentre il
precedente è in corso di esecuzione (esecuzione background).
Quando un processo va in esecuzione gli viene assegnata la CPU per un periodo di tempo prefissato detto quanto al termine del quale il controllo torna d'ufficio al processo schedulatore, che ha il compito di scegliere tra i processi pronti (ovvero che non sono in attesa di un evento esterno quale la terminazione di un figlio o il completamento di una operazione di I/O) quello cui affidare la CPU. La scelta avviene secondo uno schema di priorità dinamica organizzato su livelli base crescenti con il tempo d'attesa; inoltre il processo che ha appena esaurito il suo quanto di tempo non può riottenere immediatamente la CPU (tecnica che prende il nome di round robin). La percentuale del quanto di tempo che viene effettivamente utilizzata viene poi usata per discriminare i processi in due comunità: quelli ad alto utilizzo della CPU (detti processi CPU-bound) e quelli ad alto utilizzo delle periferiche (processi I/O-bound). Questa informazione viene utilizzata dallo schedulatore per ottimizzare l'utilizzo del processore.
Il file system di Unix
Il sistema operativo Unix realizza agli
occhi dell'utente l'astrazione di un file system gerarchico strutturato ad
albero. I nodi interni dell'albero vengono chiamati indirizzari o directory
mentre le foglie possono essere indirizzari vuoti oppure file. Un file dati
ordinario non è altro che una sequenza di byte memorizzata su disco, cui il
sistema non aggiunge alcuna metainformazione di struttura.
La gestione della metainformazione che definisce la struttura dell'archivio è
quindi interamente responsabilità delle applicazioni utente. Un indirizzario è
un file ordinario che contiene un elenco di nomi di file corredati da
informazioni di servizio e da un numero intero (i-number) che consente
di accedere, in un vettore di strutture (i-list), alla locazione (i-node)
che contiene le informazioni necessarie a localizzare sul disco i blocchi che
costituiscono il file. Ciascun file è quindi individuato univocamente dalla
sequenza dei nomi degli indirizzari che lo collegano alla radice dell'albero.
Questa sequenza prende il nome di percorso di indirizzario o pathname.
Si noti che, per evitare inutili duplicazioni sul disco, più nomi elencati in
più indirizzari possono corrispondere allo stesso i-node; il numero di volte
con cui un i-number compare nel file system viene detto numero di link
del file su disco.
Cancellare un file significa quindi diminuire di uno il numero dei suoi link;
la cancellazione effettiva dell'i-node (e la liberazione dello spazio su disco)
avverrà soltanto quando il numero di link diviene pari a zero. Una ben nota
caratteristica di Unix è quella di trattare come file anche i dispositivi
periferici, che sono quindi elencati nell'indirizzario /dev. I loro nomi
individuano programmi (detti device driver) che gestiscono direttamente
il colloquio con i controller delle periferiche. A ciascun file
corrisponde un elenco di attributi elencati nell'i-node: l'identificazione
dell'utente che lo ha creato (il proprietario), la sua lunghezza in byte, le
date di creazione, modifica e ultimo accesso, il tipo del file e il numero di
link, nonché i 9 bit di protezione. Considerati a gruppi di tre, questi bit
corrispondono ai permessi di lettura, scrittura, esecuzione rispettivamente per
il proprietario del file, per il gruppo di lavoro cui questi appartiene ed
infine per la totalità degli utenti del sistema. Quando un file viene creato ad
opera di un processo, gli vengono attribuiti i permessi secondo la maschera
precedentemente assegnata al processo stesso tramite un'opportuna chiamata di
sistema. Il proprietario di un file può comunque modificare i permessi di
accesso a suo piacimento.
Unix prevede un utente particolare, il cui nome convenzionale è root, che risulta proprietario di tutte le risorse del sistema. Questo utente, che viene anche chiamato superuser può quindi modificare le protezioni di qualunque file del file system.
Il modello fin qui presentato corrisponde ad una visione unitaria del file system; in realtà i blocchi che costituiscono i file saranno scritti su un certo numero di dispositivi diversi, in generale dischi e/o nastri magnetici. Questa apparente contraddizione viene risolta unificando i vari dischi nel file system principale attraverso la chiamata di sistema mount(). Supponendo, ad esempio, di avere un file system separato su un dischetto, mount() consente di far coincidere la radice di questo file system secondario con un qualunque indirizzario vuoto del file system principale. Dualmente, la chiamata unmount() consente di sganciare i due file system. Poiché una apposita chiamata di sistema, mknod(), consente di creare su un disco formattato un file system secondario composto da una sola directory, è chiaro come mount() possa essere utilizzata per realizzare una struttura logica unitaria a partire da un numero qualsiasi di dischi. Dopo l'aggancio infatti agli occhi degli utenti non vi è più alcuna distinzione tra i file residenti sul disco di sistema quelli che si trovano su altre unità di memoria di massa. In questo modo il sistema realizza la completa trasparenza per l'utente dell'effettiva localizzazione dei file sui vari dischi o nastri installati localmente.
La gestione dell'I/O
Ad ogni periferica connessa con un sistema Unix è associato un modulo
software di sistema che prende il nome di device driver associato alla
periferica. Quando un processo utente deve compiere una qualunque operazione
sul dispositivo dovrà passare le istruzioni relative al device driver
corrispondente che si incaricherà di eseguire effettivamente l'operazione. Per
comunicare con i device driver, i processi utente possono utilizzare l'usuale
sintassi (e, fino ad un certo segno, anche la semantica) delle chiamate di
sistema per la gestione dei file ordinari, poiché ai vari dispositivi
corrispondono altrettanti nomi di file raggruppati nella directory /dev. Quando un processo esegue
un'operazione di apertura, lettura e scrittura oppure di chiusura su uno dei
file corrispondenti alle periferiche ( detti file speciali ), il sistema
operativo inoltra la richiesta al device driver corrispondente al dispositivo.
Secondo la terminologia Unix vi sono due classi di dispositivi cui
corrispondono due tipologie fondamentali di
device driver: le periferiche a blocchi e quelle a caratteri.
Le operazioni di I/O relative ad un dispositivo a blocchi coinvolgono, come
dice il nome, blocchi di dati di lunghezza prefissata (tipicamente 512 byte).
Agli occhi di un processo una periferica a blocchi è pertanto costituita da un
insieme di unità di dati indirizzabili (e pertanto accessibili) singolarmente.
L'esempio tipico di un dispositivo a blocchi è quello di un disco in cui si può
accedere direttamente al blocco desiderato con un'operazione di seek(). I dispositivi a caratteri consentono invece
operazioni di I/O che coinvolgono un numero arbitrario di byte. Un'altra
importante differenza tra i dispositivi a blocchi e quelli a caratteri è che,
mentre l'inizio un'operazione di I/O su una periferica a blocchi avviene sempre
per iniziativa di un processo (è sempre un programma che decide di leggere un
file e mai un disco che chiede ad un programma di leggere un suo file), una
periferica a caratteri può prendere l'iniziativa di inviare dati in modo
asincrono (tad esempio, la tastiera di un terminale può inviare dati "di
sua iniziativa"). Una rete di comunicazione può essere considerata quindi
un dispositivo a caratteri, benché le operazioni di I/O ad essa relative
coinvolgano blocchi di dati di lunghezza fissa (i frame). Sui file speciali che
rappresentano dispositivi a caratteri è possibile eseguire una particolare
chiamata di sistema che ha il seguente formato:
ioctl(file_speciale,comando,argomento)
Il primo argomento di questa chiamata rappresenta il nome di file relativo al dispositivo desiderato, e non è altro che il descrittore precedentemente restituito dall'operazione di apertura. Gli altri argomenti non vengono interpretati dal sistema operativo, ma passati senza modifiche al device driver interessato. In genere essi corrispondono ad operazioni tese a modificare lo stato del dispositivo (ad esempio passare un terminale da raw mode a cooked mode).
La comunicazione tra processi
Unix mette a disposizione del programmatore una serie di costrutti per la comunicazione tra processi. In primo luogo abbiamo visto che due processi padre e figlio possono comunicare al momento dell'exec() attraverso il passaggio dei parametri. Vi sono numerose versioni della chiamata di sistema exec()che si differenziano per le modalità con cui viene effettuato il passaggio dei parametri. Nell'esempio che segue, la chiamata execlp() viene impiegata per passare al processo figlio una lista esplicita di parametri.
#include <stdio.h>
1 main()
2 /*Questo programma attiva un processo figlio passandogli quattro parametri*/
3 {
4 if (fork()==0)
5 {/*codice del figlio*/
6 puts("questa chiamata di execlp carica un'immagine per il figlio\n");
7 execlp("figlio","figlio","uno","due","tre",NULL);
8 puts("c'è stato un errore");}
9 else printf ("fine del processo padre");
10 }
A parte la riga 6, in cui la chiamata fork() duplica l'immagine del processo che la esegue dando vita al figlio, la parte più interessante di questo programma è la riga 7 che merita qualche parola di spiegazione. Mentre il processo padre prosegue la sua elaborazione eseguendo la riga 9, il processo figlio esegue la chiamata di execlp(). Il primo dei parametri di execlp() è il nome del file su disco che contiene il codice del processo che si desidera attivare. Il secondo parametro è la prima informazione comunicata al nuovo processo e ne rappresenta il nome. In questo caso il nome ("figlio") coincide con il nome dell'archivio su disco. Si tratta di una circostanza del tutto casuale. Il nome ed i parametri che seguono sono automaticamente accessibili al processo figlio attraverso l'array di puntatori *argv[]. Come è ben noto ai programmatori C, ciascuno degli elementi di argv[] corrisponde nel nuovo processo all'indirizzo di una delle stringhe passate come argomento dal padre. In particolare, *argv[0] è il nome del programma. All'esecuzione della chiamata execlp(), le parti codice e dati del processo precedente (e precisamente quelle duplicate dal padre) vengono perse, ma i file aperti e la directory corrente restano inalterati.
Un possibile codice per il figlio può essere quello riportato di seguito:
#include <stdio.h>
1 main(argc,argv)
2 /*Questo è il codice del processo figlio */
3 char **argv;
4 {
5 char **p;
6 puts("questi sono i parametri ricevuti dal padre\n");
7 for (p=argv; *p; p++) printf ("%s\n",*p);
8 }
Sfruttando il fatto che i file aperti dal processo padre restano tali anche per il figlio, i processi legati da un vincolo di ascendenza possono comunicare attraverso canali FIFO detti pipe (dal termine inglese che significa "condotto"). Si noti che con questo tipo di costrutti non è necessario specificare il nome del destinatario. Questo schema di comunicazione è reso possibile dal fatto che una chiamata fork() causa, tra le altre cose, la duplicazione della tabella dei file aperti relativa al processo padre. La chiamata di sistema pipe(), eseguita prima della fork(), inserisce in questa tabella due descrittori di file che non corrispondono però ad alcun blocco su disco, ma devono piuttosto essere pensati come i terminali di due linee di comunicazione monodirezionali: una per ricevere e l'altra per trasmettere. A duplicazione avvenuta, il padre ed il figlio si ritroveranno entrambi questi descrittori nella propria tabella. Basterà allora che ciascuno chiuda, con una normale chiamata close(), il descrittore corrispondente al senso della comunicazione che non gli interessa. In questo modo un processo disporrà del descrittore valido per la lettura e l'altro processo di quello valido per la scrittura. A questi descrittori si può accedere con le normali chiamate read() e write() normalmente utilizzate per scrivere e leggere su file. La sincronizzazione di lettura e scrittura è completamente a carico del sistema operativo. Si osservi che l'operazione di lettura è di tipo bloccante (un processo che tenta di leggere da una pipe vuota resta in attesa finché l'altro non vi scrive) e che la lunghezza della coda ha un massimo imposto dal sistema che solitamente è di 4096 byte. Un tentativo di scrittura oltre questa capacità fa sì che il processo si blocchi finchè l'altro non esegue una lettura. Segue ora un tipico esempio di impiego del meccanismo della pipe per codificare una comunicazione tra processi.
# include <stdio.h>
# define LEGGI 0
# define SCRIVI 1
1 main()
2/*Questo programma mostra una semplice applicazione della pipe. Il processo padre legge dallo standard input un carattere alla volta. Se si tratta di un carattere alfanumerico lo inoltra al figlio sulla pipe. Il figlio legge il carattere dalla pipe e lo converte in maiuscolo se necessario */
3 {
4 int pid; int pip[2]; /*descrittori per la pipe*/ char c;
5 if (pipe(pip)) exit(-1)
6 /*il valore di ritorno O indica che la chiamata è andata a buon fine*/
7 if (pid =fork()) /*codice del padre*/
8 {
9 close(pip[LEGGI])
10 /*il padre deve scrivere e quindi chiude il terminale di lettura*/
11 do {
12 c=getchar();
13 if (isalnum(c)||c=='\n')
14 write(pip[SCRIVI],&c,1);
15 }
16 while(c!='z');/*z termina la comunicazione*/
17 }
18 else /*codice del figlio*/
19 {
20 close(pip[SCRIVI])
21 /*il figlio deve leggere e quindi chiude il terminale di scrittura*/
22 do {
23 read(pip[LEGGI],&c,1);
24 if (islower(c)) c=toupper(c);
25 }
26 while(c!='Z');/*Z termina la comunicazione*/
27 putchar('\n');
28 }
29 }
Per ottenere questo stesso tipo di comunicazione tra processi che non sono legati da una relazione di ascendenza si può utilizzare una pipe con nome (named pipe) identica alla precedente tranne che per il fatto che il canale di comunicazione viene identificato da un nome che viene inserito nel file system, e che sarà quindi necessario cancellare al termine della comunicazione. Conoscendo il nome della pipe, qualunque processo può eseguirne la open() in lettura o scrittura anche senza avere vincoli di parentela con il processo che la ha creata.
Oltre alle pipe, in Unix vi sono tre altri costrutti fondamentali per la comunicazione: i messaggi che consentono di inviare flussi di dati formattati di lunghezza arbitraria, la memoria condivisa che permette a due processi l'utilizzo contemporaneo di una zona di memoria mappata in entrambi gli spazi di indirizzamento ed infine i semafori che consentono la sincronizzazione dell'esecuzione dei processi interessati.
Esecuzione dei processi in ambiente di rete
Nelle applicazioni client-server che abbiamo visto nei tutorial precedenti, i processi in esecuzione su nodi diversi comunicavano tra di loro analogamente a quelli impiegati in un ambiente esecutivo locale. Per scrivere programmi di questo tipo sono necessarie tecniche di programmazione che rendano la rete "trasparente" ai processi stessi e quindi ai programmatori che li hanno scritti. Una soluzione di questo problema, la socket library è illustrata in dettaglio nei prossimi paragrafi. Questa libreria, nata per Unix, è oggi usata per la realizzazione delle applicazioni Internet per pressochè tutti i sistemi operativi.
La socket library
Unix è un sistema multitasking: su una
singola macchina, molti processi sono in esecuzione contemporaneamente e
ciascuno si trova in una propria fase esecutiva in base alla schedulazione
fatta dal kernel di sistema. Ovviamente, in una macchina monoprocessore, il
parallelismo di esecuzione è fittizio: solo uno dei processi in ogni dato
istante ha la disponibilità della CPU e si trova obbligatoriamente in memoria
centrale. Gli altri processi sono in attesa di poter riprendere l'elaborazione
e possono essere stati copiati su disco con un'operazione detta di swap-out.
Ad eccezione del primo, comunque, tutti i processi di Unix nascono per
filiazione da un processo preesistente, attraverso la chiamata da parte del
padre della routine di sistema fork(), che si occupa di creare la voce relativa al
processo figlio nelle strutture dati che Unix utilizza per gestire i processi.
Una singola macchina multiprogrammata costituisce già di per sè un ambito di
comunicazione tra processi. Perchè la comunicazione sia possibile, occorre che
il processo chiamante sia in grado di specificare in qualche modo qual è il
processo con cui intende comunicare.
Come abbiamo visto nel paragrafo precedente, Unix fornisce ai processi un mezzo
semplice e potente per comunicare: le pipe. Ricordiamo che la gestione del
collegamento è resa semplice dal fatto che la pipe senza nome è un canale di
comunicazione 'ereditato'. In questo modo, non vi sono ovviamente problemi di
indirizzamento, ma è altrettanto ovvio che il momento e le modalità della
comunicazione attraverso una pipe sono, per loro natura eventi sincroni
all'esecuzione dei processi (cioè avvengono in momenti prefissati del flusso
esecutivo). Perdipiù, l'ereditarietà è un mezzo efficace ma troppo limitato per la
generazione dell'indirizzo del processo ricevente.
Per consentire la comunicazione in ambiente di rete, è stato sviluppato un
meccanismo alternativo alle pipe che spezza il vincolo dell'ereditarietà tra
processi comunicanti. Un socket è una struttura dati i cui elementi
possono essere utilizzati come argomenti delle usuali chiamate di sistema read()
e write() che consentono di scrivere e leggere i file
ordinari. Non vi è più vincolo di ereditarietà: l'argomento di naming
del socket, ovvero il nome del processo con cui va instaurata la comunicazione,
puòessere costruito secondo il modello di un path-name del file-system. Il
socket che Unix fornisce può essere utilmente pensato come l'analogo di un
dispositivo di comunicazione, di cui i processi possono dotarsi su richiesta: i
dati trasmessi, infatti, sono inoltrati al processo ricevente senza il supporto
di file intermedi. Sulla base delle primitive di comunicazione che coinvolgono
i socket (accessibili al programmatore C tramite apposite librerie di funzioni)
vengono poi realizzati gli schemi di comunicazione che si collocano ad un
livello di astrazione superiore, cme la chiamata di procedura remota descritta
nei paragrafi precedenti. Vediamo a titolo d'esempio iniziale il listato,
estesamente commentato , di un programma in linguaggio C corrispondente a due
processi, che usa i costrutti di comunicazione che abbiamo appena descritto.
#include <stdio.h>
#define DATA 'Nel mezzo del cammin di nostra vità
/* In questo programma vengono creati due processi, ed il
processo figlio comunica con il padre usando una pipe. Si
noti che il processo che deve scrivere sul socket di
output (sockets[1], primo elemento dell'array fornito dalla
chiamata pipe()) deve chiudere il proprio socket di input
(sockets[0]), e viceversa.*/
main()
{
int sockets[2], figlio;
/* Qui crea la pipe */
if (pipe(sockets)<0)
perror('errore nella apertura di uno stream socket')
/* Qui esegue la fork */
if (figlio=fork())
{
char buf[512];
/* Questo è il codice del padre: legge il messaggio del
figlio */
close (sockets[1])
/*Il padre deve leggere e quindi chiude il socket di input*/
if (read(sockets[0],buf,512)<0)
perror(' errore di lettura messaggio');
printf("%s",buf);
close(sockets[0]);
}
else
{
/* Questo è il codice del figlio: scrive un messaggio al
padre */
close (sockets[0]);
/* Il figlio deve scrivere e quindi chiude il socket di
input*/
if (write(sockets[1],DATA,sizeof(DATA))<0)
perror('errore di scrittura messaggio');
close(sockets[1]);
}
}
Rispetto all'utilizzo classico delle pipe come canale di comunicazione monodirezionale, il prossimo esempio mostra la maggior duttilità dei socket realizzando un canale virtuale full duplex tra due processi. , In questo caso le chiamate alle primitive di comunicazione forniranno un array di due elementi detto socketpair, che consente lo scambio di dati in entrambe le direzioni. Ambedue i processi coinvolti nella comunicazione hanno così a disposizione una linea virtuale gestita da Unix su cui possono scrivere e leggere, usando le chiamate read() e write().
#include <sys/types.h>
#include <sys/sockets.h>
#include <stdio.h>
#define DATA1 'Tanto gentile e tanto onesta parè
#define DATA2 'La donna mia quand''ella altrui salutà
/* Questo programma crea un socketpair, poi esegue una
fork ed i due processi risultanti comunicano
utilizzandolo. Il socketpair è bidirezionale, e la
comunicazione puòavvenire in entrambi i sensi.*/
main()
{
int sockets[2],figlio;
/* Qui richiede il socketpair */
if (socketpair(AF_UNIX_SOCK_STREAM,0,sockets) < 0)
perror(' errore nella apertura del socketpair');
if (child=fork())
{
char buf512];
close (sockets[0]);
if (read (sockets[1],buf,512,0) < 0)
perror(' errore nella lettura del messaggio');
printf("%s",buf);
if (write(sockets[1],DATA2,sizeof(DATA2)) < 0)
perror( ' errore nella scrittura del messaggio');
close(sockets[1]);
}
else
{
char buf[512];
close (sockets[1]);
if (write(sockets[0],DATA1,sizeof(DATA1)) < 0)
perror('errore nella scrittura del messaggio');
printf("%s",buf);
if (read(sockets[0],buf,512,0)) < 0)
perror('errore nella lettura del messaggio');
printf("%s",buf);
close(sockets[0]);
}
}
I socket nelle applicazioni di rete
Passando dall'ambito esecutivo di un'unica macchina all’intera Internet, la comunicazione tra processi diventa assai più complessa. Infatti, occorre fornire ai processi che devono instaurare una comunicazione il modo di costruire l'indirizzo del processo destinatario, che si trova in generale su un altro nodo della rete. In Unix, come vedremo, il meccanismo di comunicazione locale delle pipe, è stato arricchito senza snaturarne le caratteristiche, semplicemente fornendo ai socket degli opportuni attributi che corrispondono a precise richieste per il software di sistema che gestisce la comunicazione. Un processo in esecuzione su un nodo della rete può così chiedere al sistema operativo il socket relativo al tipo di comunicazione tra processi che intende instaurare. Come verrà chiarito nel seguito, gli attributi dei socket consentono poi di precisare in modo molto efficace anche la natura della comunicazione. Gli attributi vengono decisi dal processo che richiede il socket usando l'opportuna chiamata di sistema per ottenere il socket di tipo corrispondente al protocollo di comunicazione desiderato. Ciòconsente di gestire i complessi protocolli ad alto livello richiesti dalle reti di calcolatori mantenendo nel contempo un'elevata uniformità d'ambiente con le installazioni singole; il che costituisce un ovvio requisito per la portabilità delle applicazioni. Dopo aver chiarito cosa sono gli attributi, vediamo ora i valori che possono assumere. Un primo attributo dei socket è il domain, che assumendo i valori Unix, Internet od altri (come riassunto nella tabella di figura 3.5) consente di selezionare una comunicazione locale o remota.
I valori dell'attributo domain
Il protocollo di comunicazione è associato all'attributo tipo, che puòassumere i valori stream, datagram e raw. Il valore stream indica la modalità d'inoltro dei dati senza interruzioni e nell'ordine in cui sono scritti: utilizzando questa terminologia, una usuale pipe risulta così un caso particolare di stream socket per Unix domain. Il valore raw, dal canto suo, disattiva le operazioni di conversione che avvengono sui dati trasmessi a carico dello strato di sessione del software di comunicazione per ovviare ai differenti modi di rappresentazione dell'informazione (ad esempio codici diversi, come ASCII ed EBCDIC).Infine il tipo datagram seleziona il protocollo di rete UDP, chiedendo al sistema operativo di compiere tutte le operazioni di livello inferiore necessarie per una comunicazione a pacchetti. Secondo questo protocollo, come abbiamo visto nel tutorial uno, i dati vengono inviati divisi in pacchetti, i datagram, ciascuno dei quali reca l'indirizzo del destinatario ed un numero progressivo. Le modalità di inoltro non garantiscono neppure l'arrivo dei pacchetti nello stesso ordine di trasmissione, ma la presenza del numero progressivo consente al sistema di ricostruire l'ordine logico dei dati. Questo tipo di comunicazione si presta alle esigenze delle reti di calcolatori per le sue caratteristiche di elevata affidabilità: se alcuni pacchetti risultano danneggiati, il sistema può richiederne la ritrasmissione in modo trasparente ai processi coinvolti e senza che occorra inviare di nuovo l'intero messaggio. Per ora limitiamoci al più semplice caso della comunicazione Unix domain, ossia nell'ambito di un singolo nodo, e vediamo come siano risolti in questo caso più semplice i problemi di indirizzamento necessari all'invio di datagram tra processi in esecuzione.
Per poter mettere in comunicazione due processi tra cui non vi è relazione di parentela, occorre risolvere il problema dell'indirizzamento. Nel caso centralizzato il sistema puòmettere a disposizione di un processo che desideri comunicare meccanismi semplici ed efficaci per l'identificazione del processo destinatario, come le tecniche di denominazione (naming) fornite dal file system; in un ambiente distribuito occorre invece che il sistema operativo installato su ogni singolo nodo consenta di indirizzare processi in esecuzione su altri nodi della rete. L'indirizzamento avviene individuando il socket del processo destinatario: ad ogni socket si puòcosì considerare associato un nome, che gli altri processi devono conoscere per poter instaurare la comunicazione.
Il processo che desidera instaurare una comunicazione deve chiedere al sistema il relativo socket. Ciò avviene semplicemente attraverso l'esecuzione da programma della chiamata socket() che ha per argomento gli attributi richiesti per la comunicazione (nel nostro caso, dominio Unix e tipo datagram). Poi, occorre che il processo trasmittente costruisca il nome associato al socket del processo ricevente. Poichè siamo in Unix domain, il nome può venir generato utilizzando il modello dei pathname del file system. Al pathname è associato, in una struttura, un intero (in termini C, uno short int) che identifica l'ambito della comunicazione ed assume il valore della costante UNIX. Questa struttura può ora essere un argomento della chiamata sendto() che invoca gli strati inferiori del software di comunicazione. Perchè alla struttura corrisponda ad un nome valido, occorre che il processo destinatario disponga a sua volta di un socket cui abbia precedentemente associato, con un'operazione detta binding, lo stesso nome, ossia una struttura di egual valore.
ttraverso una chiamata bind(),che ha per argomento un nome ed il socket cui va attribuito, il processo informa il sistema operativo di voler ricevere comunicazioni; da quel momento, ogni chiamata di sendto() effettuata da un processo trasmittente, che abbia per argomento quel nome, corrisponderà all'attivazione da parte del sistema di un opportuno canale di comunicazione.
Un programma di esempio , INVIO1, che realizza questo tipo di comunicazione è riportato nel seguito. La sintassi della linea di comando per far eseguire questo programma è:
INVIO1 pathname
Nel file sys/un.h, che è dichiarato incluso, la struttura sockaddr_un è definita come segue:
struct sockaddr_un { short sun_family;
char sun_path[109];
}
Passiamo ora al listato del programma.
#include <sys/types.h>
#include <sys/socket.h
>#include <sys/un.h>
#include <stdio.h>
#define DATA ' Sempre caro mi fu quest''ermo colle '
/* Questo codice invia un datagram ad un processo ricevente
il cui nome viene precisato dall'utente sulla linea di
comando. */
main (argc,argv)
int argc, char *argv[];
{
int sock;struct sockaddr_un nome;
/*Crea il socket su cui trasmettere*/
sock = socket(AF_UNIX,SOCK_DGRAM,0);
/* Gli attributi compaiono come argomenti della chiamata socket() */
if (sock<0)
{
perror (' errore di apertura socket per datagram');
exit(-1);
}
/*Costruisce il nome del socket a cui trasmettere*/
name.sun_family = AF_UNIX;
/* Il destinatario è locale */
strcpy(name.sun_path,argv[1]);
/*Prende il suo nome dalla linea di comando */
if(sendto(sock,DATA,sizeof(DATA),0,&name,sizeof(struct
sockaddr_un))<0)
{
perror('errore nell'invio del datagram');
}
close(sock);
}
Il codice che segue realizza invece il processo ricevente che comunica al sistema il nome associato al proprio socket . Da quel momento in poi viene abilitata la ricezione delle comunicazioni.
#include <sys/types.h>
#include <sys/socket.h>
#include <sys/un.h>
#include <stdio.h>
#define NOME 'pippo'
/* questo programma crea un socket per datagram in Unix
domain, gli associa il nome "pippo", poi legge dal socket.*/
main()
{
int sock,lunga;
struct sockaddr_un nome;
char buf[1024];
sock=socket(AF_UNIX,SOCK_DGRAM,0);
/*Crea un socket da cui leggere*/
if (sock<0)
{
perror ('errore di apertura del socket per datagram');
exit(-1);
}
name.sun_family=AF_UNIX;
strcpy(name.sun_path,NOME);
/*Creo il nome*/
if (bind(sock,&nome,sizeof(struct sockaddr_un)))
{
close (sock);
perror('errore di attribuzione del nome al socket');
}
printf(" il socket è %s",NOME);
if (read(sock,buf,1024,0)<0)
perror(' errore di ricezione di un pacchetto del datagram');
/*legge dal socket*/
printf("%s",buf);
unlink(NOME);
/*la denominazione del socket crea un i-node che va rimosso
*/
close(sock);
}
Nel caso di una comunicazione tra due
processi residenti ciascuno su una diversa macchina di Internet occorre
specificare, invece di un pathname locale, il nome (o il numero IP) del nodo su
cui gira il processo destinatario ed il port di comunicazione che, come
sappiamo, è un numero univoco che identifica il processo stesso. Entrambi i
processi coinvolti dovranno ovviamente disporre di socket di tipo opportuno e
relativi al domain desiderato . Nel prossimo esempio, i valori prescelti sono Internet
domain e datagram .
Oltre a questo, come si vede dal secondo esempio, al socket del ricevente dovrà
essere stato attribuito preventivamente un nome, con un'operazione di binding,
secondo il formato <indirizzo_nodo,port>. Va osservato che le informazioni relative
all'indirizzo di rete dei vari nodi e, sul singolo nodo, dei port assegnati ai
vari processi sono conoscenze globali che devono venir gestite dalla rete. In
pratica, ciò significa semplicemente che su ogni stazione di lavoro della rete
vi è un processo che tiene una tabella delle corrispondenze tra nomi dei nodi
ed indirizzi di rete e tra socket e relativi port. Come si è visto, eseguendo
le chiamate di sistema per ottenere un socket ed attribuirgli un nome occorre
assegnare come argomento della chiamata una struttura che contiene le
informazioni sul tipo di comunicazione che si intende instaurare.
Quest'argomento include una costante che precisa il domain in cui si desidera
comunicare (che nel nostro caso è AF_INET) e, nel caso di comunicazione Internet domain,
l'indirizzo del destinatario nel formato <indirizzo_nodo,port>. Ovviamente, questi dati non sono in generale
noti al processo che esegue la chiamata di binding: esso si limiterà a
'lasciare in biancòquesti entry delle strutture, che saranno riempiti da Unix
sulla base delle tabelle descritte sopra. Vediamo ora un programma, INVIO2,
che si incarica di inviare un datagram ad un processo residente su un altro
nodo di una rete TCP/IP.Il formato della linea di comando per attivare il
programma è:
INVIO2 nomenodo numeroport.
Ecco il listato.
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <netdb.h>
#include <stdio.h>
#define DATA 'Silvia, rimembri ancora...'
/* Questo programma, INVIO2, invia un datagram ad un
processo ricevente il cui nome viene ricavato dagli
argomenti sulla linea di
comando. */
main (argc,argv)
int argc;
char *argv[];
{
int sock;
struct sockaddr_in name;
struct hostent *hp, *gethostbyname();
sock = socket(AF_INET,SOCK_DGRAM,0);
/* Creo il socket su cui trasmettere */
if (sock<0)
{
perror('Errore di apertura del socket per datagram');
exit(-1);
}
hp = gethostbyname(argv[1]);
/* Costruisco il nome del socket a cui trasmettere.
Gethostbyname ritorna una struttura che comprende
l'indirizzo di rete dell'host, mentre il numero della
porta viene dalla linea di comando*/
bcopy(hp->h_addr,&(name.sin_addr.s_addr),hp->h_lenght);
name.sin_family = AF_INET;
name.sinport = atoi(argv[2]);
/* Mando il messaggio */
if (sendto(sock,DATA, sizeof(DATA),0,&name,sizeof(name))<0
{
perror('Errore nell'invio di datagram');
}
close(sock);
}
Il secondo esempio è il processo ricevente.Nel file dichiarato incluso <netinet/in.h> una struttura di tipo sockaddr_in viene definita nel modo seguente:
struct sockaddr_in { short sin_family;
short sin_port;
struct in_addr sin_addr;
char sin_zero[8];
};
Passiamo ora al listato del programma.
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <netdb.h>
#include <stdio.h>
/* Questo programma crea un datagram socket, gli attribuisce un nome e poi legge dal socket.*/
main()
{
int sock,length;
struct sockaddr_in name;
char buf[1024];
sock = socket(AF_INET,SOCK_DGRAM,0);
/* Crea il socket dal quale leggere */
if (sock<0)
{
perror('Errore nell''apertura del socket per datagram');
exit(-1);
};
/* Attribuisce il nome del socket utilizzando i wildcard */
name.sin_family = AF_INET;
name.sin_addr.s_addr = INADDR_ANY;
name.sin_port = 0;
if (bind(sock,&name,sizeof(name)))
{
close(sock);
perror('Errore di attribuzione del nome al socket');
}
length = sizeof(name);
if (getsockname(sock,&name,&length))
{
close(sock);
perror('Errore di richiesta del nome del socket');
}
printf('il numero della porta è%d",name.sin_port);
/* Trova il numero della porta assegnata e lo stampa */
if (read(sock,buf,1024,0)<0)
perror('Errore di ricezione del datagram');
/* Legge dal socket */
printf('"%s",buf);
close(sock);
}
Nel caso di un modello di comunicazione
a circuito virtuale TCP (che utilizzerà quindi uno stream socket per Internet
domain) il trasporto dalla singola macchina all'ambiente di rete è invece
leggermente più complesso. Sulla Rete, infatti, la creazione della connessione
TCP richiede l'analogo di una telefonata via centralino: precisando l'indirizzo
del destinatario, il trasmittente richiede al sistema una connessione tra i
socket che deve durare per tutta la durata della comunicazione. Questa
comunicazione consta di un flusso ordinato ed ininterrotto di dati, senza
delimitatori. Lo schema a circuito virtuale è tipico della situazione molto
comune in cui un Web server viene via via interrogato da più client. Ciascun
client chiede al sistema la connessione al Web server. Dopo averla ottenuta,
manda il suo messaggio. Poi si sconnette, lasciando la linea libera per la
chiamata successiva. Vediamo qualche dettaglio sulla procedura di connessione
facendo riferimento al prossimo esempio. Il client, che ha ottenuto un socket
dal sistema operativo secondo le solite modalità, ottiene l'indirizzo del
socket del processo con cui deve comunicare chiamando la funzione gethostbyname() e passandole il nome dell'host destinatario che ha ottenuto dalla
linea di comando. Ne riceve di ritorno un puntatore ad una struttura che
contiene l'indirizzo di rete del nodo corrispondente. Quest'informazione viene
poi copiata nella struttura server, che sarà usata come argomento della
successiva chiamata alla funzione di connessione. Assieme a questa informazione
sull'indirizzo dell'host destinatario, viene copiato nella struttura (dopo
l'opportuna conversione di tipo), il numero della porta che identifica lo
specifico processo con cui si desidera comunicare.
Anche il numero di porta provenie dalla linea di comando. Infine, viene
effettuata la chiamata di connect(), la funzione di connessione, che chiede al
sistema una linea virtuale passando come argomento la struttura , che ora
contiene l'indirizzo completo del destinatario. Ovviamente, anche le prime
istruzioni del processo che implementa il server richiedono al sistema un
socket e gli attribuiscono poi, con un'operazione di binding, il nome cui gli
altri processi faranno riferimento nella chiamata. Il nome ha l'usuale formato <indirizzo_nodo.port>. Va notato che, come si è detto sopra, queste
informazioni non sono direttamente note al processo che esegue il binding:
questi si limita infatti a 'lasciare in biancò gli entry della struttura che
denomina il socket , mettendovi dei valori fittizi (wildcard). Quando il
processo passa la struttura come argomento di una chiamata bind(),
Unix si occuperà di inserirvi i valori opportuni. Questi valori possono essere
però letti dal processo attraverso una semplice chiamata alla funzione getsockname().
Dopo aver eseguito l'operazione di binding, il server inizia un loop infinito (busy
waiting) durante il quale accetta la connessione con numerosi client. Ciò
viene fatto anzitutto eseguendo una chiamata listen() che segnala al
sistema la disponibilità del processo alla connessione ad un circuito virtuale.
Poi si esegue il corpo vero e proprio del loop senza fine, che è controllato dalla
condizione 'do {.....} while(TRUE)'. Si osservi che il codice del programma che
implementa il server gestisce implicitamente anche il segnale di 'occupato',
visto che la connessione è possibile ad un solo processo per volta. Il sistema
operativo agisce da centralino in modo trasparente ai processi coinvolti.
Quando un processo client trova la linea libera, la chiamata di accept() effettuata
dal server restituisce il socket su cui vi è stata la richiesta di connessione.
Ciò provoca l'entrata del server in un ulteriore ciclo di lettura che contiene
l'usuale chiamata read() per la lettura da file ed è controllato dalla
condizione di fine messaggio ( equivalente alla condizione di EOF in cui read()
riporta il valore 0). Come si vede, il processo server del nostro esempio si
limita a stampare sul video i messaggi ricevuti: è però possibile immaginare
uno schema di funzionamento in cui i messaggi contengano vere e proprie
richieste di servizio, ad esempio comandi FTP. Di seguito riportiamo il listato
del server.
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <netdb.h>
#include <stdio.h>
#define TRUE 1
/* Questo programma crea uno stream socket, gli attribuisce
un nome e poi inizia un loop infinito. Ad ogni
iterazione del ciclo accetta una connessione con un
processo client remoto e stampa i messaggi ricevuti. Al
termine della comunicazione, o se questa viene
interrotta, accetta una nuova connessione.*/
main()
{
int sock,length;
struct sockaddr_in name;
char buf[1024];
int rval,i;
int msgsock;
sock = socket(AF_INET,SOCK_STREAM,0);
/* Crea il socket */
if (sock<0)
{
perror('Errore di apertura dello stream socket');
exit(0);
}
name.sin_family = AF_INET;
name.sin_addr.s_addr = INADDR_ANY;
name.sin_port = 0;
/* Attribuisce il nome al socket utilizzando i wildcard */
if (bind(sock,&server,sizeof(server)))
{
perror('Errore di attribuzione del nome al socket');
}
length = sizeof(server);
if (getsockname(sock,&server,&length))
{
/* Trova il numero di port assegnato al processo e lo stampa*/
perror('Errore nella richiesta del nome del socket');
exit(0);
}
printf('il numero del port è,"%d",ntohs(server.sin_port));
listen(sock,5);
/* Inizia le connessioni */
do
{
msgsock = accept(sock,0,0);
do
{
for (i=0;i<1024;i++)
buf[i] = ' ';
/* Inizializza il buffer */
if ((rval=read(msgsock,buf,1024)) <0)
perror('Errore di lettura dello stream');
i = 0;
if (rval==0) printf("Fine connessione");
else printf("%s",buf);
}
while (rval!=0);
close(msgsock);
}
while (TRUE);
}
Un’evoluzione di questo listato può costituire, ad esempio, il nucleo di un semplice server FTP. Per gestire simultaneamente più richieste, il server FTP crea una nuova istanza del processo per ogni nuova richiesta ricevuta. Di solito vi è un solo processo principale, con il suo numero di port "well-known", a cui sono passate tutte le nuove richieste ed è questo a creare un nuovo processo per ogli connessione. Questo processo di controllo esegue le varie funzioni di controllo associate alla sessione, tra cui la procedura di collegamento (con password) e la definizione dei tipi di struttura e di dati associati al file o ai file da trasferire; spesso, stabilisce anche se si deve usare la compressione e, in caso affermativo, il tipo di algoritmo di compressione. Uno schema più complesso può richiedere la creazione di più processi per sessione creando un altro processo per gestire i trasferimenti di dati associati alla sessione. In questi casi, una sola sessione del protocollo FTP implica due connessioni di trasporto, una per scambiare i messaggi di controllo e l'altra per trasferire i contenuti dei file. Naturalmente tutto questo è interamente trasparente all'utente.
Il meccanismo di chiamata di procedura remota
Un altro schema efficace perchè
un'applicazione possa richiedere l'esecuzione di un servizio remoto consiste
nell'estensione ad un sistema di rete del costrutto di chiamata di procedura.
Questo schema di comunicazione può essere descritto in prima approssimazione
come segue. Quando un'applicazione desidera richiedere un servizio remoto si
limita ad effettuare una normale chiamata ad una procedura locale detta stub
specificando gli argomenti necessari.Lo stub si incarica di porre gli argomenti
forniti dal chiamante in un formato adatto per la comunicazione sulla rete (operazione
spesso detta marshalling ) e ad inoltrarli all'elaboratore remoto.
Dall'altra parte lo stub locale messi gli argomenti in un formato opportuno ed
identificatone il tipo (operazione spesso chiamata unmarshalling), li
passa alla procedura locale in grado di svolgere il servizio richiesto. Si
osservi che la chiamata di procedura remota viene in tal modo risolta in due
chiamate di procedure locali nascondendo agli occhi sia del chiamante sia del
chiamato tutte le caratteristiche del sistema di comunicazione utilizzato. Se
vi sono dei valori di ritorno, sarà lo stub di partenza a restituirli
all'applicazione chiamante. Lo schema di chiamata di procedura remota è
descritto in figura
La chiamata di procedura remota
Esattamente come avviene nel caso di una procedura locale, RPC è un costrutto bloccante nel senso che il programma chiamante resterà sospeso fino a che la procedura richiesta non è stata completata. Lo schema così delineato, apparentemente semplice ed efficace, presenta però numerosi problemi. Il più evidente di questi è il fatto che lo schema di chiamata remoto non può recuperare completamente la semantica di quello locale, se non altro per quanto riguarda il passaggio degli argomenti per indirizzo. Infatti, a differenza di quanto accade nel caso locale, con RPC il programma chiamante e la procedura chiamata non condividono lo stesso spazio di indirizzamento. Le chiamate per indirizzo possono solo essere simulate trasferendo le variabili così referenziate avanti e indietro lungo la rete. Come è intuibile questa soluzione non è affatto soddisfacente nel caso di strutture di dati dinamiche. Un altro problema di questo genere è la corrispondenza tra il tipo atteso del parametro di ritorno e quello effettivamente restituito. Più in generale, vi possono essere dei problemi per l'esecuzione di quelle chiamate di procedura remota che hanno come parametri delle variabili il cui tipo è stato definito dal programmatore, come una struttura C, soprattutto nel caso di ambienti di sviluppo che utilizzano più di un linguaggio di programmazione. Anche se, come vedremo, il programmatore può specificare i tipi dei parametri che utilizzerà servendosi di un apposito linguaggio di definizione (NIDL), pure la corrispondenza tra i tipi di dati astratti definibili nel linguaggio di programmazione adottato da chi scrive il programma e quelli disponibili nel linguaggio di definizione può non essere completa, con ovvie implicazioni di tipo semantico.
Un problema meno evidente, ma
concettualmente affine al precedente, è quello della corrispondenza tra il nome
simbolico con cui il chiamante designa la procedura remota che desidera
attivare e la macchina remota su cui si trova il codice che effettivamente la
esegue (problema del binding). In concreto, questo significa che lo stub
deve costruire, partendo dal nome simbolico del servizio, l'indirizzo di rete
dell'host che lo fornisce e l'identificatore che sull'host remoto individua
proprio quel servizio tra i tanti disponibili. La problematica del binding può
venire affrontata stabilendo, all'atto della compilazione di un programma , un
legame statico (static binding) tra i nomi simbolici utilizzati e le
procedure remote corrispondenti. Un'altra possibilità (implicit binding)
è quella di effettuare il binding dinamicamente , ma una volta per tutte
all'inizio dell' esecuzione del programma. Taluni schemi RPC offrono
addirittura la possibilità per il programma di eseguire il binding al momento
della chiamata di procedura remota attribuendo opportuni valori ad un parametro
utilizzato per designare le procedure (explicit binding).
Lo static binding viene usato quasi esclusivamente per i cosiddetti well
known services, i servizi di rete come FTP e Telnet che hanno un numero di
port prefissato e universalmente noto. Per realizzare gli altri tipi di binding
è invece indispensabile ricorrere ad un servizio informativo standard
disponibile su ciascun host e dotato di identificatore convenzionale. Ad
esempio, nello schema RPC della SUN in cui gli identificatori dei servizi sono
dei numeri interi detti port, il servizio informativo è detto port
mapper e si trova al port 111.In generale a questo numero identificativo
del servizio ne è associato un altro che ne specifica la versione.
La consistenza delle informazioni note al port mapper è garantita dal fatto che
all'attivazione di un servizio, il processo che lo realizza esegue un'apposita
procedura per comunicare al port mapper il proprio identificativo. La scelta
tra binding implicito ed esplicito è spesso dettata dalla natura del servizio
richiesto. Ad esempio, sarebbe inutilmente dispendioso utilizzare l'explicit
binding per eseguire una serie di richieste di I/O su un unico file remoto,
mentre sarebbe impossibile utilizzare l'implicit binding per accedere a molti
file diversi su un file system distribuito tipo NFS. Va comunque tenuto
presente che un problema per l'utilizzo dell'implicit binding viene dal fatto
che la corrispondenza tra nomi simbolici ed identificativi di servizio non
viene mantenuta quando il server viene reinizializzato (procedura di boot del
sistema operativo locale al nodo). Per risolvere questo problema ( across
boot consistency ) lo schema RPC SUN prevede che i server mantengano in una
variabile statica il numero delle loro reinizalizzazioni. L'unità client che
richiede un servizio utilizza questo numero per eseguire automaticamente, se
necessario, un nuovo binding. L'utilizzo del binding esplicito consente
addirittura, in linea di principio, di scegliere al momento di esecuzione della
chiamata anche il protocollo di rete da utilizzare, ovviamente se ve ne è più
di uno disponibile.
La conversione dei dati
Un fattore importante
nell'implementazione degli schemi RPC è il formato con cui i dati vengono
inviati sulla rete e del corrispondente carico computazionale delegato agli stub
per le operazioni di conversione. Si tratta di un problema particolarmente
delicato quando la rete presenta un'elevata eterogeneità, coinvolgendo macchine
di tipo molto diverso tra di loro. Senza considerare le diverse forme con cui
vengono rappresentati i numeri reali o i caratteri nei vari sistemi, si noti
che persino per i valori interi su 16 bit è sempre necessario precisare se sono
rappresentati con il byte più significativo per primo o viceversa, poichè la
situazione è diversa da macchina a macchina. Gli approcci utilizzati per
risolvere questo problema sono essenzialmente due: stabilire un formato
standard per la comunicazione (come il formato XDR della SUN) oppure
adottare un approccio del tipo receiver makes it right come quello
scelto da HP, secondo cui ogni macchina invia sulla rete i dati nel proprio
formato interno. E' ovvio che entrambe le possibilità comportano dei problemi
che le implementazioni concrete devono risolvere. Gli svantaggi derivanti dalla
prima possibilità sono legati in ultima analisi alla eventualità di eseguire
conversioni inutili come nel caso dello scambio di dati tra macchine con la
stessa rappresentazione interna.
La seconda possibilità impone invece ad ogni nodo la conoscenza dei formati
interni adottati da tutti gli altri nodi per poter effettuare le necessarie
conversioni. Come abbiamo visto, tutto il carico del lavoro di conversione
ricade sulle procedure locali dette stub. Infatti su ciascun nodo in grado di
richiedere un servizio remoto è definita una interfaccia che specifica il tipo
e il numero degli argomenti con cui chiamare le procedure remote. Analogamente
su ciascun nodo in grado di fornire un servizio sono definiti il numero e il
tipo di argomenti con cui deve essere invocate la richiesta. Tra i principali compiti
degli stub vi è quello di determinare la corrispondenza tra i tipi di dati
relativi agli argomenti in arrivo ed i tipi di dati disponibili localmente.
Nella maggioranza dei sistemi il codice degli stub può essere generato
automaticamente partendo dalla descrizione formale delle procedure che
costituiscono l'interfaccia e dei tipi di dati accettati da esse. Queste
descrizioni vengono fornite utilizzando linguaggi detti NIDL (Network Interface
Definition Language) la cui sintassi è spesso ispirata a quella
dei più comuni linguaggi di programmazione come il C e il PASCAL. Va però
notato che questi linguaggi sono di tipo puramente dichiarativo e non
comprendono costrutti eseguibili poichè si limitano a definire i tipi di dati
accettati come parametri dalle procedure remote. Ad esempio, nel linguaggio
NIDL fornito da HP la definizione di un'interfaccia avrà un aspetto di questo
tipo:
1 [uid (0x1496823a,0x8c0001d21)] interface vector {
2 import /user/include/ldl/rpc.ldl;
3 void vector_$sub (
4 [binding] rpc_$handle_t h,
5 [in] float a[ ],
6 [in] float b[ ],
7 [out] float c[ ],
8 );
9 float vector_$add (...);
10 . . . . . . }
Per analizzare sommariamente questo
listato, la cui sintassi è chiaramente ispirata al linguaggio di programmazione
C, si noti anzitutto che le parole in grassetto sono parole chiave del
linguaggio NIDL HP. I numeri di riga sono fittizi e sono stati aggiunti
unicamente per comodità di descrizione. La riga 1 comprende un numero (detto uid)
che identifica univocamente l'interfaccia. Per la generazione di questo numero
viene fornita una routine che evita le duplicazioni. A questo numero è poi
associato il nome simbolico vector. Come si vede lo uid è simile al numero
identificativo del programma dello schema SUN, ma a differenza di quanto accade
in quel caso esso viene ricalcolato esplicitamente ad ogni nuova versione del
codice che realizza il servizio. La riga 2 provvede ad includere un file in cui
sono definiti i tipi di dati utilizzati dall'interfaccia. Va notato che a
differenza della direttiva #include del preprocessore C, import non realizza
un'inclusione testuale, ma rende ugualmente disponibili le definizioni di tipo.
Dalla riga 3 alla riga 8 viene definita una routine remota chiamata vector_$sub
i cui parametri di ingresso sono definiti nelle righe 4,5,6,7. In questo caso i
parametri a,b,c sono variabili scalari, ma la sintassi di questo
NIDL permette anche la dichiarazione di parametri vettoriali, strutturati, o di
tipo puntatore.
Va però notato che non è consentito l'utilizzo di puntatori a puntatori, o di
puntatori all'interno di strutture complesse. In questo modo si evita la
necessità di dover trasferire strutture dati dinamiche sulla rete per simulare
il meccanismo di chiamata per indirizzo. La riga 4 definisce un parametro h di
tipo handle_t: un tipo di dati definito nel file rpc.ldl
il cui pathname è fornito alla riga 2. Come avviene in questo caso, tutte le
definizioni di procedura dell'interfaccia devono avere come prima istruzione la
dichiarazione di uno handle, che viene utilizzato per determinare il
server cui la chiamata remota è indirizzata. NIDL fornisce un tipo standard di
handle il cui nome è handle_t. I client possono richiedere ad una apposita
procedura uno handle valido anche in fase di esecuzione fornendo come argomenti
un uid e un indirizzo di rete valido , e realizzando così un binding
esplicito. Il binding implicito potrà essere realizzato semplicemente
dichiarando nell'interfaccia che un'unica variabile globale, il cui valore è
assegnato all'inizio dell'esecuzione, va usata come handle per tutte le
procedure. Tornando al nostro esempio, osserviamo che la procedura vector_$sub
è dichiarata di tipo void. Esattamente come accade nel linguaggio C, una
funzione void non ha parametri di ritorno. Nella riga 7 però
uno dei parametri della procedura è contrassegnato come out.
Ciò avverte lo stub che, attraverso la simulazione di una chiamata per
indirizzo, questa variabile potrà contenere un valore di ritorno. In modo del
tutto equivalente nella riga successiva si dichiara una procedura di tipo float
che ritorna un valore di questo tipo.I parametri di questa procedura sono
omessi nel nostro listato. Ovviamente un'interfaccia reale comprenderà un ben
più elevato numero di funzioni.
La semantica della chiamata di procedura remota
Come si è visto lo scopo principale dei
meccanismi RPC è rendere la semantica della chiamata delle procedure remote più
simile possibile a quella delle procedure locali. Ovviamente però un ambiente
di rete presenta tali specificità da rendere impossibile una completa identità
tra i due costrutti. La caratteristica più evidente che distingue la chiamata
remota da quella locale è la possibilità che la procedura invocata non possa
venire eseguita per un malfunzionamento della macchina remota. Escludendo il caso
di un vero e proprio guasto qui supponiamo che la rete sia soggetta in modo
casuale a malfunzionamenti temporanei. Dal punto di vista del progettista dello
schema RPC occorre decidere come estendere la semantica della chiamata di
procedura per far fronte a questa circostanza. Una scelta può essere quella di
iterare la chiamata (in modo del tutto analogo alla ritrasmissione di un
pacchetto di dati dopo un time out ) fino a quando la procedura remota non
risponde. E' ovvio che ciò può portare alla ripetizione indesiderata della
esecuzione della procedura, benchè garantisca che verrà eseguita almeno una
volta (ammesso che il malfunzionamento non sia definitivo...). La semantica
così estesa viene chiamata at least once . La scelta duale è quella di
non effettuare alcuna iterazione della richiesta, ottenendo una semantica
chiamata at most once , o semantica zero-or-one . Chiaramente il
chiamante potrà leggere da un parametro di ritorno se la chiamata ha avuto
successo o meno. Al fine di completare il quadro espositivo va soggiunto che
per le chiamate locali si parla talvolta di semantica exactly once.
Dovrebbe risultare poi chiaro che la scelta tra l'una e l'altra possibilità
dipende largamente dal tipo di azione che la procedura invocata deve compiere.
Se ad esempio il servizio richiesto è la semplice consultazione di una tabella,
allora la sua ripetizione non avrà effetti di rilievo. Se invece si tratta di
un accredito su un conto corrente bancario, la semantica at most once è
senz'altro preferibile ... almeno dal punto di vista della banca. Sulla base di
questi esempi si fa una distinzione tra le procedure idempotenti che
possono essere eseguite un numero arbitrario di volte senza che ciò alteri la
correttezza dell'elaborazione, e non idempotenti per cui è indispensabile
che vengano eseguite al più una volta. Da questo punto di vista la situazione
ideale (adottata ad esempio da HP) è quella in cui il meccanismo RPC consente
al programmatore di fare esplicita distinzione tra i due tipi di procedure
offrendogli la scelta tra le due semantiche possibili.
Java e la programmazione in Rete
Anche se posso,no comunicare a distanza, i processi visti nei paragrafi precedenti sono stabilmente collocati su due macchine della Rete. Come abbiamo visto in precedenza, il linguaggio Java ha introdotto la tecnica del codice mobile. Un server WWW può inviare al browser un programma (nella terminologia di Java, un applet) insieme con dei dati non-HTML da elaborare. Il codice mobile è inviato in un formato di alto livello (il cosiddetto bytecode) e viene interpretato presso il browser, il che lo rende indipendente dalla macchina che lo riceve.
I back-channel
Il codice mobile Java può interagire con altre applicazioni presenti sulla Rete grazie alla tecnica dei back-channel Vediamo il caso più semplice: grazie alla libreria di comunicazione via TCP/IP (la socket library ) disponibile anche in Java, un applet inviato da un certo Web server può aprire un canale di comunicazione a basso livello con un altro programma server, purchè sia residente sulla stessa macchina su cui si trova il Web server che lo ha inviato.

Un back-channel a livello socket
Un back-channel a livello così basso come quello dei socket pone però tutto il peso dell’identificazione del server e dell’invocazione dei suoi servizi sulle spalle dell’applicazione, favorendo l’adozione di soluzioni diverse e incompatibili. Per questo, i progettisti di Java hanno messo a punto uno standard di invocazione remota a livello di linguaggio di programmazione, il Remote Method Invocation. Questo standard consente l’integrazione di applicazioni Java in ambiente omogeneo, cioè in parole povere consente a un oggetto Java di un applet di invocare un metodo di un altro oggetto Java che fa parte di una applicazione stand-alone posta sulla macchina che ospita il Web server da cui l’applet proviene.

un back-channel a livello RMI in ambiente Java omogeneo
Questa tecnica però non è del tutto soddisfacente, perchè i servizi remoti che fanno parte del sistema informativo aziendale non sono certo stati realizzati come applicazioni Java stand-alone; si tratta invece di moduli scritti in linguaggi tradizionali di vario tipo, che girano su piattaforme hardware eterogenee. Mettere gli applet in grado di "parlare" con oggetti remoti di qualsiasi tipo farebbe sì che Java e il server Web diventassero un prezioso strumento di integrazione e che il browser Web (munito di opportuni helper) potesse proporsi come l’unico strumento (grafico e multimediale, il che non guasta) per l’accesso all'intero sistema informativo dell'azienda.
Java e CORBA
L’esperanto che permette il colloquio tra applet e servizi remoti eterogeneei esiste già: è la tecnologia degli oggetti distribuiti, o CORBA (Common Request Broker Architecture) di cui abbiamo parlato nei tutorial precedenti
Infatti, uno degli aspetti chiave del modello CORBA è che il modulo client e quello server sono isolati da un’interfaccia che consente al client di richiedere i servizi del server senza conoscerne i dettagli implementativi (linguaggio di programmazione, piattaforma hardware, ecc.).
Ciò avviene tramite la presenza presso il client di oggetti fittizi detti stub, che agiscono come rappresentanti dei server remoti; i riferimenti agli stub sono risolti in indirizzi di rete tramite un meccanismo di invocazione remota.
Dal lato server, lo stesso compito è affidato ai cosiddetti skeleton che inoltrano agli oggetti server i parametri delle invocazioni remote provenienti dai client eseguendo le eventuali conversioni e ritornano i risultati delle elaborazioni.
Questa tecnica viene spesso detta static linking, anche se il riferimento remoto viene risolto al momento dell’esecuzione, perchè coinvolge un numero prefissato di server identificati tramite i loro stub locali.
L’interfaccia client-server è definita dal programmatore usando il linguaggio IDL (Interface Description Language), un evoluzione del NIDL visto nel paragrafo precedente.
Questo linguaggio esiste in varie versioni, orientate a chi utilizza come linguaggio di sviluppo C, C++, Smalltalk, Ada e Java.
Un ambiente di sviluppo ed esecutivo CORBA ha quindi tre componenti principali.
In primo luogo, c’è il compilatore IDL, che consente di generare gli stub e skeleton per realizzare lo static linking tra oggetti client e server (sul supporto per l’invocazione dinamica torneremo nel seguito).
Poi, c’è il supporto runtime o ORB broker che deve affrontare i problemi di portabilità e scalabilità che risparmia alle applicazioni.
Infine, c’è il Naming Service, che realizza un repository di riferimenti che i client possono interrogare per identificare un oggetto server.
La Dynamic Invocation Interface (DII)
Lo "static linking" prevede che il client conosca al momento della compilazione l’interfaccia IDL a cui rivolgersi per avere un servizio. CORBA prevede però anche una Dynamic Invocation Interface (DII) che consente ai client di costruire le loro richieste di servizi al momento dell’esecuzione.
Si tratta di una caratteristica importante, poichè non vi è dubbio che in futuro gli utenti accederanno dinamicamente a oggetti distribuiti su Internet dalle loro stazioni di lavoro.
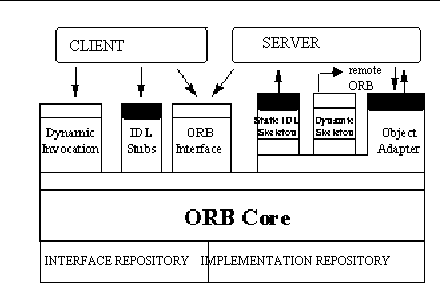
I meccanismi di invocazione remota di CORBA
Il DII consente il completo disaccoppiamento tra server e client perchè la scelta del server è fatta al run time.
Per consentire l’invocazione dinamica, ogni Object Request Broker (ORB in Fig.3) deve memorizzare le definizioni delle interfacce IDL dei server a lui noti in un interface repository (IR). Per ogni server, il Broker detiene un riferimento valido (Interoperable Object Reference - IOR).
Si noti che l’identificazione del server cercato sulla base delle richieste del client non viene fatta tramite IR.
L’ambiente esecutivo CORBA comprende un Trader Service; che permette di identificare il server cercato sulla base di offer properties, cioè informazioni funzionali e non-funzionali sui server disponibili.
Un’invocazione dinamica CORBA consta di quattro fasi:
1 Identificare l’oggetto che offre il servizio desiderato
2 Recuperarne l’interfaccia e uno IOR valido
3 Construire l’invocazione sulla base dei dati recuperati
4 Eseguire l’invocazione e ricevere i risultati.
Essendo frutto di un lungo lavoro di messa a punto, lo standard CORBA è robusto, scalabile e prevede già oggi l'integrazione delle applicazioni distribuite con i database ad oggetti, considerati da molti la tecnologia più promettente per la gestione dei dati nel prossimo futuro. L’unico vero concorrente è l'alternativa proprietaria rappresentata dalla tecnologia ActiveX di Microsoft.
L’integrazione Java-CORBA
Come abbiamo visto, la tecnica RMI di Java non permette l’inserimento di client Java in sistemi eterogenei complessi scritti in una varietà di linguaggi.
La combinazione di CORBA e Java è una naturale risposta a questa esigenza. L’integrazione del linguaggio Java con lo standard CORBA permette di creare dei server Web che agiscono come "juke-box" di componenti mobili scaricabili, in grado di accedere a server condivisi su una Intranet o sull’intera Rete.
La figura che segue illustra un tipico scenario WWW - l’utente finale naviga la Rete con un browser fino a una URL che identifica il "juke box" Java, ovvero una pagina HTML contenente una serie di collegamenti ad altre pagine, ciascuna delle quali ospita un applet tag che referenzia un applet Java.
A questo punto, l’utente ne sceglie una e
(1) Il browser scarica e interpreta il codice HTML
(2) Riconosce l’applet tag, e richiede al suo interprete Java di scaricare ed eseguire le relative classi top-level Java. Nel farlo, l’interprete Java scarica automaticamente gli stub IDL necessari per abilitare l’applet alla comunicazione CORBA. Ciò avviene in modo trasparente all’utente, attraverso il ClassLoader standard.
(3) A questo punto, l’applet può comunicare con il server CORBA posto sul web-server con un canale bi-direzionale - gli oggetti residenti nel browser possono invocare gli oggetti sul server e viceversa (callback).
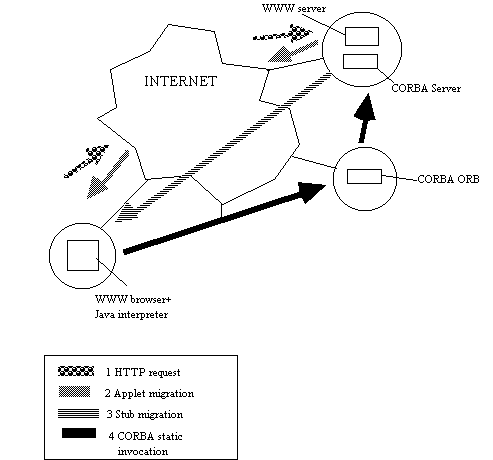
Un back-channel da Java verso un server CORBA con static linking
La figura che segue illustra invece l’invocazione dinamica di un servizio remoto fatta tramite il servizio CORBA detto Trader, il cui compito è aiutare il client a scegliere il servizio desiderato.
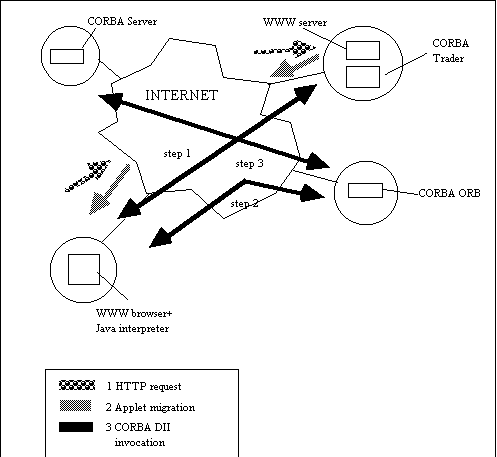
Fig. 5 Un back-channel da Java verso un server CORBA via DII
La sicurezza
Nella maggior parte delle installazioni reali non vi è una separazione netta tra Intranet e Internet, poiché a fianco dei Web server privati usati per l’integrazione del sistema informativo aziendale esistono dei server "pubblici", collegati ad Internet, per la gestione di un servizio commerciale o la comunicazione con la clientela.
Nella figura che segue viene schematizzata una soluzione per l’interfaccia Intranet/Internet.
Come si vede nella parte superiore della figura, molte organizzazioni mantengono più server Web su Internet in mirroring.
Questa tecnica fa in modo che i server replichino in posizioni diverse gli stessi contenuti per rendere più uniforme la distribuzione del carico.
Gli utenti di Internet possono così accedere alle informazioni messe a disposizione dall’impresa.
Parallelamente, i dipendenti sono collegati alla Intranet aziendale ed utilizzano il server interno come interfaccia verso il sistema informativo; inoltre, tramite una connessione Internet/Intranet possono accedere all’esterno.
Visto che il Web server pubblico è collegato a Internet c’è la possibilità che gli utenti esterni guadagnino l’accesso indebito ai server CORBA e quindi al sistema informativo aziendale tramite il Web stesso.
Come sappiamo, i modelli di sicurezza attualmente più usat come SURF prevedono l’uso di un firewall, in modo che tutto il traffico di rete debba passare attraverso un unico punto di controllo
Tipicamente, una invocazione remota proveniente da un applet in esecuzione presso un browser (client), e diretta a un server CORBA esterno su Internet attraversa due firewall.
Il primo, detto client-side firewall controllerà il traffico TCP/IP che va dalla rete del client verso l’esterno, mentre l’altro, detto server-side firewall protegge il server dalle intrusioni esterne.
La sicurezza delle invocazioni remote su Internet si basa sul fatto che queste usino una porta prefissata (la solita well-known port). Ciò si ottiene tramite un CORBA proxy che (come i normali proxy HTTP, SMTP etc.) userà un suo well-known port. Il proxy è configurabile per consentire l’accesso ai server CORBA che si trovano dietro il server-side firewall sulla base dei criteri decisi dall’amministratore di rete. Il proxy gira su un computer dedicato allo scopo, il bastion host e permette pieno controllo sull’accesso ai server CORBA da client remoti via Internet. Tra i suoi compiti c’è anche la traduzione degli IOR dei server per portarli in un formato distribuibile su Internet, in cui gli indirizzi di rete siano quelli del proxy. Il contenuto delle invocazioni CORBA fatte dagli applet può essere crittografato in modo trasparente, ad esempio usando lo standard SSL.